Go is a versatile language with packages and frameworks for doing almost everything. Today you will learn about one such framework called Colly that has greatly eased the development of web scrapers in Go.
Colly provides a convenient and powerful set of tools for extracting data from websites, automating web interactions, and building web scrapers. In this article, you will gain some practical experience with Colly and learn how to use it to scrape comments from Hacker News.

Final Product
By the end of this tutorial, you will have a Go program that will scrape all the comments from a Hacker News submission and dump them into the terminal. You will be working with this submission, and this is what the program output will look like:
{
"URL": "https://reddark.untone.uk/",
"Title": "Reddit Strike Has Started",
"Site": "reddark.untone.uk",
"Id": "36283249",
"Score": "1397 points",
"TotalComments": 894,
"Comments": [
{
"Author": "wpietri",
"URL": "https://news.ycombinator.com/item?id=36283389",
"Comment": "Great! There's a picket line I won't be crossing. Not just for those subs, of course, but for all of Reddit.The reason Reddit is valuable is not the few execs making these (IMHO terrible) decisions. It's the thousands of mods and the millions of people creating and organizing the content that I go there to read. Until those people are happy with things, I'm not going back."
},
{
"Author": "jcims",
"URL": "https://news.ycombinator.com/item?id=36283543",
"Comment": "Reddit is basically successful despite itself. It's wild."
},
{
"Author": "wpietri",
"URL": "https://news.ycombinator.com/item?id=36283661",
"Comment": "Twitter too! When I worked there they jokingly referred to the head of product as the defense against the dark arts teacher, in that every year or so they'd disappear mysteriously and there'd be a new one. Most of Twitter's successes came from watching what users were actually doing and supporting that (e.g., at mentions, retweets, quote tweets). Many of their failures have been trying to graft on something irrelevant or actively contradictory to user needs. Or just flat out ignoring things users liked, as with them closing down Vine and letting TikTok come in to win as the short, fun video platform.But network effects businesses are really hard to kill. Sure, Musk has set $20-30 billion on fire and Twitter is rapidly decaying. But imagine taking a resilient business like a McDonald's franchise and subjecting it to Musk levels of chaos. It would have been out of business long before, instead of merely shrinking significantly."
},
// ... additional comments ...
]
}
Setting Up the Prerequisites
This tutorial will use Go version 1.20.5. You can check your installed Go version by running the following command:
$ go version
If you have Go version 1.19.1 or higher, you should be fine.
Let's start by creating a new folder to store the project code and initialize a Go module in there:
$ mkdir scraper
$ cd scraper
$ go mod init scraper
You also need to install Colly as a dependency:
$ go get github.com/gocolly/colly
Next, create the file hn.go to store the code for your scraper:
$ touch hn.go
Your folder should contain the following three files:
.
├── go.mod
├── go.sum
└── hn.go
To make sure everything is set up correctly, add the following code to the hn.go file and run it:
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.Visit("https://news.ycombinator.com/item?id=36283249")
fmt.Println("Hello, World!")
}
$ go run hn.go
# Output: Hello, World!
If you see Hello, World! as the output, everything is working as expected, and you can move on to the fun stuff!
How Colly Works
The central piece of Colly is the Collector. You will be using the Collector to perform HTTP requests. In the last code block of the previous section, c := colly.NewCollector() created a new Collector instance.
You can visit a web page using either the Visit method or the Request method provided by the Collector. You will generally rely on Visit in most cases, but where you need to pass some extra information with a request, Request comes in handy.
Colly relies heavily on callbacks. These callbacks are triggered based on certain conditions or at a certain point in a request lifecycle. The Collector also allows you to register them. The six main callbacks are as follows:
OnRequest: called before a request is sent by the CollectorOnError: called when an error occurs during a requestOnResponse: called after a response is received by the CollectorOnHTML: called afterOnResponseand only if the received content is of type HTMLOnXML: called afterOnHTMLand only if the received content is of type HTML or XMLOnScraped: called at the very end after theOnXMLcallbacks
You can register as many callbacks of each type as you want. The most important one that you will be relying on in general is the OnHTML callback. This callback is registered with a CSS Selector. Whenever Colly finds a matching element in the DOM, it will run the callback function.
Note: Colly uses goquery for matching CSS selectors. goquery itself is modeled around jQuery, and therefore, any selector that works with jQuery should also work with goquery.
