Python is a popular choice for web-scraping projects, owing to how easy the language makes scripting and its wide range of scraping libraries and frameworks. MechanicalSoup is one such library that can help you set up web scraping in Python quite easily.
This Python browser automation library allows you to simulate user actions on a browser like the following:
- Filling out forms
- Submitting data
- Clicking buttons
- Navigating through pages
One of the key features of MechanicalSoup is that its stateful browser can retain state and track state changes between requests. This helps simplify browser automation scripts in complex use cases, such as handling forms and dynamic content. MechanicalSoup also comes prebundled with Beautiful Soup, a popular Python library for parsing and manipulating web page content. Using MechanicalSoup and Beautiful Soup, you can write complex scraping scripts easily.
In this article, you'll learn how to use MechanicalSoup to scrape both static and dynamic websites. You'll start by scraping a static website like Wikipedia, and then you can explore some of MechanicalSoup's other features, such as form handling, navigation, and pagination, when you scrape a dynamic website.
Prerequisites
For this tutorial, you'll need Python installed on your system locally. Feel free to use any IDE of your choice to follow along.
You'll also need to set up a new directory for the project, where you will also install MechanicalSoup. To do that, create a new directory and change your terminal's working directory into it by running the following commands:
mkdir mechsoup-scraping
cd mechsoup-scraping
To keep your global Python packages clean, set up a virtual environment inside this directory so that your pip3 install command doesn't install MechanicalSoup globally. To do that, run the following commands on the same terminal window as before:
python3 -m venv env
source env/bin/activate
pip3 install mechanicalsoup
This completes the setup you need for writing scraping scripts with MechanicalSoup. You're ready to learn how to use it for scraping static and dynamic content.
Basic Web Scraping with MechanicalSoup
As mentioned before, MechanicalSoup is a browser automation library, not a complete web scraper in itself. Throughout this guide, you'll use the built-in Beautiful Soup object frequently to query for elements and extract data.
In this section, you'll extract the title and the reference links of a Wikipedia page.
Note: Of course, there's a lot of information that you can scrape from a Wikipedia page, but extracting just the title and the reference links should help you understand how to find HTML tags and how to extract data from deep within the HTML hierarchy of a page.
To start, create a new file with the name wikipedia_scraper.py in your project directory and import the MechanicalSoup library by adding the following line of code to it:
import mechanicalsoup
Next, define a main() function and call it at the bottom of the script. Write all of your code inside this function:
def main():
# You will be writing all your code here
main()
Now, you can write the code (inside the main() function) for creating a new instance of the stateful browser and navigating to the Wikipedia page using the open() function:
browser = mechanicalsoup.StatefulBrowser()
browser.open("https://en.wikipedia.org/wiki/Web_scraping")
Extracting the Title
To extract the title, you first need to understand the structure of the Wikipedia page. Open the page in Google Chrome and press F12 to open the developer tools. In the Elements tab, look for the HTML tag for the title of the page. Here's what it will look like:
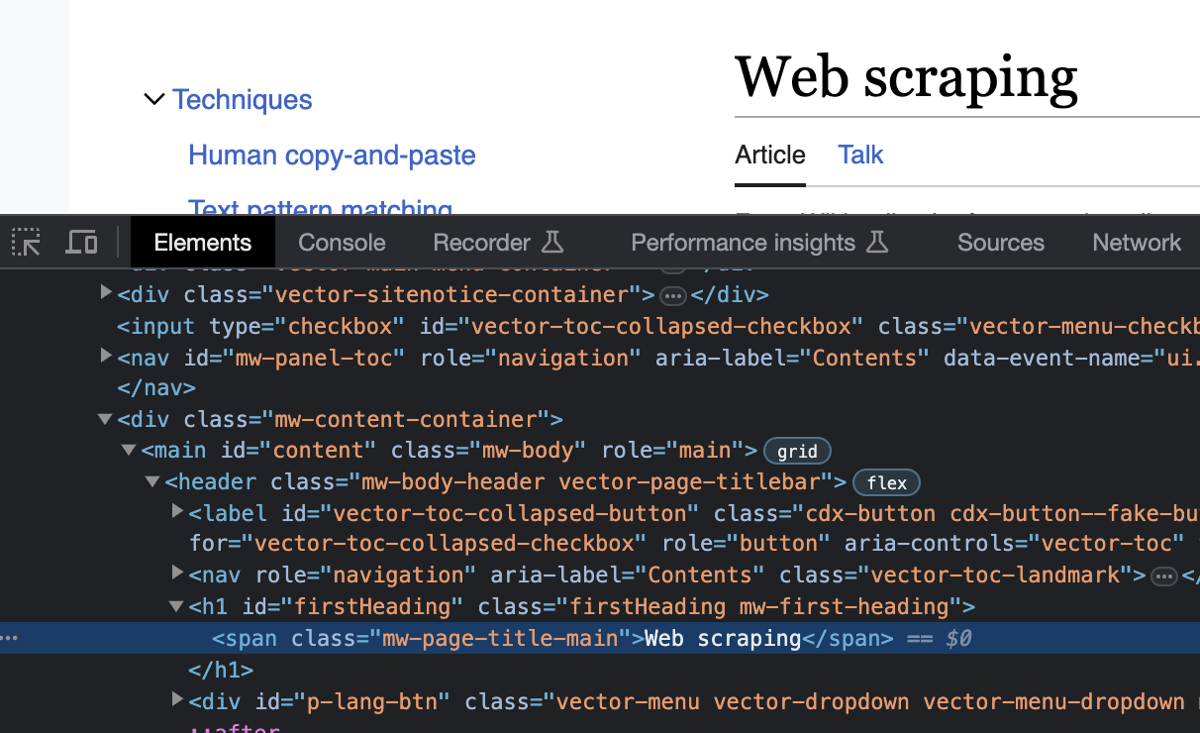
To get the title from the page, look for a span tag that has the class mw-page-title-main. Add the following lines of code to your main function:
title = browser.page.select_one('span.mw-page-title-main')
print("title: " + title.string)
browser.page provides you access to the bundled Beautiful Soup object, which is preloaded with the page data as soon as browser.open() is run. The select_one function is one of the many functions that Beautiful Soup offers for searching and finding elements in an HTML structure. It selects the first element that matches the CSS selector given to it.
The selected element is stored in title, and the string function is used to extract the contents of the element in the form of a string.
This is what the wikipedia_scraper.py file should look like at this point:
import mechanicalsoup
def main():
browser = mechanicalsoup.StatefulBrowser()
browser.open("https://en.wikipedia.org/wiki/Web_scraping")
title = browser.page.select_one('span.mw-page-title-main')
print("title: " + title.string)
main()
You can run this script by running the following command on your terminal window:
python3 wikipedia_scraper.py
Here's what the output should look like:
title: Web scraping
Extracting the References
Next, you'll find and extract all the links from the references section of the web page. First, take a quick peek at the HTML structure of the References section by inspecting it with your browser's developer tools:
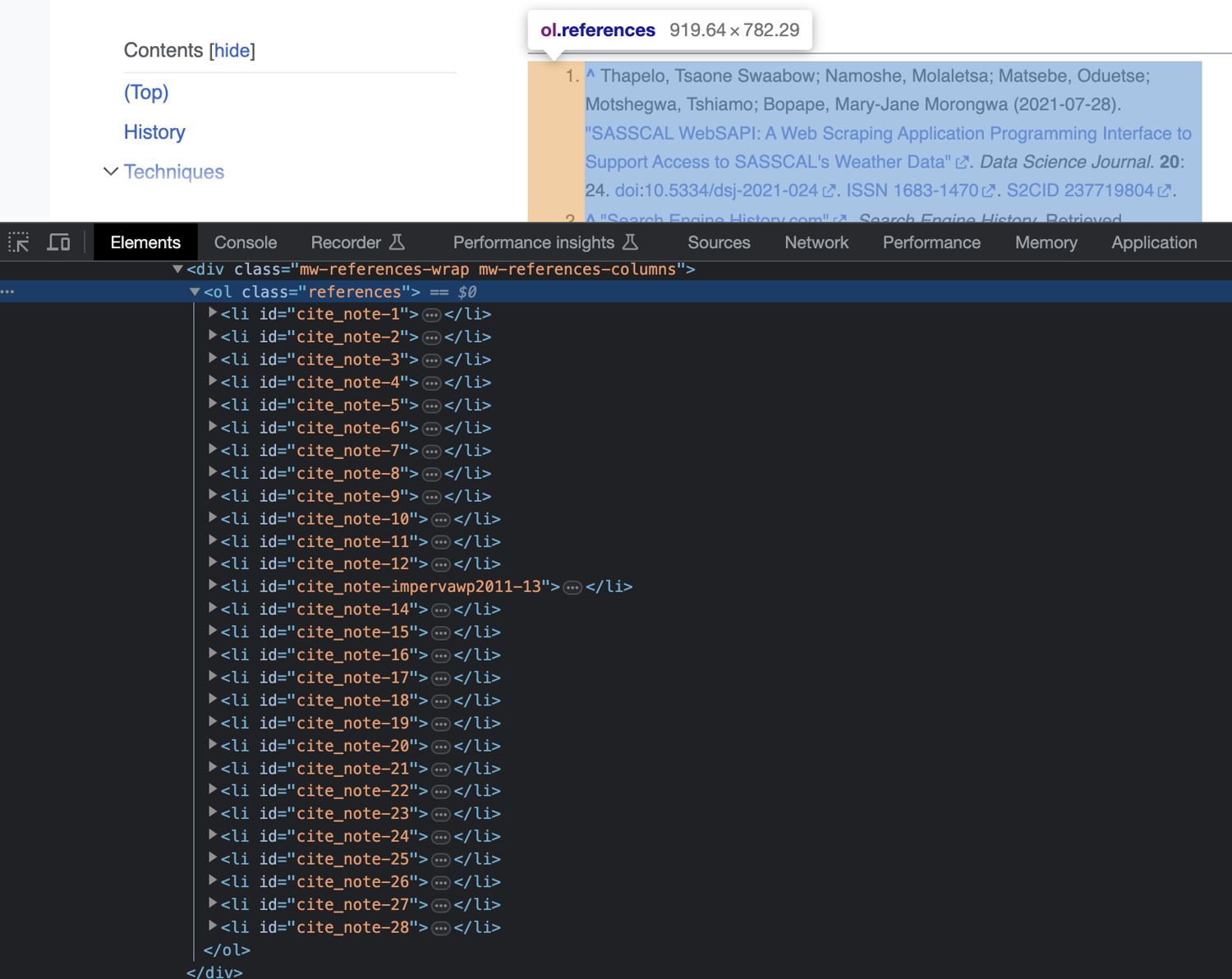
