The Job market is a fiercely competitive place and getting an edge in your search can mean the difference between success and failure, so many tech-savvy Job seekers turn to web-scraping Job listings to get ahead of the competition, enabling them to see new relevant Jobs as soon as they hit the market.
Scraping Job listings can be an invaluable tool for finding your next role and in this tutorial, we’ll teach you how to use our AI-powered Web Scraping API to harvest Job vacancies from any Job board with ease.
Why Trust Our Web Scraping Expertise? Insights from 1M+ API Calls
If you've ever tried web scraping, you know the struggle is real. And job postings? That's a whole other level...The late nights wrestling with Python and Selenium scripts? Or that sinking feeling when your carefully crafted BeautifulSoup + Requests parser suddenly starts returning gibberish because the site updated their HTML structure? We've been there. In fact, I started there.
Now, scraping job postings presents unique challenges that demand more robust solutions. Dynamic content loading, sophisticated anti-bot measures, and constantly changing page structures kept us constantly on our toes. Those frustrations shaped our journey and led us to build something different.
ScrapingBee AI web scraping API doesn't just scrape job postings - it understands them. No more brittle CSS selectors or XPath expressions that break with every site update. In plain English, you simply tell our AI-powered API what job data you need, and it handles the rest.
What This Guide Will Cover (And What You'll Learn)
Let's break down exactly what you'll gain from this guide:
- Practical Implementation: Step-by-step process for scraping job posting boards using ScrapingBee AI Web Scraping API and SERP API with Python
- Scale Strategies: How to handle large-scale data collection without getting blocked
- Data Processing: Techniques for cleaning and structuring job posting data
- Real Code: Working examples you can adapt to your specific needs
- Best Practices: Hard-learned lessons from processing tons of job listings
New to web scraping or Python? No worries! If you want to get started, check out our beginner's guide to web scraping first. And if you want to brush up on Python scraping basics, our comprehensive Python web scraping tutorial has got you covered. They're great companions to this guide!
How to Scrape Job Postings in 2026: Step-by-Step Tutorial
Scraping Job Postings With ScrapingBee AI Web Scraping API: 4 Steps
Step 1: Setting Up Your Environment
Ready to transform how you collect job market data? Let's set up your environment and get it running in 5 minutes. Trust me – getting started is the hardest part of any scraping project, so we'll make this super smooth.
Creating Your ScrapingBee Account & API Access
First things first – you'll need a ScrapingBee account. Head over to our signup page, and you'll be up and running in seconds. The best part? We're giving you 1,000 free API calls to test things out. No credit card needed, just pure scraping goodness.
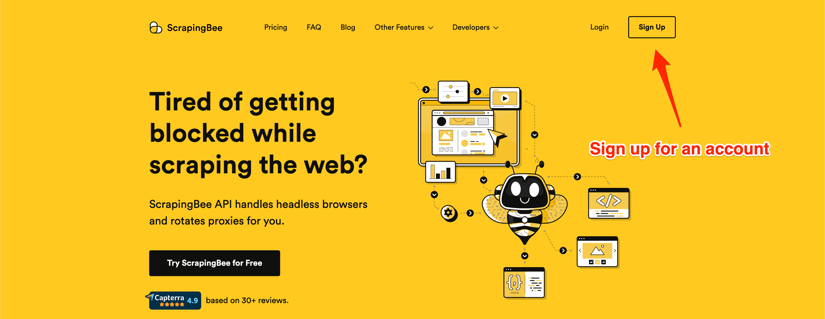
I love seeing scrapers' faces light up when they realize they can start experimenting immediately without any upfront commitment. Those 1,000 calls are more than enough to follow along with this guide and build your first job scraping system.
Installing Python
If Python isn't already your trusty companion, head over to Python's official website, download the latest stable version, and follow the setup wizard.