This is enough information for you to get started with scraping the comments from Hacker News. You can always explore Colly's documentation to learn more.
Deciding What to Scrape
When you start any web scraping project, it is important to decide what you want to scrape. This will dictate your next steps. In this tutorial, you will be scraping the following information for a submission:
- ID
- Title
- URL
- Site
- Score
- Comments
And for each comment, you will be scraping the following:
- Author
- Permalink
- Text
The screenshot below highlights where all of this information is stored on the page:
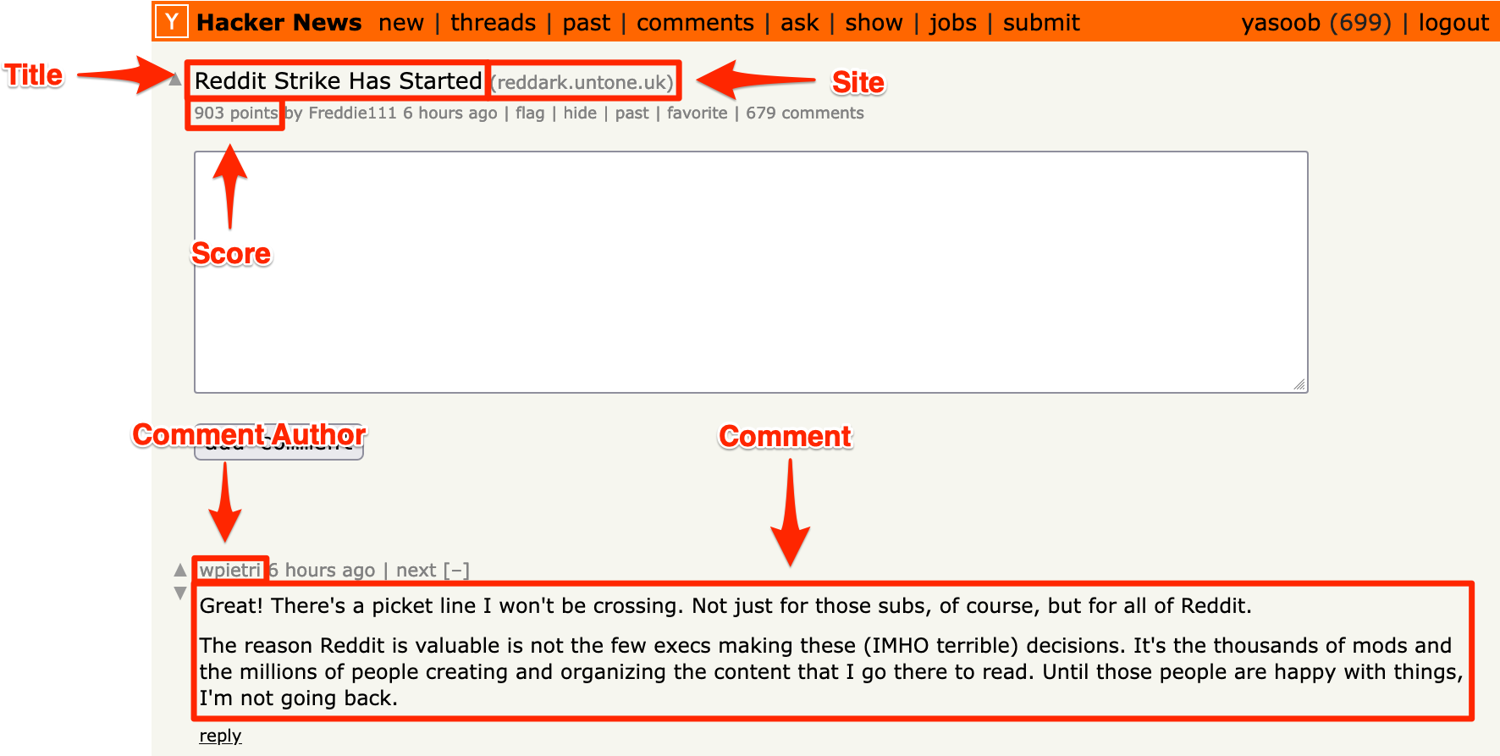
Start by creating some basic structs to store the extracted information:
type submission struct {
Title string
URL string
Site string
Id string
Score string
Comments []*comment
}
type comment struct {
Author string
URL string
Comment string
}
You will be modifying these structs soon enough, but this is good as a starting point.
