Proxies are your ultimate cheat code, helping you bypass the anti-scraping bosses guarding valuable data behind firewalls and restrictions. This guide shows you how to obtain free proxies with an AI-powered scraper API, saving you time and money while leveling up your scraping game like a pro.
Free proxies are listed by several sources on the internet, and they usually allow us to filter by protocol type, country, and other parameters. In a previous blog post, we looked at some of these sources and tested them for various quality parameters. (In the context of proxies, quality would refer to whether the proxy actually works or not, and also the time it takes to complete a request.) In this tutorial we'll show you how to scrape fresh public proxies from any source and evaluate them to figure out which ones are working.
We’ll also use our new AI Query feature to simplify parsing proxy details from the HTML pages, but you should be able to use old-school HTML scraping if you wish to. The code illustrations are in Python, using the additional packages, requests, and PySocks. However, you can follow along with any programming language that supports sending HTTP requests - directly and through an HTTP/SOCKS proxy. For the AI query feature, you’ll need a ScrapingBee API Key.
Gathering Fresh Proxies From Free Public Lists
Most online lists have the proxies in a tabular format, showing the proxy IP address, port, protocol, country, and other details. Some websites might also provide an API to access the data in a neat format such as JSON or TXT. However, for this tutorial, we’ll attempt to build a generic scraper that can work across different sites.
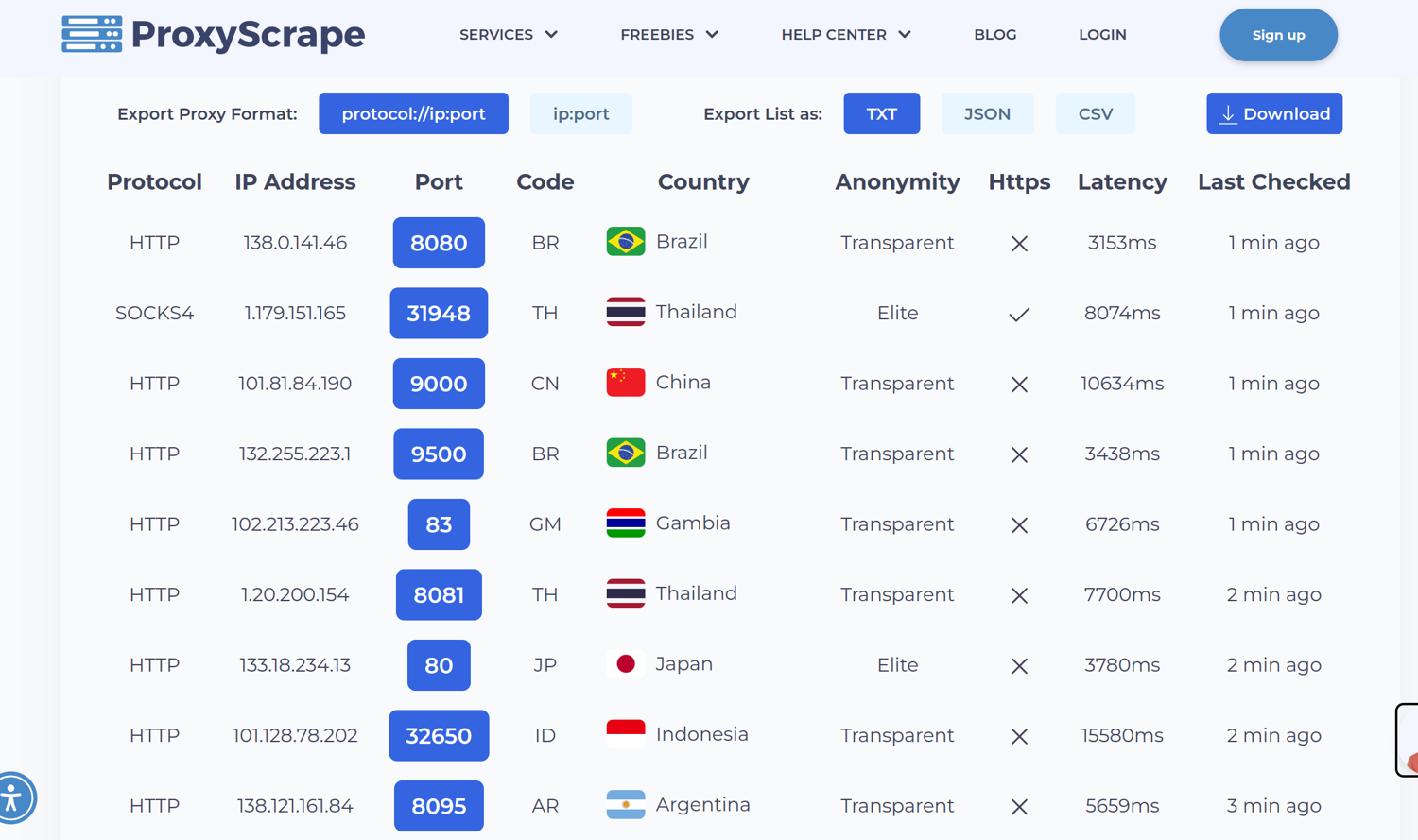
To test a proxy, we need three things - the protocol, the IP address, and the port number. In the next steps, let’s see how we can scrape a list of proxies with these three things using ScrapingBee’s AI query feature.
Step 1: Initializing the ScrapingBee Client
Let’s set up the ScrapingBee Client with an API key:
import json
from scrapingbee import ScrapingBeeClient
sb_client = ScrapingBeeClient(api_key="<YOUR_SCRAPINGBEE_KEY>")
Step 2: Defining the Proxy Lists to Scrape
PROXY_LISTS = [
'https://hide.mn/en/proxy-list/',
'https://gologin.com/free-proxy/',
'https://proxyscrape.com/free-proxy-list',
'http://free-proxy.cz/en/',
'https://gather-proxy.com/',
]
We’ve listed 5 URLs containing tables of free proxies. You can add more URLs to the list.
Step 3: Getting the Proxies From These Lists
# to store gathered proxies
proxies = []
for url in PROXY_LISTS:
response = sb_client.get(
url,
params={
'ai_query': 'Return a list showing proxy URLs in the page. Each proxy will have an IP addresses, with a corresponding port number and protocol type.',',
'ai_extract_rules': json.dumps({
"proxy_urls": {
'type': 'list',
'description': 'Proxy URLs in the format "protocol://ip:port"',
}
}),
'wait': 5000, # for js rendering, if needed
}
)
json_string = response.content.decode('utf-8')
# cleaning up the JSON string from the AI response
# it might be a markdown formatted code snippet sometimes
json_string = json_string.strip("`")
json_string = json_string.replace('\n', '')
if json_string.startswith('json'):
json_string = json_string[4:].replace("\\", "")
if json_string.startswith('```json'):
json_string = json_string.strip('`')[4:].strip('\n').replace("\\", "")
extracted = json.loads(json_string)
source_name = url.split('://')[1].split("/")[0]
for result in extracted['proxy_urls']:
proxies.append({
'url': result.lower(),
'source': source_name,
})
In the above code, we used the ScrapingBee AI query feature on each proxy list URL, asking it to simply return a list with the necessary information about the proxies, formatted as URLs containing the protocol, IP address, and port number in the format protocol://ip:port. Specifying a format, type of return value, and description under ai_extract_rules does most of the magic for us, and we don’t need to bother too much about any parsing. You can read more about this feature in our documentation. The only catch is that the scrapingbee python library sends a GET request to the API under the hood. Hence the JSON input for the ai_extract_rules has to be stringified, in order to be sent as a query parameter in the request. The result is a JSON string with a list of Proxy URLs, which may be markdown formatted at times, in which case we remove the markdown formatting.
After adding the source name for each proxy, we’ll have a list of proxies that looks like this:
[
{
"url": "socks5://68.183.132.69:7497",
"source": "hide.mn"
},
{
"url": "http://137.184.100.135:80",
"source": "free-proxy.cz"
},
...some more objects...
]
In the next steps, we’ll use the proxies in this list to test whether they are working, and measure the output - to create a filtered list of working proxies.
Testing the Free Proxies
Now that we have a list of proxies, let’s test them out, one by one. We’ll use the Python requests module to send a request to http://example.com via the proxy and observe the response parameters. We’ll take note of whether the response contains an expected string, the time taken for the response, and most importantly whether we receive a response at all. Let’s look at the code:
import requests
import time
for proxy in proxies:
try:
# note the start time before request is sent
t1 = time.perf_counter()
# send the request via proxy
r = requests.get(
'http://example.com',
proxies={
'https': proxy['url'],
'http': proxy['url'],
},
timeout=60,
)
# note the time after request completes
t2 = time.perf_counter()
# calculate time difference - the time taken for the request
proxy['time_taken'] = t2 - t1
# ensure the response is as expected
assert '<title>Example Domain</title>' in r.text
# if no Exception is thrown till this point,
# mark proxy as working
proxy['working'] = True
proxy['error'] = ''
# Catch various errors below,
# in each case, mark working as False
except requests.exceptions.ProxyError:
proxy['working'] = False
proxy['error'] = 'proxy_error'
except requests.exceptions.Timeout:
proxy['working'] = False
proxy['error'] = 'timeout'
except requests.exceptions.ConnectionError:
proxy['working'] = False
proxy['error'] = 'connection_error'
except AssertionError:
proxy['working'] = False
proxy['error'] = 'assertion_error'
except ValueError:
proxy['working'] = False
proxy['error'] = 'value_error'
In the above code, we checked each proxy by sending an HTTP request and marked it as a working proxy if it gave a response containing the expected HTML title. The request must also be completed within 60 seconds, failing which it will cause a Timeout error. Next, let’s look at summarizing and outputting the results of our analysis:
import pandas as pd
# to store the working proxies' details
working = {
'protocol': [],
'ip': [],
'port': [],
'source': [],
'response_time': [],
}
# to store source-wise data
sources = {}
# iterate over the results
for p in proxies:
source = p['source']
# add source to main dict, if not done earlier
if source not in sources:
sources[source] = {'total_count': 0, 'working_response_times': []}
# increment total proxy count for source by 1
sources[source]['total_count'] += 1
# for working proxies
if p['working']:
# get protocol, ip, and port
protocol, address = p['url'].split('://')
ip, port = address.split(':')
# add to the main working dict
working['protocol'].append(protocol)
working['ip'].append(ip)
working['port'].append(port)
working['source'].append(source)
working['response_time'].append(round(p['time_taken'], 3))
# add response time to source dict
sources[source]['working_response_times'].append(p['time_taken'])
# Output the working proxies list as markdown, for presentation
working_df = pd.DataFrame.from_dict(working)
working_df.to_markdown('working_proxies.md', index=False)
# convert the sources dict to make dataframe
source_data = {
'name': [],
'total': [],
'working': [],
'avg_response_time': [],
}
for source in sources:
working_count = len(sources[source]['working_response_times'])
# calculate average response times with just working proxies
avg_response_time = round(
sum(sources[source]['working_response_times'])/working_count, 3
)
source_data['name'].append(source)
source_data['total'].append(sources[source]['total_count'])
source_data['working'].append(working_count)
source_data['avg_response_time'].append(avg_response_time)
# Output the sources data as a markdown table
sources_df = pd.DataFrame.from_dict(source_data)
sources_df.to_markdown('sources_sumamry.md', index=False)
Results
With the above code, we’ll have two tables as output - a list of working proxies and a table with statistics for each source. Let’s see these below.
Working Free Proxies Table
| protocol | ip | port | source | response_time |
|---|---|---|---|---|
| http | 46.47.197.210 | 3128 | hide.mn | 0.63 |
| http | 185.191.236.162 | 3128 | hide.mn | 0.473 |
| http | 45.88.192.56 | 18080 | hide.mn | 5.663 |
| socks4 | 187.44.211.118 | 4153 | hide.mn | 8.442 |
| http | 119.188.93.251 | 81 | hide.mn | 0.811 |
| …more proxies |
Source-wise Statistics
| name | total | working | avg_response_time (s) |
|---|---|---|---|
| hide.mn | 64 | 11 | 6.066 |
| gologin.com | 50 | 37 | 6.275 |
| proxyscrape.com | 15 | 1 | 7.159 |
| free-proxy.cz | 30 | 19 | 1.779 |
| gather-proxy.com | 20 | 13 | 3.888 |
Conclusion
In this blog, we looked at how we can scrape a list of free public proxies from a given list of URLs. Free proxies are usually volatile because as soon as they are published they might be used by many people, leading their IP addresses to be blocked by certain services. Hence, it is important to obtain them afresh and check them before use. Writing code to automate this operation can help you scrape and filter a large number of proxies without significant manual effort - enabling you to scale up your web scraping operation.
We also looked at how we can use ScrapingBee’s AI query feature. It saved us from having to sift through the HTML to extract the data we needed. Also, the same query could work across multiple sites - unlike HTML structure-based data extraction which will need you to study the page structure of each website to extract data. Overall, the AI query feature is very handy to extract data from a bunch of URLs from several websites.
Before you go, check out these related reads:



