In the first article about java web scraping I showed how to extract data from CraigList website. But what about the data you want or if the action you want to carry out on a website requires authentication ?
In this short tutorial I will show you how to make a generic method that can handle most authentication forms.
Authentication mechanism
There are many different authentication mechanisms, the most frequent being a login form , sometimes with a CSRF token as a hidden input.
To auto-magically log into a website with your scrapers, the idea is :
GET /loginPage
Select the first
<input type="password">tagSelect the first
<input>before it that is not hiddenSet the value attribute for both inputs
Select the enclosing form, and submit it.
Hacker News Authentication
Let's say you want to create a bot that logs into hacker news (to submit a link or perform an action that requires being authenticated) :
Here is the login form and the associated DOM :
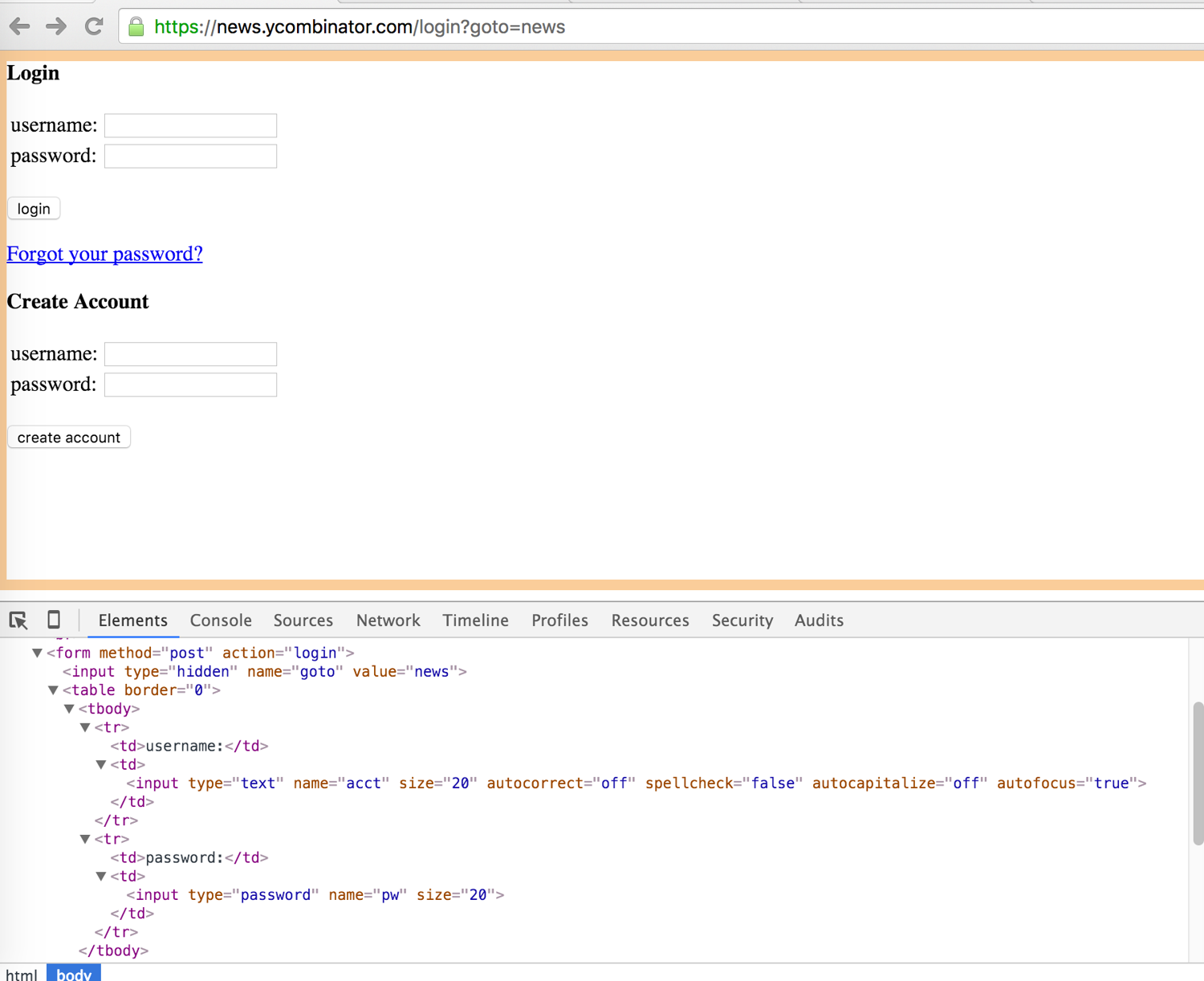
Now we can implement the login algorithm
public static WebClient autoLogin(String loginUrl, String login, String password) throws FailingHttpStatusCodeException, MalformedURLException, IOException{
WebClient client = new WebClient();
client.getOptions().setCssEnabled(false);
client.getOptions().setJavaScriptEnabled(false);
HtmlPage page = client.getPage(loginUrl);
HtmlInput inputPassword = page.getFirstByXPath("//input[@type='password']");
//The first preceding input that is not hidden
HtmlInput inputLogin = inputPassword.getFirstByXPath(".//preceding::input[not(@type='hidden')]");
inputLogin.setValueAttribute(login);
inputPassword.setValueAttribute(password);
//get the enclosing form
HtmlForm loginForm = inputPassword.getEnclosingForm() ;
//submit the form
page = client.getPage(loginForm.getWebRequest(null));
//returns the cookie filled client :)
return client;
}
Then the main method, which :
calls
autoLoginwith the right parametersGo to
https://news.ycombinator.comCheck the logout link presence to verify we're logged
Prints the cookie to the console
public static void main(String[] args) {
String baseUrl = "https://news.ycombinator.com" ;
String loginUrl = baseUrl + "/login?goto=news" ;
String login = "login";
String password = "password" ;
try {
System.out.println("Starting autoLogin on " + loginUrl);
WebClient client = autoLogin(loginUrl, login, password);
HtmlPage page = client.getPage(baseUrl) ;
HtmlAnchor logoutLink = page.getFirstByXPath(String.format("//a[@href='user?id=%s']", login)) ;
if(logoutLink != null ){
System.out.println("Successfuly logged in !");
// printing the cookies
for(Cookie cookie : client.getCookieManager().getCookies()){
System.out.println(cookie.toString());
}
}else{
System.err.println("Wrong credentials");
}
} catch (Exception e) {
e.printStackTrace();
}
}
You can find the code in this Github repo
Go further
There are many cases where this method will not work : Amazon, DropBox... and all other two-steps/captcha protected login forms.
Things that can be improved with this code :
Handle the check for the logout link inside
autoLoginCheck for
nullinputs/form and throw an appropriate exception
In a next post I will show you how to deal with captchas or virtual numeric keyboards with OCR and captchas breaking APIs !
If you like web scraping and are tired taking care of proxies, JS rendering and captchas, you can check our new web scraping API, the first 1000 API calls are on us.

Kevin worked in the web scraping industry for 10 years before co-founding ScrapingBee. He is also the author of the Java Web Scraping Handbook.