Fetching the Submission Page
You might remember this piece of code from earlier in this tutorial:
c.Visit("https://news.ycombinator.com/item?id=36283249")
It fetches a submission page from Hacker News.
Let's register an OnHTML callback and use html as a selector. This ensures the callback will run whenever there is an html tag in the HTML response:
c.OnHTML("html", func(e *colly.HTMLElement) {
println("Found an HTML tag!")
}
Run the code in the terminal and make sure your output matches:
$ go run hn.go
# Found an HTML tag!
Scraping Submission Information
This is the perfect time to explore the HTML of the page to figure out which tags contain the information you need. Open up the submission page in your browser of choice and use the developer tools to explore the HTML.
Extracting Submission Title, URL, and Site
Right-click on the submission title and click on Inspect in the context menu. This should open up the Developer Tools window:
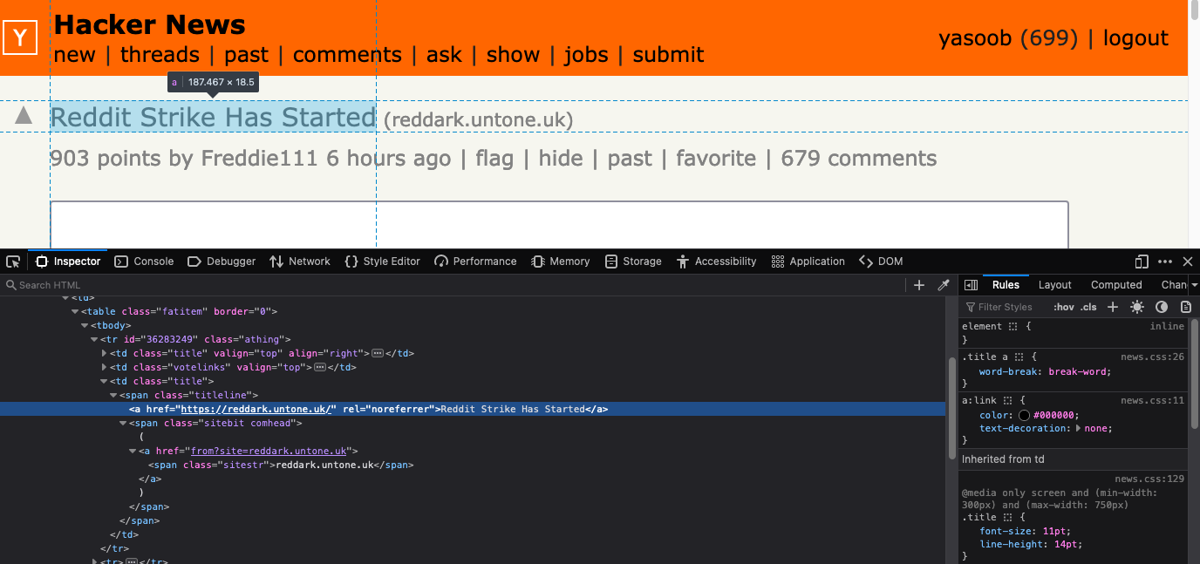
As you can see in the screenshot above, the title is nested in an anchor (a) tag, which in turn is nested in a span with a class of titleline. The anchor tag contains the submission URL as a value of the href attribute. The site information is stored in a span with the class of sitestr.
The following are the relevant CSS selectors:
- Title:
span.titleline > a - Site:
span.sitestr - URL:
span.titleline > a(and then extracting thehreffrom the anchor tag)
Colly provides a very neat Unmarshal feature that lets you use CSS selectors as struct tags to declaratively extract text or attributes from HTML response to a struct.
You already have the required information to modify the structs and add tags to make use of Unmarshal, so modify the submission struct like this:
type submission struct {
Title string `selector:"span.titleline > a"`
URL string `selector:"span.titleline > a[href]" attr:"href"`
Site string `selector:"span.sitestr"`
Id string
Score string
Comments []*comment
}
Now, modify the main function like this:
s := &submission{}
c := colly.NewCollector()
c.OnHTML("html", func(e *colly.HTMLElement) {
e.Unmarshal(s)
}
c.Visit("https://news.ycombinator.com/item?id=36283249")
This code extracts the data from the HTML page based on struct tags and populates the submission struct. The struct tags themselves are very simple. They contain a selector part that is used to target an HTML tag and optionally an attr part that can be used to extract a tag attribute if required. If the attr is missing, the text is extracted from the tag that matches the selector.
Extracting Submission Score
This is what the HTML structure looks like for the submission score:
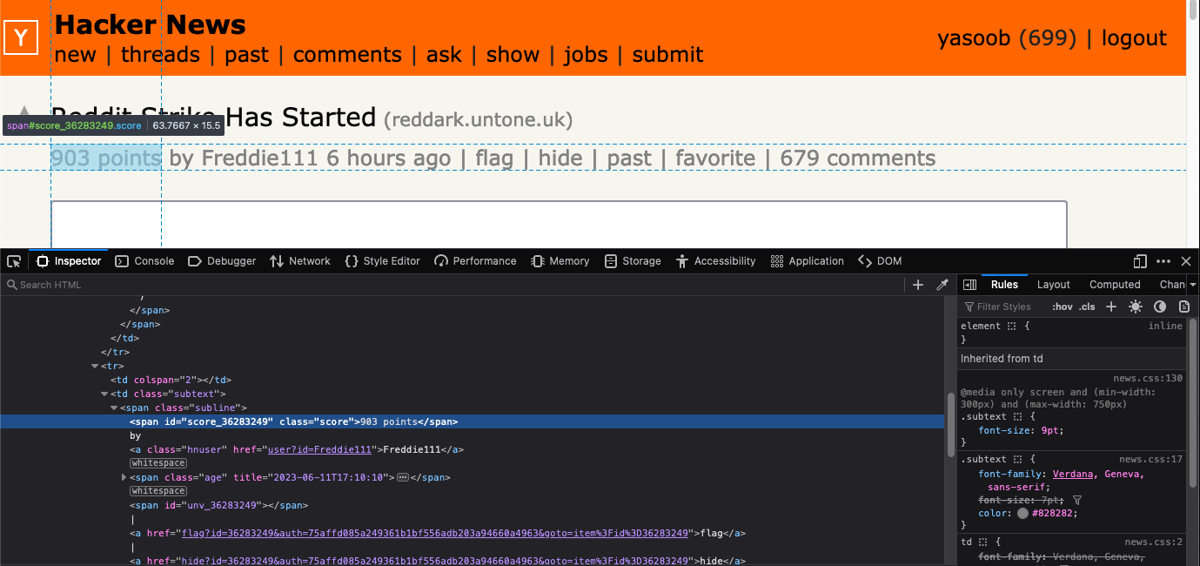
The score is stored within a span with a class of score. The relevant CSS selector for targeting this span is span.score.
Modify the submission struct to add this CSS selector to it as well:
type submission struct {
Title string `selector:"span.titleline > a"`
URL string `selector:"span.titleline > a[href]" attr:"href"`
Site string `selector:"span.sitestr"`
Id string
Score string `selector:"span.score"`
Comments []*comment
}
Extracting ID
You can extract the ID by parsing the URL. This is what the URL of the submission page looks like:
https://news.ycombinator.com/item?id=36283249
You can use Colly to extract the value of the id parameter. To do so, update the OnHTML callback function and add the following code:
s.Id = e.Request.URL.Query().Get("id")
This code will parse the query parameters and their values from the request URL, extract the value of the id parameter, and populate the Id field of the submission struct.
Extracting Comment Author and Permalink
Right-click on the name of a comment author and explore the HTML. This is what it looks like:
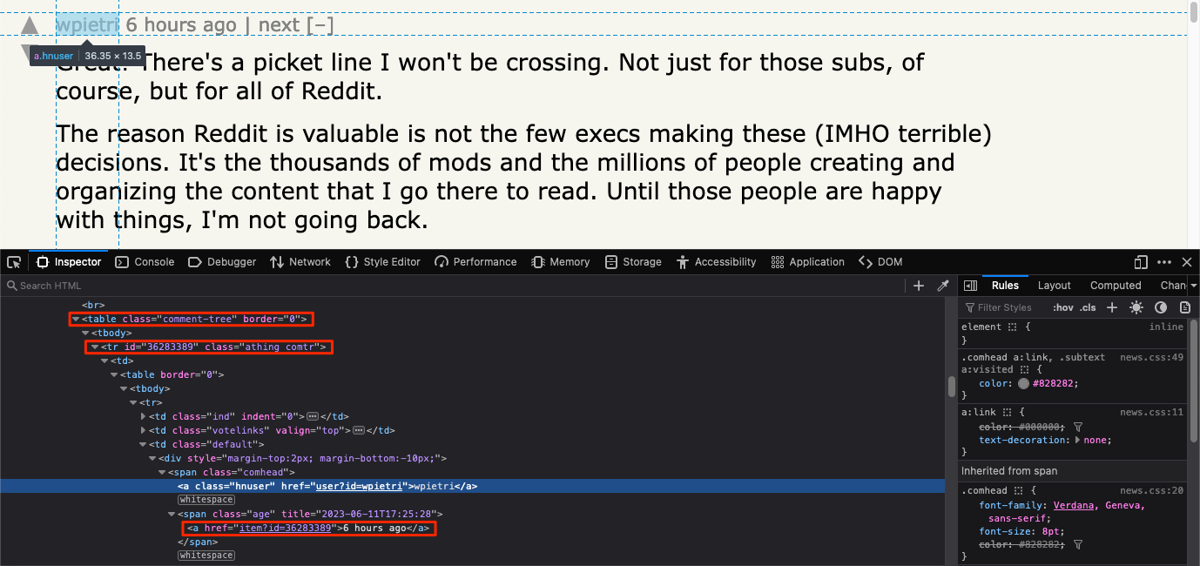
You can see from this screenshot that all comments are nested in a table with the class of comment-tree, and each comment is nested within a tr with a class of athing. The comment author's name is stored in a nested anchor tag with a class of hnuser, and the comment's permalink is stored as an href attribute of another anchor tag nested within a span with the class of age.
You can use the .comment-tree tr.athing CSS selector to extract the comment tags into a list. Then you'll use a.hnuser to extract the title and .age a to extract the permalink anchor from each list item. Colly's HTMLElement type provides a helpful ForEach method that takes a CSS selector as the first input and a callback function as the second input. This method will match all HTML elements on the page against the CSS selector and then run the callback function for each matching element.
Here is how you can update the fields of the comment struct with tags and use ForEach to Unmarshal data to them:
// Updated comment struct
type comment struct {
Author string `selector:"a.hnuser"`
Permalink string `selector:".age a[href]" attr:"href"`
Comment string
}
s := &submission{}
// Create and initialize a new comments slice
comments := make([]*comment, 0)
s.Comments = comments
// Updated OnHTML callback with nested ForEach loop
c.OnHTML("html", func(e *colly.HTMLElement) {
e.Unmarshal(s)
s.Id = e.Request.URL.Query().Get("id")
// Loop over the comment list
e.ForEach(".comment-tree tr.athing", func(i int, commentElement *colly.HTMLElement) {
c := &comment{}
commentElement.Unmarshal(c)
s.Comments = append(s.Comments, c)
})
})
Currently, the permalink will be unmarshaled as item?id=36283389, but you might want it as https://news.ycombinator.com/item?id=36283389. You can easily transform it with this code:
c.Permalink = commentElement.Request.AbsoluteURL(c.Permalink)
This code will convert the permalink into an absolute URL using the AbsoluteURL method provided by the Request type in Colly.
Extracting the Comment Text
You might be used to the workflow by now; right-click on the comment text and explore it within Developer Tools:
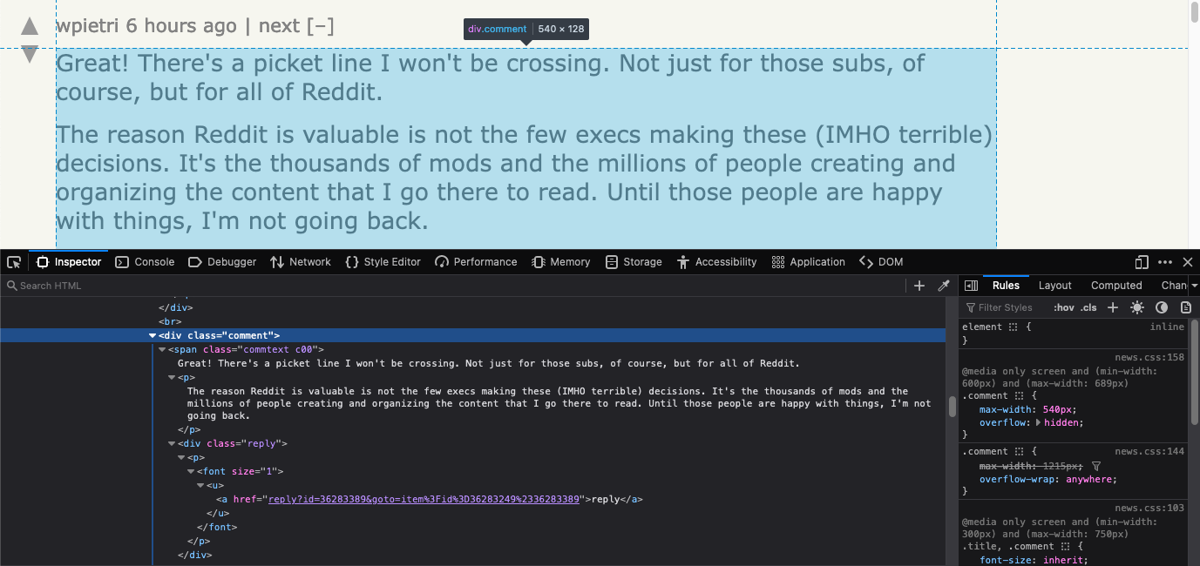
It seems as if the text is nested within a div with a class of comment. The Comment struct field can be tagged like this:
type comment struct {
// ...
Comment string `selector:".comment"`
}
There is one slight issue with this, though. The unmarshaled comment text will have some extra text at the end. This is because there are multiple nested tags within the comment div. This is what raw unmarshal looks like:
"Great! There's a picket line I won't be crossing. Not just for those subs, of course, but for all of Reddit.The reason Reddit is valuable is not the few execs making these (IMHO terrible) decisions. It's the thousands of mods and the millions of people creating and organizing the content that I go there to read. Until those people are happy with things, I'm not going back.\n \n reply"
Luckily, this extra text at the end is the same for each comment and can be removed with this bit of code:
c.Comment = strings.TrimSpace(c.Comment[:len(c.Comment)-5])
It will remove reply from the comment and then remove the whitespace at the end—exactly what you need!
Handling Pagination
Colly provides support for scraping multiple pages and visiting nested links. (It wouldn't have been as powerful as a scraper if it only allowed single-page scraping!) You need this support for handling pagination.
Hacker News supports listing only a limited number of comments on a page. You can view additional comments by clicking on an x more comments… button at the bottom of the page. This is what the HTML structure of that looks like:
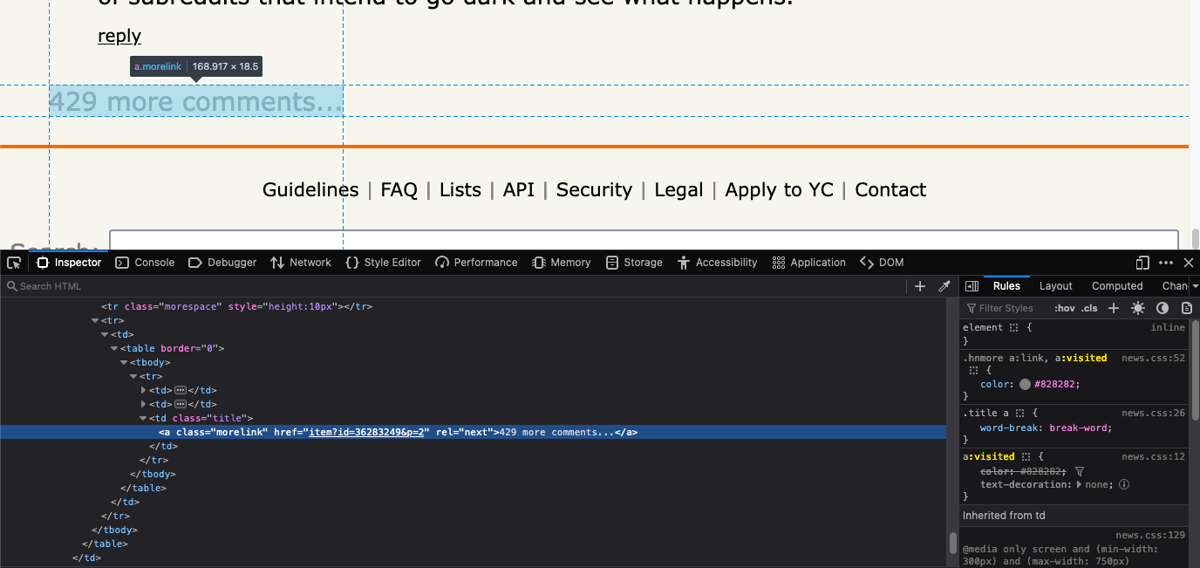
An additional OnHTML callback comes in very handy here. You can register a callback that clicks on this a.morelink tag whenever Colly encounters it. This is what the code for that will look like:
c.OnHTML("a.morelink", func(e *colly.HTMLElement) {
c.Visit(e.Request.AbsoluteURL(e.Attr("href")))
})
This callback will be executed whenever Colly gets to the very end of the page and there is a link to an additional comments page.
Putting It All Together
Congrats! You now have all the pieces to scrape all of the comments from a Hacker News submission.
Here is what your final code should look like:
package main
import (
"encoding/json"
"flag"
"os"
"strings"
"github.com/gocolly/colly"
)
type submission struct {
URL string `selector:"span.titleline > a[href]" attr:"href"`
Title string `selector:"span.titleline > a"`
Site string `selector:"span.sitestr"`
Id string
Score string `selector:"span.score"`
TotalComments int
Comments []*comment
}
type comment struct {
Author string `selector:"a.hnuser"`
Permalink string `selector:".age a[href]" attr:"href"`
Comment string `selector:".comment"`
}
func main() {
// Get the post id as input
var itemID string
flag.StringVar(&itemID, "id", "", "hackernews post id")
flag.Parse()
if itemID == "" {
println("Hackernews post id is required")
os.Exit(1)
}
s := &submission{}
comments := make([]*comment, 0)
s.Comments = comments
s.TotalComments = 0
// Instantiate default collector
c := colly.NewCollector()
c.OnHTML("html", func(e *colly.HTMLElement) {
// Unmarshal the submission struct only on the first page
if s.Id == "" {
e.Unmarshal(s)
}
s.Id = e.Request.URL.Query().Get("id")
// Loop over the comment list
e.ForEach(".comment-tree tr.athing", func(i int, commentElement *colly.HTMLElement) {
c := &comment{}
commentElement.Unmarshal(c)
c.Comment = strings.TrimSpace(c.Comment[:len(c.Comment)-5])
c.Permalink = commentElement.Request.AbsoluteURL(c.Permalink)
s.Comments = append(s.Comments, c)
s.TotalComments += 1
})
})
// Handle pagination
c.OnHTML("a.morelink", func(e *colly.HTMLElement) {
c.Visit(e.Request.AbsoluteURL(e.Attr("href")))
})
// Go to the submission page
c.Visit("https://news.ycombinator.com/item?id=" + itemID)
// Dump json to the standard output (terminal)
enc := json.NewEncoder(os.Stdout)
enc.SetIndent("", " ")
enc.Encode(s)
}
If you want to edit this code to associate each comment with its parent, you can look at some sample code here that has this logic.
One thing to note is that the final code listing has some additional code from what is covered in this tutorial. It contains the following logic for getting the ID of a Hacker News post as an argument from the terminal:
var itemID string
flag.StringVar(&itemID, "id", "", "hackernews post id")
flag.Parse()
if itemID == "" {
println("Hackernews post id is required")
os.Exit(1)
}
Due to this addition, you will have to run the script using this modified command:
go run hn.go -id 36283249
💡 Love scraping in GO? Check out our guide on how to use headless ChromeDP in GO to scrape dynamic websites.
Conclusion
In this tutorial, you learned about Colly and how its powerful callback-based execution model can be used to scrape simple websites. Do not let this article fool you, however! Colly is perfectly capable of scraping complex websites and SPAs.
The only downside is that Colly does not contain a full JavaScript execution engine, so you need to be creative when scraping JS-heavy websites. Colly's website has some helpful example scripts for scraping basic websites or Instagram and Google Groups. Go through them to get your creative juices flowing and to better understand how Colly handles different scraping scenarios.
One thing to note is that Hacker News does not implement rate limiting or crazy antibot measures against basic scrapers. This is why your scraper ended up being very simple and straightforward. However, antibot measures can quickly become a huge challenge when you undertake a scraping project of a decent size, so be prepared for it.
This is where our scraper API comes in. If you prefer not to have to deal with rate limits, proxies, user agents, and browser fingerprints, please check out its no-code web scraping API. And the first 1,000 calls are free!
Before you go, check out these related reads:

Yasoob is a renowned author, blogger and a tech speaker. He has authored the Intermediate Python and Practical Python Projects books ad writes regularly. He is currently working on Azure at Microsoft.