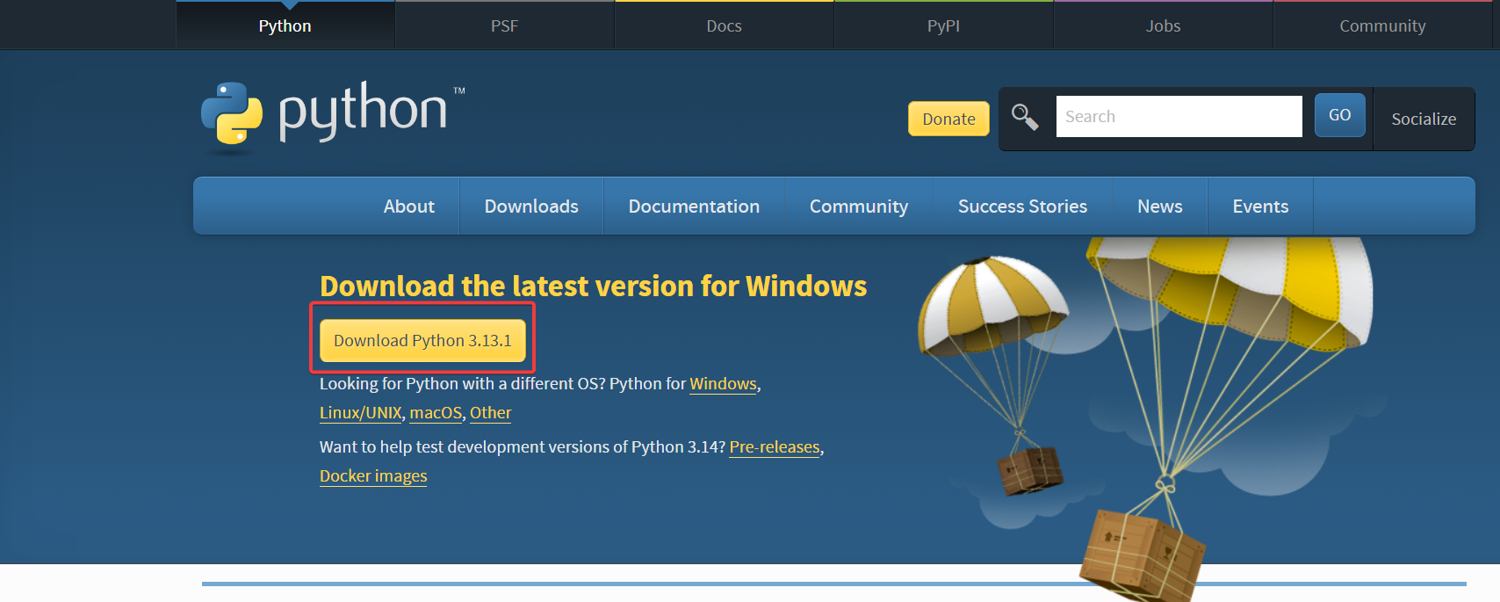
Pro Tip: Nothing fancy here – just make sure to check that "Add Python to PATH" box during installation. Been there, forgotten that, and spent an hour wondering why commands weren't working!
Setting Up a Virtual Environment
Before we jump into the code, let's talk virtual environments. Think of them as your project's private workspace – no package conflicts, no version mismatches, just clean, isolated development.
python -m venv jobscraper
source jobscraper/bin/activate # On Windows: jobscraper\Scripts\activate
Pro Tip: After setting up hundreds of scraping projects, I've learned that clear naming is your future self's best friend. Name your virtual environment something that instantly clicks – like "jobs_scraper" or "postings_data." Trust me, you'll thank yourself later.
Installing ScrapingBee Python SDK
After installing Python, let's install the ScrapingBee Python SDK. Our Python SDK handles all the heavy lifting for you - authentication, request formatting, and response parsing, so you can focus on the data you actually want to extract.
pip install scrapingbee
Pro Tip: While a simple
pip installgets you started, I'd recommend checking out our Python SDK tutorials later. Not because I wrote them (okay, maybe a little), but because it's packed with tutorials and time-saving tricks.
Step 2: Planning Your Job Postings Collection
Mapping Popular Job Board Structures
Now, let's talk strategy. One thing I've learned is that the secret to successful scraping isn't just about the code – it's about understanding your targets and their landscape. Job boards come in three main flavors:
| Job Board Type | Job Posting Characteristics | Technical Challenges |
|---|---|---|
| Traditional Job Boards (Indeed, foundit, SimplyHired) | • Search-based navigation • Paginated results • Structured job cards | • Rate limiting on search pages • Dynamic loading of job postings • Session-based access controls |
| Company Career Pages (Workday, Greenhouse, Lever) | • Custom implementations with ATS platforms • Inconsistent data structures • JavaScript-heavy frameworks | • Framework-specific handling • Render JavaScript content • Handle inconsistent layouts |
| Niche Industry Boards (Wellfound, Stack Overflow, Dribbble) | • Industry-specific fields • Structured data formats • Less aggressive anti-bot measures | • Limited API documentation • Unique field mappings • Specialized authentication requirements |
Setting Realistic Collection Goals
Think about what you actually need. Here's a framework some of our clients use:
1. Update Frequency:
- Daily updates for competitive analysis
- Weekly snapshots for market trends
- Real-time monitoring for specific positions
2. Data Depth Required:
- Basic details (title, company, location)
- Full descriptions and requirements
- Salary information and benefits
- Application deadlines
Pro Tip: Pay special attention to posting dates and salary information. In my experience, these are often the trickiest fields to extract consistently across different job boards.
Step 3: Implementing AI-Powered Job Scraping
Scraping Job Postings With ScrapingBee AI Web Scraping API
Your first time with APIs? Don't worry – despite the name, our API for Dummies guide is actually a friendly introduction that breaks down APIs into bite-sized concepts. While we'll explain everything as we go in this tutorial, it's a great companion if you want to dive deeper into API basics.
Remember how we talked about job postings being tricky to scrape? Let's put ScrapingBee AI-powered web scraping API to work.

Scraping SimplyHired Job Postings
For this tutorial, we'll use SimplyHired as our example – it's perfect for learning since their job listings load directly from the URL (like https://www.simplyhired.com/search?q=python+developer&l=USA). No fancy JavaScript gymnastics needed!
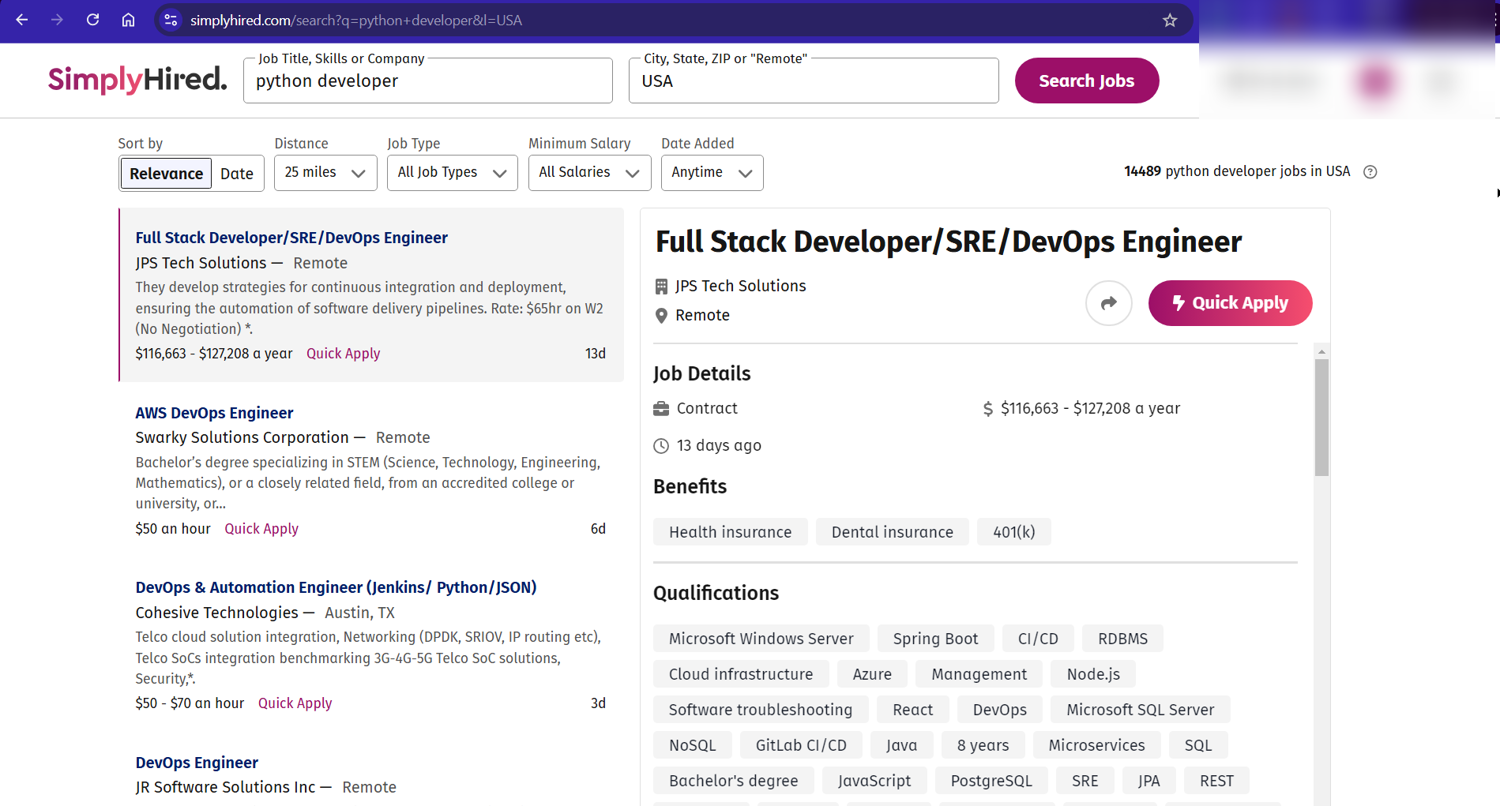
Looking for specific job sites? While we're using SimplyHired in this guide, we've also got a detailed tutorial on how to extract job listings from Indeed. It even shows you how to do it without coding! Perfect if you're specifically targeting Indeed or prefer no-code solutions.
Setting Up Our Scraper
First things first, let's get our Python script ready. I'll show you how to scrape job postings without wrestling with complex selectors or page structures:
# Import Libraries
from scrapingbee import ScrapingBeeClient
import json
# Initialize the client
client = ScrapingBeeClient(api_key='YOUR_API_KEY')
Here's where the magic happens. Instead of hunting for CSS selectors, we'll tell the ScrapingBee AI-powered API precisely what data we want, in plain English:
extraction_rules = {
"job_title": {
"type": "string",
"description": "The full title of the job position"
},
"company": {
"type": "string",
"description": "Name of the hiring company"
},
"location": {
"type": "string",
"description": "Job location, including remote options"
},
"salary_range": {
"type": "string",
"description": "Salary range if provided"
},
"required_skills": {
"type": "array",
"description": "List of required skills and technologies"
},
"posting_date": {
"type": "string",
"description": "When the job was posted"
}
}
Now we can make our request:
response = client.get(
'https://www.simplyhired.com/search?q=python+developer&l=USA',
params={
'ai_query': 'Extract all details about this job posting',
'ai_extract_rules': json.dumps(extraction_rules),
'render_js': True # Important for JavaScript-heavy job boards
}
)
Pro Tip: SimplyHired's URL structure makes it ideal for our first scraping project. But heads up – not all job boards play this nice. Some sites load their listings through JavaScript or require user interaction. For those tricky cases, check out our JavaScript Scenario – it's your secret weapon for handling dynamic content loading and user interactions.
While SimplyHired's structure is straightforward, we still include render_js=True. Why? It's a good habit to save you headaches when you move to more complex job boards. Trust me, I've learned this the hard way!
Also, notice how we use ai_extract_rules to define the structure we want. This ensures consistent data across different job boards using similar approach, even when they structure their HTML differently.
Putting It Together: Searching Multiple Job Posting Keywords and Locations
Now that we've got the basic part bit by bit, let's combine everything into something powerful. Most job seekers need to search across multiple job titles and locations. Let's see a function that does exactly that:
...
def scrape_job_listings(keywords: List[str], locations: List[str]) -> List[Dict]:
"""
Search for multiple job keywords across different locations.
Think of it as having a virtual assistant check every job board
in every city you're interested in!
"""
client = ScrapingBeeClient(api_key='YOUR_API_KEY')
all_jobs = []
# Loop through each combination of keyword and location
for keyword in keywords:
for location in locations:
search_url = f"https://www.simplyhired.com/search?q={keyword}&l={location}"
try:
# Make the request with ScrapingBee AI extraction rules
response = client.get(
search_url,
params={
'ai_query': f'Extract all job listings for {keyword} jobs in {location}',
'ai_extract_rules': json.dumps(extraction_rules),
'render_js': True
}
)
if response.status_code == 200:
jobs = json.loads(response.content) # Directly parse the JSON response
all_jobs.extend(jobs)
else:
print(f"Failed to fetch data: {response.status_code}")
except Exception as e:
print(f"Error scraping {keyword} in {location}: {e}")
continue
return all_jobs
# Usage example
# Define what you're looking for
keywords = ['python developer', 'data engineer']
locations = ['San Francisco', 'Remote']
# Start the search
jobs = scrape_job_listings(keywords, locations)
Pro Tip: When scaling up your searches like this, remember to be mindful of rate limits. I've found that adding a slight delay between requests (like 2-3 seconds) can help avoid triggering any anti-scraping measures.
Step 4: Data Processing & Structure
First off, what does our job posting data look like? Remember that messy spreadsheet of job postings we talked about earlier? Let's see what our automated approach gives us instead:
# Print the first few job listings we collected
for job in jobs[:3]:
print(json.dumps(job, indent=2))
And voilà! Here's an example output:
{
"job_title": "Senior Python Developer",
"company": "TechCorp Inc.",
"location": "San Francisco, CA (Hybrid)",
"salary_range": "$150,000 - $200,000 per year",
"required_skills": [
"python",
"django",
"aws",
"docker",
"kubernetes"
],
"posting_date": "2026-01-18"
}
Pro Tip: JSON Giving You Headaches? While I'll keep things simple here, check out our complete guide to how to scrape JSON data with Python if you want to become a JSON parsing ninja. It covers everything from basic parsing to handling complex nested structures!
Sweet, right? No more copy-pasting into Excel or struggling with inconsistent formats. Talking about Excel - our clean JSON output is just the beginning. But that can be difficult to read, check our full guide on scraping data from a website to Excel. It's a game-changer for teams who live in spreadsheets!
Cleaning & Normalizing Job Postings Data
Here's where we add some serious polish to our data. After seeing every weird job posting format imaginable, here's my beloved cleaning approach:
...
from datetime import datetime
import re
class JobDataCleaner:
def __init__(self):
# Common patterns we've seen in job data
self.salary_pattern = re.compile(r'[\$£€](\d{1,3}(?:,\d{3})*(?:\.\d{2})?)')
def clean_job(self, job_data):
"""
Clean and standardize a single job posting
"""
cleaned = {}
# Basic text cleaning
cleaned['job_title'] = self.clean_text(job_data.get('job_title', ''))
cleaned['company'] = self.clean_text(job_data.get('company', ''))
cleaned['location'] = self.normalize_location(job_data.get('location', ''))
# Handle structured data
cleaned['salary_range'] = self.normalize_salary(job_data.get('salary_range', ''))
cleaned['required_skills'] = self.normalize_skills(job_data.get('required_skills', []))
cleaned['posting_date'] = self.normalize_date(job_data.get('posting_date'))
return cleaned
Normalizing salary and location:
def normalize_salary(self, salary_data):
"""Normalize salary to string format"""
if isinstance(salary_data, str):
# Extract numbers from salary string
matches = self.salary_pattern.findall(salary_data)
if len(matches) >= 2:
min_sal = float(matches[0].replace(',', ''))
max_sal = float(matches[1].replace(',', ''))
return f"${min_sal:,.2f} - ${max_sal:,.2f} per year"
return salary_data # Return as-is if no matches
def normalize_location(self, location):
"""Standardize location as simple string"""
if 'remote' in location.lower():
return "Remote"
return location.strip() # Just clean up whitespace for other locations
RegEx to the rescue! While we're using some basic patterns here, check out our guide on parsing HTML with RegEx if you want to level up your pattern-matching game. Fair warning: once you master RegEx, you'll want to use it everywhere!
Creating Structured Job Postings Datasets
Now, let's see how to save our clean data for future use. I like to support multiple formats:
import os
import pandas as pd
...
class JobDataStorage:
def __init__(self, base_path='job_data'):
self.base_path = base_path
os.makedirs(base_path, exist_ok=True)
# Save to a CSV file
def save_to_csv(self, df, filename):
try:
path = f"{self.base_path}/{filename}.csv"
df.to_csv(path, index=False)
print(f"Data saved to {path}")
except Exception as e:
print(f"Error saving to CSV: {e}")
# Save to SQLite for queryable storage
def save_to_sqlite(self, df, table_name):
try:
conn = sqlite3.connect(f"{self.base_path}/jobs.db")
df.to_sql(table_name, conn, if_exists='replace', index=False)
conn.close()
except Exception as e:
print(f"Error saving to SQLite: {e}")
if 'conn' in locals():
conn.close()
Pro Tip: When storing job data, think about how you'll use it later. CSV is great for quick Excel analysis, but SQLite is your friend if you need to run complex queries or build dashboards. In one project, I reduced reporting time from hours to minutes just by switching to a proper database structure!
Advanced Job Postings Scraping: Combining ScrapingBee Google Search API With AI Web Scraping API
How Our 2-API Strategy
Remember when I mentioned combining different approaches for better results? Grab your coffee (or tea!) because I'm about to share some of my favorite advanced techniques that have saved our clients countless hours of scraping headaches. Here's a game-changing strategy we've found incredibly effective: instead of scraping individual job boards, why not leverage Google's extensive job index?
Using Google Search results to discover job listings before diving into detailed scraping, our Google search API makes this incredibly powerful. Here's how:
from scrapingbee import ScrapingBeeClient
import requests
def search_jobs_with_serp(job_title, location):
"""
Use ScrapingBee's Google SERP API to discover job listings
"""
response = requests.get(
url="https://app.scrapingbee.com/api/v1/store/google",
params={
"api_key": "YOUR_API_KEY",
"search": f"{job_title} jobs {location}",
"add_html": False # We just need the structured data
}
)
if response.status_code == 200:
results = response.json()
# Extract organic results for job listings
job_urls = []
for result in results.get('body', {}).get('organic_results', []):
if any(job_board in result['url'] for job_board in ['linkedin.com/jobs', 'indeed.com', 'glassdoor.com']):
job_urls.append(result['url'])
return job_urls
else:
print(f"SERP API request failed: {response.status_code}")
return []
Pro Tip: I love this approach because Google's search results often surface the most relevant and fresh job postings. Plus, you get a bonus: Google's "related queries" can help you discover niche job titles you might have missed!
Let's now see how to combine these discovered URLs with our AI web scraping power. This is where things get really interesting!
...
def scrape_discovered_jobs(job_urls):
"""
Use AI scraping on the job URLs we found through SERP
"""
client = ScrapingBeeClient(api_key='YOUR_API_KEY')
collected_jobs = []
# Define what we want our AI to extract
extraction_rules = {
# defined
}
Now, let's get to work:
...
for url in job_urls:
try:
response = client.get(
url,
params={
'ai_query': 'Extract all details from this job posting',
'ai_extract_rules': json.dumps(extraction_rules),
'render_js': True, # Many job sites are JavaScript-heavy
'wait': '5000' # Give the page time to load fully
}
)
if response.status_code == 200:
job_data = json.loads(response.content)
collected_jobs.append(job_data)
else:
print(f"Failed to scrape {url}: {response.status_code}")
except Exception as e:
print(f"Error processing {url}: {e}")
continue
return collected_jobs
Now, let's put it all together:
...
def find_and_scrape_jobs(job_title, location):
# First, discover job URLs through SERP
print(f"🔍 Searching for {job_title} positions in {location}...")
job_urls = search_jobs_with_serp(job_title, location)
if not job_urls:
print("No job listings found!")
return []
print(f"Found {len(job_urls)} job listings. Starting detailed scraping...")
# Then scrape each discovered URL
jobs = scrape_discovered_jobs(job_urls)
print(f"Successfully scraped {len(jobs)} job postings!")
return jobs
Pro Tip: When dealing with scraping job postings, I've found that adding a slight delay (wait parameter) gives much better results. Job listings often have lazy-loaded content that needs a moment to appear.
Finally, here's how you'd use this combined approach:
# Let's hunt for some Python developer jobs!
python_jobs = find_and_scrape_jobs(
job_title="senior python developer",
location="San Francisco"
)
print("\nHere's a sample of what we found:")
print(json.dumps(python_jobs[0], indent=2))
Authentication & Session Handling
Sometimes you might need to login, let me share some tried-and-tested strategies for handling authentication.
def handle_authenticated_scraping(url, credentials):
"""
Handle job scraping from sites requiring authentication
"""
client = ScrapingBeeClient(api_key='YOUR_API_KEY')
# First, set up your cookies and headers
custom_headers = {
'Accept': 'application/json',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)'
}
# ScrapingBee API JavaScript scenario for login
login_scenario = {
'instructions': [
{'wait_for': 'input[name="email"]'},
{'fill': ['input[name="email"]', credentials['email']]},
{'fill': ['input[name="password"]', credentials['password']]},
{'click': 'button[type="submit"]'},
{'wait_for': '.job-listings'} # Wait for content to load
]
}
Now, time to make the request:
...
try:
response = client.get(
url,
params={
'js_scenario': json.dumps(login_scenario),
'cookies': credentials.get('cookies', ''),
'premium_proxy': 'true', # Use premium proxies for better success
'headers': custom_headers
}
)
return response
except Exception as e:
print(f"Authentication failed: {e}")
return None
Need more help with logins? Check out our guide on how to authenticate and login to a website to see a generic method that works on most websites!
Power User Tips:
- Use our premium proxies for better success rates with login-protected pages
- Fine-tune your requests with custom headers and cookies
Conclusion: Turning Job Postings Scraping Knowledge Into Action
Whew! We've covered much ground, haven't we? From basic setup to advanced scraping techniques. Before you zoom off into building your job-scraping powerhouse, let me leave you with three key takeaways.
3 Keys to Job Board Scraping Success
Successful job scraping isn't just about writing code – it's about building systems that:
- Adapt to changing job board structures (thank you, AI-powered web scraping!)
- Scale reliably (those pagination and session handling tricks come in handy)
- Deliver clean, consistent data (your future self will thank you for proper data processing)
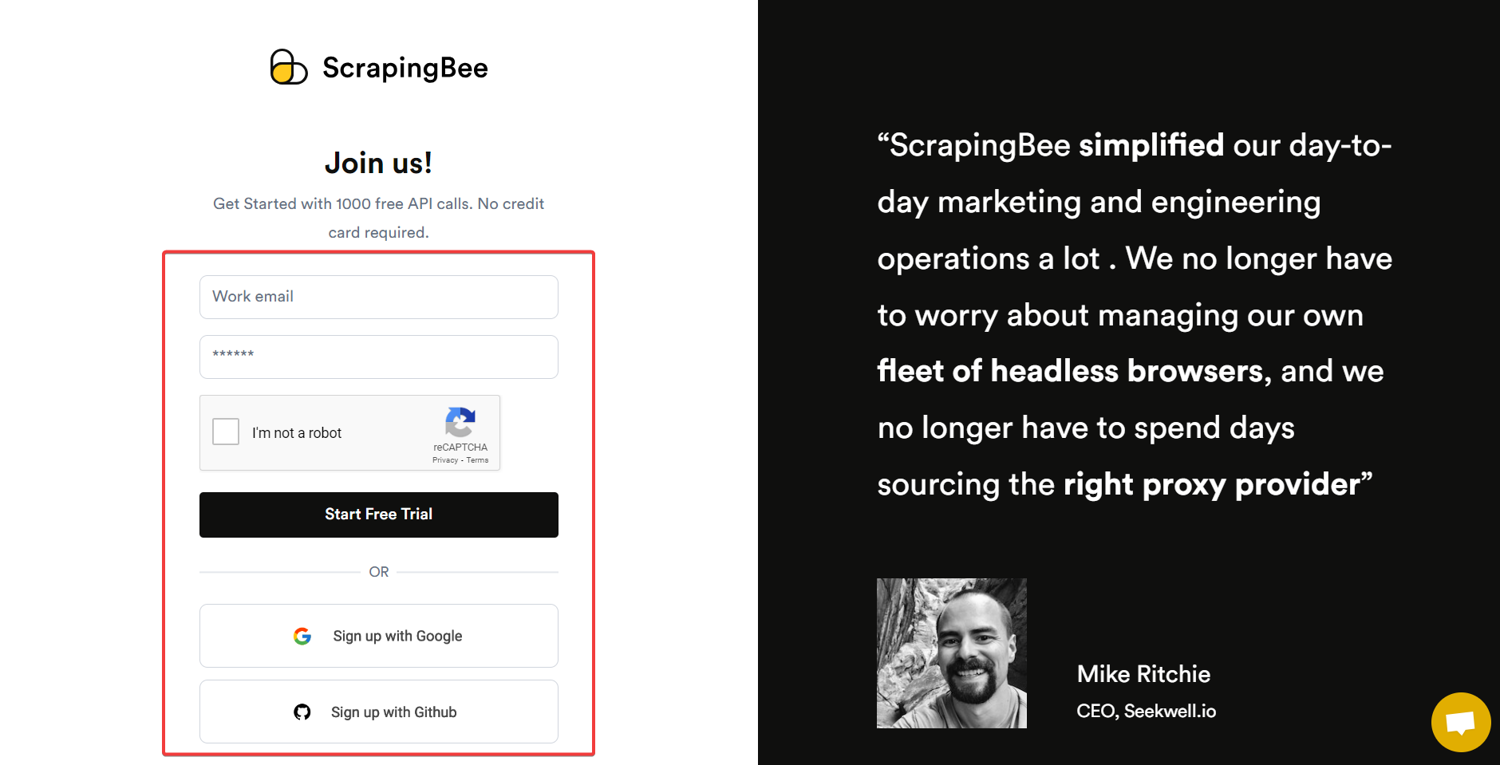
Ready to start scraping? Here's your quick-start checklist:
- Grab your ScrapingBee API key (those 1,000 free API calls are waiting for you!)
- Pick one job board to start with (don't try to boil the ocean)
- Use our AI scraping API to extract your first dataset
- Build from there!
Pro Tip: Start small, but think big. Remember that mid-sized tech company I mentioned? They started with just one script, pulling postings from a single job board. Now, they process thousands of listings daily. Your journey can start just as simply.
Additional AI Scraping Resources for 10X Better Scraping Results
Ready to explore more AI-powered scraping possibilities? We've compiled a collection of tutorials and case studies showcasing the versatility of using AI with web scraping. From e-commerce analytics to social media research, these guides will help you level up your scraping game:
| Tutorial | Description |
|---|---|
| How to Easily Scrape Shopify Stores With AI | Scrape Shopify websites with AI. In this tutorial, we’ll write a Python program to scrape one of the most successful Shopify stores on the planet! |
| Mapping the Funniest US States on Reddit using AI | Discover which US states joke the most on Reddit using AI. Explore our detailed analysis ranking states by humorous comments and uncover surprising patterns! |
| How to scrape all text from a website for LLM training | Learn how to scrape all text from a website for LLM AI training with our comprehensive guide. Discover effective tools & techniques to gather valuable data. |
| Scrapegraph AI Tutorial; Scrape websites easily with LLaMA AI | Explore how Scrapegraph AI simplifies web scraping using AI, making it easy to extract data from dynamically changing websites. Learn to set up the tool. |
| AI and the Art of Reddit Humor: Mapping Which Countries Joke the Most | Explore global humor on Reddit! AI analyzes which nations joke most in this intriguing study of subreddit comments. Discover which countries try to be the funniest! |
| How to use AI for automated price scraping? | How to scrape prices from websites using ScrapingBee and AI to automatically get the price's element xPath. |
Whether you're building a price monitoring system or training the next big language model, these resources will help you get there faster!
We’ve given you the tools to get ahead in your job search, enabling you to scrape job listings at scale to help you see them as soon as they hit the market.
You could go a step further and use this data to automatically tailor your CV and apply for jobs on mass, giving you the best chance by being first and spreading your bets, making sure you’re in the mix for the right positions.
Your move? As you've seen, those 1,000 free API calls are just the beginning.
Happy scraping.
Before you go, check out these related reads:



