APIs are the cornerstone of the modern internet as they enable different services to communicate with each other. With APIs, you can gather information from different sources and use different services. However, not all services provide an API for you to consume. Even if an API is offered, it might be limited in comparison to a service’s web application(s). Thankfully, you can use web scraping to overcome these limitations. Web scraping refers to the practice of extracting data from the HTML source of the web page. That is, instead of communicating with a server through APIs, web scraping lets you extract information directly from the web page itself.
Web scraping is often more accessible than using an API because with an API, you have to complete several additional steps: you need to get an API key, set up your script to make a request to the API with the correctly formatted request body, and finally, parse the response body to get the data you want. Then add in the time spent to read the API documentation and figure out the necessary details about the API, and you can see how this quickly becomes a hassle. With web scraping, however, you simply need to look at the HTML structure of the web page and determine which elements you want to extract the data from.
In this article, you’ll learn how to parse HTML from a web page in Ruby using the Nokogiri gem. You can find the code for this article in this GitHub repo.

What Is Nokogiri?
Nokogiri (鋸) is a lightweight Ruby gem that makes it easy to parse, build, and search HTML and XML documents. Nokogiri provides a DOM parser, SAX parser, and push parser, as well as the ability to search documents using Xpath and CSS3 selectors.
How to Extract Text from a Web Page Using Nokogiri
In this tutorial, you’ll scrape this web page, which provides a database of NHL team stats since 1990. You’ll build a web scraper that will let the user enter a search term and then display the stats for all teams matching the search.
Before you get your hands dirty with coding, spend some time on the web page. Specifically, you need to know how to find the elements you want in the HTML source code using CSS selectors.
Your first task is to get familiar with the way the web page works. Since you want to perform a search, you need to figure out what happens on the web page when you do so. Go ahead and enter a search. You’ll see that it redirects to a URL that looks like this:
https://www.scrapethissite.com/pages/forms/?q=<your_search_term>
This tells you the URL you need to scrape. Let’s get started!
To follow along with the tutorial, create a directory:
mkdir nokogiri-demo
cd nokogiri demo
Then, install Nokogiri:
gem install nokogiri
Create a file called sscrape.rb. Import the nokogiri and open-uri modules. The open-uri module is a convenience wrapper around the net/http module.
require 'nokogiri'
require 'open-uri'
Add the following lines to input the search term from the user:
puts "Enter a search term"
search_term = gets.chomp
Once you have the search term, you need to make a request to https://www.scrapethissite.com/pages/forms/?q=<search_term>. The URI.open method makes the request and returns the HTML of the page, which is then passed to the Nokogiri::HTML5 class that returns a Document:
doc = Nokogiri::HTML5(URI.open("https://www.scrapethissite.com/pages/forms/?q=#{search_term}"))
To extract text from a particular element on the page, you first need a way to select the element. Using a CSS selector is the easiest way to go about this.
To look at the source code of the page, press CTRL+Shift+I to open up the developer console and click on the tiny mouse pointer:
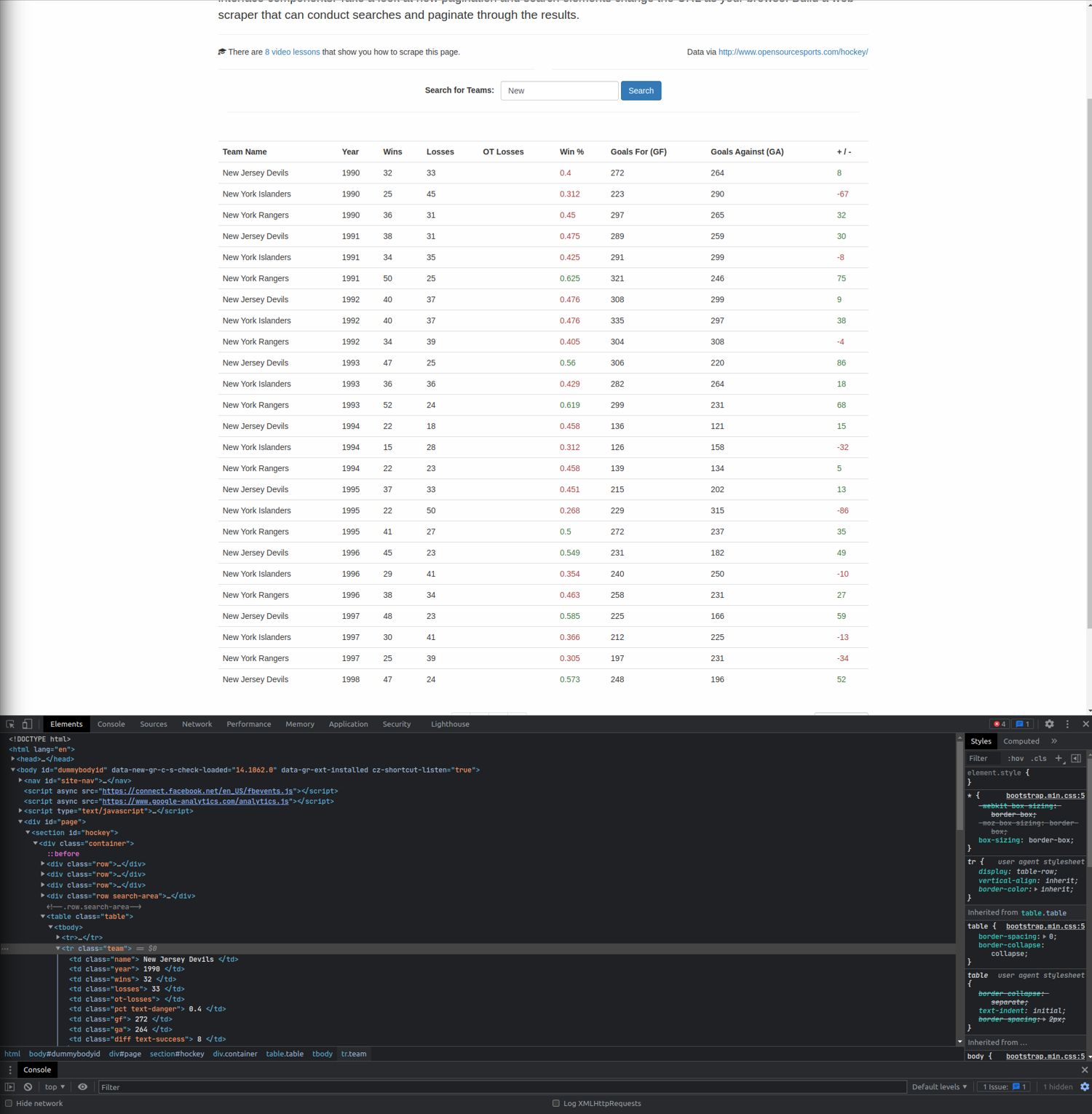
You can now hover your mouse over any element, and it will be highlighted in the HTML source. Hover over a single team to find out its HTML structure.
You can see that the data is inside a <table> tag, where each team is in a separate <tr> tag. Each team also has a class team.
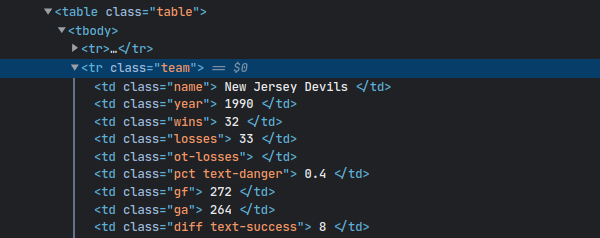
From this, you can infer the CSS selector required to select the data: tr.team. The css method takes the CSS selector and returns a NodeSet of elements matching the query. Then you can simply iterate over the elements using the each method.
For every team, their name is stored in a <td> tag with a class name. Since there is only one element with class name inside each team, you can use the at method to get the element. Like the css method, the at method finds elements with a given CSS selector but returns only the first element.
Once you have the element, you can extract its text using the content method:
doc.css("tr.team").each do |team|
puts team.at(".name").content.strip
end
Run the code using ruby scrape.rb, and enter a search term when prompted. You should see the names of the teams matching the search query:
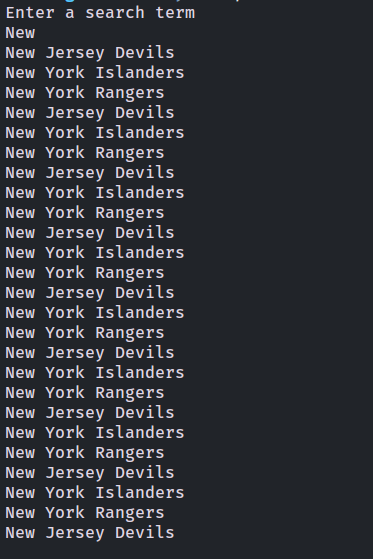
Let’s go one step further and extract more information. How about the total wins of each team?
Going back to the page source, the number of wins for each team is stored in a <td> element with a class wins. Like the name, you can use the at method to extract it. Here’s the code to do so:
require 'nokogiri'
require 'open-uri'
puts "Enter a search term"
search_term = gets.chomp
doc = Nokogiri::HTML5(URI.open("https://www.scrapethissite.com/pages/forms/?q=#{search_term}"))
teams = {}
doc.css("tr.team").each do |team|
team_name = team.at(".name").content.strip
team_wins = team.at(".wins").content.to_i
teams[team_name] ||= 0
teams[team_name] += team_wins
end
teams.each do |team_name, team_wins|
puts "#{team_name} => #{team_wins}"
end
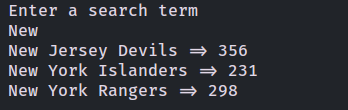
Here, a hash named teams has been defined to store the scores. First, the code checks if the team name is already in the hash. If it is, the number of wins is added to the existing score. If it isn’t, the score is initialized to 0.
Run the script and enter a search term. You will see the total wins of each team:
Handling Pagination
Your code can now successfully extract text from the web page. But this is just the first page. Let’s take the script to the next level by adding the ability to handle pagination.
The code starts similarly—by importing the required modules, prompting the user for a search term, and making a request to the first page:
require 'nokogiri'
require 'open-uri'
puts "Enter a search term"
search_term = gets.chomp
doc = Nokogiri::HTML5(URI.open("https://www.scrapethissite.com/pages/forms/?q=#{search_term}"))
To handle pagination, you need to know the total number of pages. A quick peek to the page source reveals that the links to the pages are stored as <a> tags inside <li> tags inside a <ul> tag with a class pagination.
The number of pages is the last number that occurs in this list, which is the second to last <li> tag. (The last <li> is the link to the last page but doesn’t contain the page number.)
The following code extracts the second to last element as well as the page number:
pages = doc.css(".pagination a")[-2].content.to_i
As before, create a teams hash:
teams = {}
Then create a loop that will run from 1 to pages.
(1..pages).each do |page_num|
puts "Scraping page #{page_num}"
end
This time, the URL will be slightly different. If you visit any page (other than the first one) in your browser, you’ll see a page_num query parameter added to the URL. This parameter is the page number you want to view. You’ll land on the first page if you set page_num to 1. This is a huge relief, as you don’t need to handle the first page differently.
Add the following code to the each loop. Note that this code is the same as what you did previously. The only difference is that this time, it is executed for each page.
(1..pages).each do |page_num|
puts "Scraping page #{page_num}"
doc = Nokogiri::HTML5(URI.open("https://www.scrapethissite.com/pages/forms/?q=#{search_term}&page_num=#{page_num}"))
doc.css("tr.team").each do |team|
team_name = team.at(".name").content.strip
team_wins = team.at(".wins").content.to_i
teams[team_name] ||= 0
teams[team_name] += team_wins
end
end
Finally, print the result:
teams.each do |team_name, team_wins|
puts "#{team_name} => #{team_wins}"
end
Here’s the complete code:
require 'nokogiri'
require 'open-uri'
puts "Enter a search term"
search_term = gets.chomp
doc = Nokogiri::HTML(URI.open("https://www.scrapethissite.com/pages/forms/?q=#{search_term}"))
pages = doc.css(".pagination a")[-2].content.to_i
teams = {}
(1..pages).each do |page_num|
puts "Scraping page #{page_num}"
doc = Nokogiri::HTML(URI.open("https://www.scrapethissite.com/pages/forms/?q=#{search_term}&page_num=#{page_num}"))
doc.css("tr.team").each do |team|
team_name = team.at(".name").content.strip
team_wins = team.at(".wins").content.to_i
teams[team_name] ||= 0
teams[team_name] += team_wins
end
end
teams.each do |team_name, team_wins|
puts "#{team_name} => #{team_wins}"
end
Run the code, and you’ll see that it now scrapes each page and provides each team’s total number of wins:
To check out the final code, you can access this GitHub repository.
Conclusion
As you’ve seen, web scraping is a powerful tool that you can use to extract text from a web page. You can use it in the absence of an API, or you can use it to overcome an API’s limitations. In this tutorial, you learned how to use the Nokogiri gem to scrape a web page and extract text.
Even though Nokogiri is lightweight and simple, there are some use cases that are outside its scope. For example, if you’re scraping a dynamic web page that runs JavaScript, Nokogiri will not be able to do the job because it can’t execute JavaScript. In that case, a sophisticated tool like Watir may be more suitable.
If you’re looking for a fast, powerful, and easy-to-use web scraping tool, be sure to check out our scraper API. It handles headless browsers at scale and rotates proxies, giving you an unmatched and uninterrupted web scraping experience.
Before you go, check out these related reads:

Aniket is a student doing a Master's in Mathematics and has a passion for computers and software. He likes to explore various areas related to coding and works as a web developer using Ruby on Rails and Vue.JS.