First, select the ordered list (ol) tag that has the class references. With that tag selected, you can consider using Beautiful Soup's find_all method to extract all links inside this ol tag. However, on a closer look, you'll find that this section also contains backlinks to places in the same Wikipedia page where each reference was cited:
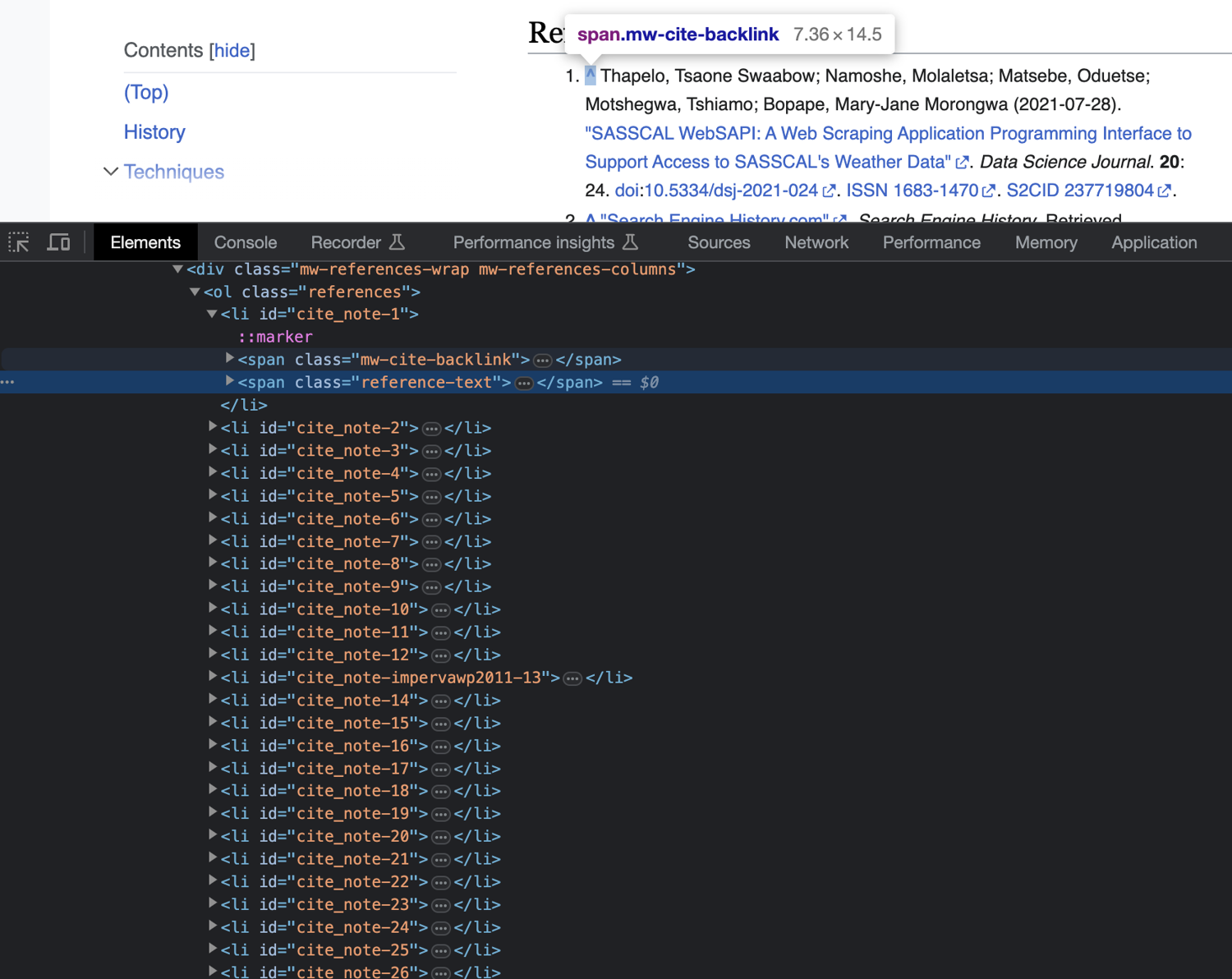
If you extract all links from this tag using the find_all function, the results will contain same-page backlinks too, which you don't need. To avoid that, you need to select all reference-text span tags and extract the links from them. To do that, add the following code to your main function:
# Select the **References section**
references = browser.page.select_one('ol.references')
# Select all span tags with the class `reference-text` to exclude backlinks
references_list = references.select('span.reference-text')
# For each reference span tag, find all anchor elements and print their href attribute values
for reference in references_list:
link_tags = reference.find_all("a")
for link_tag in link_tags:
link = link_tag.get("href")
if link:
print(link)
At this point, your wikipedia_scraper.py file should look like this:
import mechanicalsoup
def main():
browser = mechanicalsoup.StatefulBrowser()
browser.open("https://en.wikipedia.org/wiki/Web_scraping")
title = browser.page.select_one('span.mw-page-title-main')
print("title: " + title.string)
references = browser.page.select_one('ol.references')
references_list = references.select('span.reference-text')
for reference in references_list:
link_tags = reference.find_all("a")
for link_tag in link_tags:
link = link_tag.get("href")
if link:
print(link)
main()
You can run this script by running the following command:
python3 wikipedia_scraper.py
The output should look like this:
title: Web scraping
https://doi.org/10.5334%2Fdsj-2021-024
... output truncated ...
http://www.webstartdesign.com.au/spam_business_practical_guide.pdf
https://s3.us-west-2.amazonaws.com/research-papers-mynk/Breaking-Fraud-And-Bot-Detection-Solutions.pdf
Advanced Web Scraping with MechanicalSoup
Now that you know how to scrape simple websites with MechanicalSoup, you can learn how to use it to scrape dynamic multipage websites. To start, create a new file in your project directory with the name dynamic_scraper.py and save the following code in it:
import mechanicalsoup
import csv
browser = mechanicalsoup.StatefulBrowser()
def extract_table_data(file_name):
pass
def navigate():
pass
def handle_form():
pass
def handle_pagination():
pass
def main():
navigate()
handle_form()
handle_pagination()
main()
The file currently defines a number of functions that you'll write later to complete each part of this section.
But before writing the code for scraping, it would be helpful to understand the target website first. In this section, you'll scrape a sandbox called Scrape This Site. First, navigate to its home page:
Then navigate to the Sandbox page via the link from the top navigation bar:
From there, navigate to the Hockey Teams: Forms, Searching, and Pagination page:
On this page, search for teams that have the word "new" in their name. Finally, extract two pages of search results as CSV files.
Navigation
To navigate through web pages, you can use MechanicalSoup's follow_link function. You'll need to provide it with the target link that you want to navigate to, so locate and select the appropriate anchor tags on each page and extract their href attribute values.
Navigate the browser to the home page of the sandbox website by adding the following line of code to your navigate() function:
browser.open("https://www.scrapethissite.com/")
print(browser.url)
The print(browser.url) line allows you to print the current URL of the browser. This helps you understand where the browser is throughout your browser automation session. You'll use it multiple times throughout this navigation section.
Next, find the link to the sandbox page from the navigation bar. If you inspect the page, you'll find that the link is inside an <li> tag that has the id as nav-sandbox. You can use the following code to extract and follow the link from this tag:
sandbox_nav_link = browser.page.select_one('li#nav-sandbox')
sandbox_link = sandbox_nav_link.select_one('a')
browser.follow_link(sandbox_link)
print(browser.url)
Next, locate and follow the Hockey Teams: Forms, Searching and Pagination link. If you inspect the HTML structure around this element, you'll notice that each link on this page is inside <div class="page"> tags.
You can extract all these divs first, select the second div, and then select and extract the link from the a tag from within it. Here's the code you can use to do that:
sandbox_list_items = browser.page.select('div.page')
hockey_list_item = sandbox_list_items[1]
forms_sandbox_link = hockey_list_item.select_one('a')
browser.follow_link(forms_sandbox_link)
print(browser.url)
This will bring your browser to the hockey teams' information page. And this is how your navigate() function should look like when you're done:
def navigate():
browser.open("https://www.scrapethissite.com/")
print(browser.url)
sandbox_nav_link = browser.page.select_one('li#nav-sandbox')
sandbox_link = sandbox_nav_link.select_one('a')
browser.follow_link(sandbox_link)
print(browser.url)
sandbox_list_items = browser.page.select('div.page')
hockey_list_item = sandbox_list_items[1]
forms_sandbox_link = hockey_list_item.select_one('a')
browser.follow_link(forms_sandbox_link)
print(browser.url)
You can now try to confirm whether the browser reaches the correct link by running the following command:
python3 dynamic_scraper.py
Here's what the output should look like:
https://www.scrapethissite.com/
https://www.scrapethissite.com/pages/
https://www.scrapethissite.com/pages/forms/
This indicates that your browser has successfully navigated to the forms page.
Handling Forms
To search for all teams that contain the word "new" in their names, you'll need to fill out the search box and click on the search button.
MechanicalSoup offers a form class to facilitate simpler form handling. You can select a form using its CSS selector and then easily pass input to it according to the names of its input fields.
MechanicalSoup also provides a simple function called submit_selected(), which allows you to submit a form without having to locate and click its submit button.
If you inspect the website's structure, you'll notice that the form element has the classes form and form-inline. You can use one of these to identify and select the form. Notice that the input box has been named q. You can use these two details to write the code for handling this page's search form in the handle_form() function:
def handle_form():
browser.select_form('form.form-inline')
browser.form.input({"q": "new"})
browser.submit_selected()
extract_table_data("first-page-results.csv")
The last line of the handle_form() function calls the extract_table_data(file_name) function to extract the table data from the page when the search results are loaded. You'll define the function in the next section.
Extracting Data from a Table
To extract the table data from the page, you'll use the select_one and select functions from Beautiful Soup, just as you did earlier in this tutorial. Save the following code in your extract_table_data function:
def extract_table_data(file_name):
# Select the table element
results = browser.page.select_one('table')
# Open a file and prepare a CSV Writer object
file = open(file_name, 'w')
csvwriter = csv.writer(file)
# Select the headers from the table first
headers = results.select('th')
# Create a temporary array to store the extract table header cells
temp_header_row = []
# For each header from the headers row, add it to the temporary array
for header in headers:
temp_header_row.append(header.string.strip().replace(",", ""))
# Write the temporary array to the CSV file
csvwriter.writerow(temp_header_row)
# Next, select all rows of the table
rows = results.select('tr.team')
# For each row, prepare a temporary array containing all extracted cells and append it to the CSV file
for row in rows:
cells = row.select('td')
temp_row = []
for cell in cells:
temp_row.append(cell.string.strip().replace(",", ""))
csvwriter.writerow(temp_row)
# Close the CSV file at the end
file.close()
Note: Take a look at the inline comments in the code above to help you understand how it works.
You'll reuse this function after handling pagination to capture results from the second page of results.
Handling Pagination
MechanicalSoup doesn't offer any special methods for handling navigation. You have to select the appropriate link from the pagination element and follow it via your browser object to navigate to the desired page.
Here's what the HTML structure of the pagination element looks like:
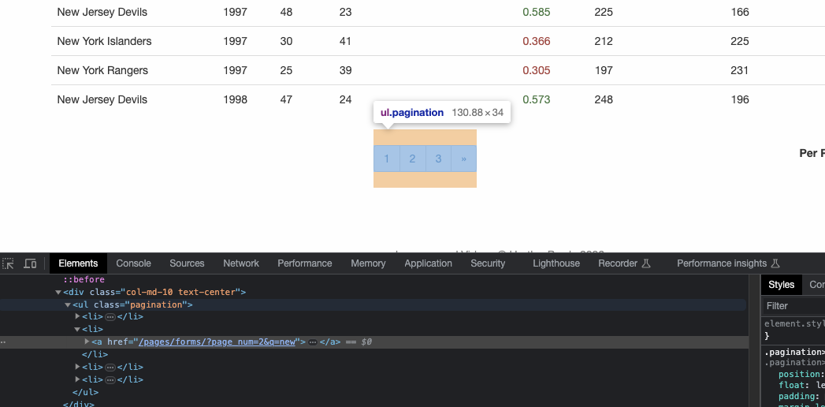
First, select the <ul> tag that has the pagination class added to it. Then, find the right <li> tag in it (based on the page number you want to navigate to), and finally, extract the href value from the <a> tag inside the <li> tag you identified. Here's the code to do it:
def handle_pagination():
pagination_links = browser.page.select_one('ul.pagination')
page_links = pagination_links.select('li')
# Choose the link at index 1 to navigate to page 2
next_page = page_links[1]
next_page_link = next_page.select_one('a')
browser.follow_link(next_page_link)
print(browser.url)
# Extract the table data from this page too
extract_table_data('second-page-results.csv')
This completes the scraper code, so your dynamic_scraper.py file should now look like this:
import mechanicalsoup
import csv
browser = mechanicalsoup.StatefulBrowser()
def extract_table_data(file_name):
results = browser.page.select_one('table')
file = open(file_name, 'w')
csvwriter = csv.writer(file)
headers = results.select('th')
temp_header_row = []
for header in headers:
temp_header_row.append(header.string.strip().replace(",", ""))
csvwriter.writerow(temp_header_row)
rows = results.select('tr.team')
for row in rows:
cells = row.select('td')
temp_row = []
for cell in cells:
temp_row.append(cell.string.strip().replace(",", ""))
csvwriter.writerow(temp_row)
file.close()
def navigate():
browser.open("https://www.scrapethissite.com/")
print(browser.url)
sandbox_nav_link = browser.page.select_one('li#nav-sandbox')
sandbox_link = sandbox_nav_link.select_one('a')
browser.follow_link(sandbox_link)
print(browser.url)
sandbox_list_items = browser.page.select('div.page')
hockey_list_item = sandbox_list_items[1]
forms_sandbox_link = hockey_list_item.select_one('a')
browser.follow_link(forms_sandbox_link)
print(browser.url)
def handle_form():
browser.select_form('form.form-inline')
browser.form.input({"q": "new"})
browser.submit_selected()
extract_table_data("first-page-results.csv")
def handle_pagination():
pagination_links = browser.page.select_one('ul.pagination')
page_links = pagination_links.select('li')
next_page = page_links[1]
next_page_link = next_page.select_one('a')
browser.follow_link(next_page_link)
print(browser.url)
extract_table_data('second-page-results.csv')
def main():
navigate()
handle_form()
handle_pagination()
main()
Run the following command to try it out:
python3 dynamic_scraper.py
This is how the terminal output should look:
https://www.scrapethissite.com/
https://www.scrapethissite.com/pages/
https://www.scrapethissite.com/pages/forms/
https://www.scrapethissite.com/pages/forms/?page_num=2&q=new
Notice that two new CSV files will be created in the project directory: first-page-results.csv and second-page-results.csv. These will contain the results data extracted from the tables.
For reference, here's what a few rows from the second-page.csv file look like:
Team Name,Year,Wins,Losses,OT Losses,Win %,Goals For (GF),Goals Against (GA),+ / -
New York Islanders,1998,24,48,,0.293,194,244,-50
New York Rangers,1998,33,38,,0.402,217,227,-10
New Jersey Devils,1999,45,24,5,0.549,251,203,48
New York Islanders,1999,24,48,1,0.293,194,275,-81
New York Rangers,1999,29,38,3,0.354,218,246,-28
New Jersey Devils,2000,48,19,3,0.585,295,195,100
New York Islanders,2000,21,51,3,0.256,185,268,-83
This completes the tutorial for setting up web scraping using MechanicalSoup in Python! You can find the complete code created in the tutorial on this GitHub repo.
Conclusion
In this article, you learned how to set up MechanicalSoup for stateful browser automation and web scraping in Python. You learned how to scrape a simple website first, like Wikipedia, and then you explored more complex operations such as navigation, pagination, and form handling.
MechanicalSoup is a great solution for quickly setting up web scraping and automation scripts in Python. It's arguably simpler than some of the other premier names, like Selenium.
However, setting up a web scraper manually with MechanicalSoup means you might run into issues like IP blocking, georestrictions, honeypot traps, CAPTCHAs, and other challenges that websites put in place to deter web scraping. If you prefer not to have to deal with rate limits, proxies, user agents, and browser fingerprints, please check out Scrapingbee's no-code web scraping API. And remember, the first 1,000 calls are on us!
"Before you go, check out these related reads:



