The amount of information available on the internet for human consumption is astounding. However, if this data doesn't come in the form of a specialized REST API, it can be challenging to access programmatically. The technique of gathering and processing raw data from the internet is known as web scraping. There are several uses for web scraping in software development. Data collected through web scraping can be applied in market research, lead generation, competitive intelligence, product pricing comparison, monitoring consumer sentiment, brand audits, AI and machine learning, creating a job board, and more.
Utilizing an HTML parser that is specifically made for parsing out HTML pages is simpler than parsing with custom written programming logic. There are several tools available for web scraping using HTML parsers. Beautiful Soup is one such library that works with the HTML parser of your choice for web scraping. Some prefer to parse HTML pages with regex, as it is lightweight and comes out of the box with many programming languages—you don’t have to install any separate dependencies. Also, if you deal with simple, well-formatted HTML pages, implementing a regex-based parsing solution is pretty straightforward.
A regular expression (often abbreviated as regex) is a string of letters that designates a text search pattern. Regular expressions are used in lexical analysis, word processors’ search-and-replace dialogues, text editors' search-and-replace functions, and text processing tools like sed and AWK.
In this article, you will learn how to parse HTML with regex in Python. In the tutorial, you will download the contents of a website, search for required data, and explore some specific use cases of parsing HTML content using regex. Then you’ll review some challenges involved in using regex for parsing arbitrary HTML and learn about alternative solutions.

Parsing With Regex
Regex support is provided by the majority of general-purpose programming languages, including Python, C, C++, Java, Rust, and JavaScript, either natively or through libraries.
The following snippet is a simple regex syntax in Python that can be used to find the string pattern “” in a given text:
import re
re.findall("<img>", "<img> : This is an image tag")
Note: All the source code in this tutorial was developed and executed in Python 3.8.10, but it should work on any machine with Python 3+.
In the example above, the module re is used for performing operations related to regular expressions. findall is a function in the re module that is used for returning a list of all matches of a given pattern (first argument value: <img>) in the given string (second argument value: <img> : This is an image tag).
One straightforward way of parsing HTML is using regular expressions to constantly look for and extract substrings that match a specific pattern. When your HTML is well-formatted and predictable, regular expressions function quite effectively. Imagine you have an HTML file, simple.html, with the following code in it:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Simple HTML File</title>
</head>
<body>
<h1>Tutorial on How to Parse HTML with Regex</h1>
<p>This is a sample html file used as an example</p>
</body>
</html>
Say you’d like to extract the information contained within the <title> tags. With Python, you could use the following syntax to do so:
import re
matched = re.compile('<title>').search
with open("simple.html", "r") as input_file:
for line in input_file:
if matched(line):
print(line.replace("<title>", "").replace("</title>", ""))
Place this Python script file, simple-html-parser.py, in the same location as that of the simple.html file and run it to get the output, as shown here:
python .\simple-html-parser.py
Simple HTML File
In the above Python code, a regular expression pattern provided as a string is converted into a regex pattern object using Python's re.compile() function. You can utilize this pattern object to look for matches within various target strings. In this case, the target is the line read from the simple.html file. Once the pattern is matched, the <title> tags are removed, as the goal is to extract only the string between the <title> tag.
Although regex allows you to quickly build a parser for simple and well-formed HTML sites, a parser application that exclusively uses regular expressions may either overlook some valid links or produce inaccurate data when being used to parse arbitrary HTML pages.
Some websites may use nested tags—an HTML element placed inside another HTML element—in their HTML pages. At times, the nesting can go at multiple levels. If you want to parse for certain information from a particular level, it can be complex to do so and may result in errors.
While using regex for parsing HTML has some limitations, it allows you to build a quick solution and serves well for use cases like parsing simple HTML pages, filtering out a certain tag/groups of tags from an HTML page, or for extracting a particular text pattern within a tag.
Implementing HTML Parsing Using Regex
Now that you understand how regex-based HTML parsing works at a high level, read on to learn how to do it.
Download the Contents of a Website
To start, you’ll download site content onto your local machine. For this tutorial, you can use the PyPI site's URL. Create a Python file named download-site-content.py and paste in the following code:
import urllib.request
URL = "https://pypi.org/"
HTML_FILE = "file.html"
def write_html_of_given_url_to_file(input_url: str):
urllib.request.urlretrieve(input_url, HTML_FILE)
write_html_of_given_url_to_file(URL)
This is a simple program to understand. The method write_html_of_given_url_to_file accepts the input URL of the PyPI site and uses the urlretrieve method of the urllib.request module to retrieve the site content and write it into the given file name, file.html. The output HTML file will be created in the same directory where you placed the Python script.
Search for Required Data Using Regex
Earlier, you saw an example of how to extract the information within the <title> tag of a simple HTML file. Now, you will see a more complicated use case. You’ll search for one of the key stats on the PyPI site, such as the number of projects published:
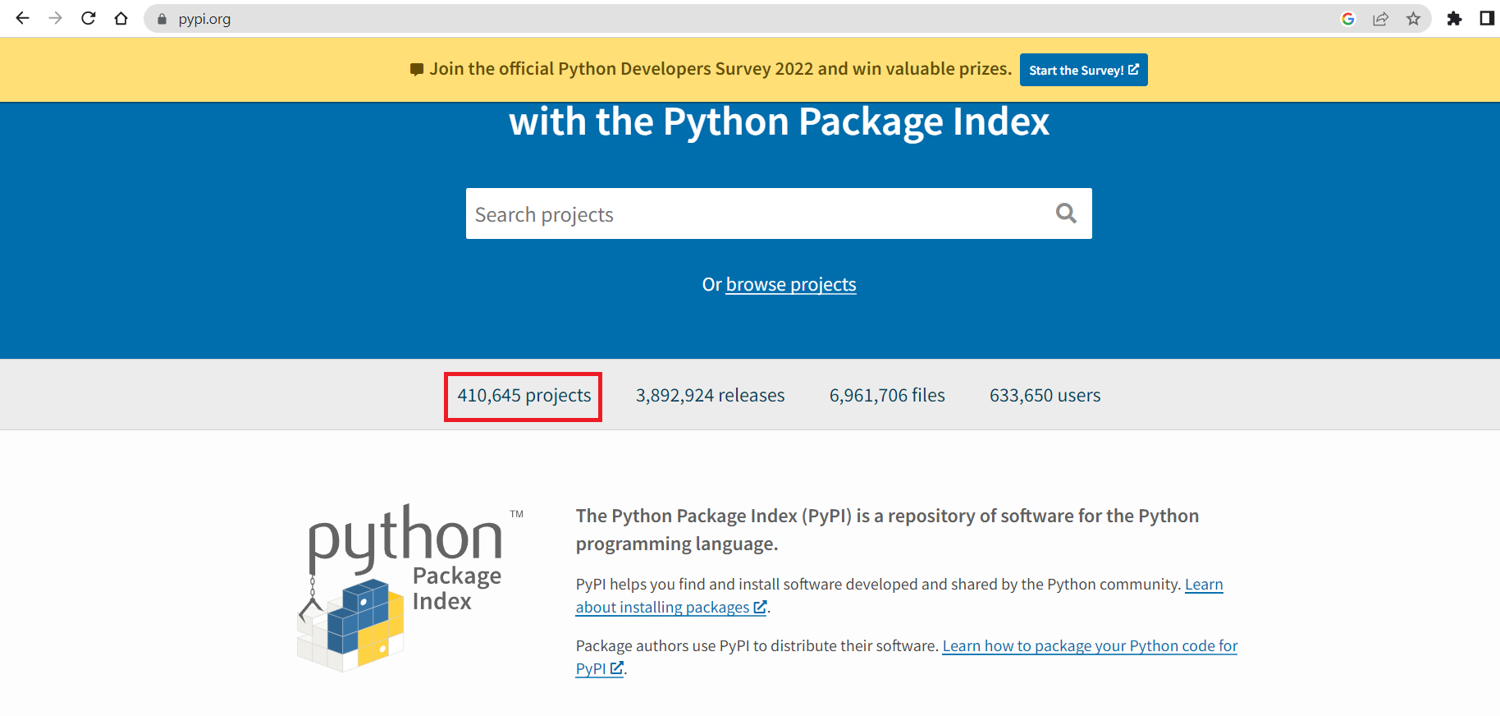
As you can see in the screenshot, there are multiple stats published on the PyPI site—the total number of projects, releases, users, and more. Among these, you want to extract only the information about the total number of projects. If you view the source code of the html file you downloaded earlier, file.html, you’ll notice that this stat is included as part of a <p> tag present inside a <div> tag:
<div class="horizontal-section horizontal-section--grey horizontal-section--thin horizontal-section--statistics">
<div class="statistics-bar">
<p class="statistics-bar__statistic">
410,645 projects
</p>
<p class="statistics-bar__statistic">
3,892,920 releases
</p>
<p class="statistics-bar__statistic">
6,961,696 files
</p>
<p class="statistics-bar__statistic">
633,650 users
</p>
</div>
</div>
You’ll also notice that there are multiple instances of the word “projects” in file.html. The challenge is to extract only the required stat—in this case, 410,645 projects. To do so, copy and paste the following code in a Python file named print-total-number-of-projects.py:
import re
import urllib.request
URL = "https://pypi.org/"
def get_html(input_url: str) -> bytes:
html = urllib.request.urlopen(input_url).read()
return html
def print_projects_count(input_url: str) -> None:
html = get_html(input_url)
stats = re.findall(b'\\d+,?\\d+,?\\d+\\s+projects', html)
print("\n ***** Printing Projects Count ***** \n")
for stat in stats:
print(stat.decode())
print_projects_count(URL)
Here, print_projects_count is called with the PyPI site URL as input. This method in turn uses the get_html method to read the site content and returns the html bytes to the caller method. print_projects_count then uses a regex pattern to get the list of all matches for the supplied pattern. The regex pattern, b'\\d+,?\\d+,?\\d+\\s+projects', is the key in finding the total number of projects:
bstands for bytes\\d+stands for one or more numbers,stands for comma, as the stats published in the PyPI site use commas as a separator?stands for zero or one-time match of the previous token; in this case, the previous token is,\\s+stands for one or more spacesprojectsis just the string
Since the return type of findall is a list, an iteration of the list is performed to print the project stats to the terminal output.
When you run the script, you should see an output like this:
python .\print-total-number-of-projects.py
***** Printing Projects Count *****
410,645 projects
Extract Links
Now that you understand the basics of parsing HTML with regex, see if you can program to extract links (any https- or http-referenced URLs) from the same site. You have all the help you need from the earlier sections; now all you have to do is find the right regular expression for your goal of extracting the http(s) URLs.
You can consider this as an exercise to carry out, or refer to the source code below for the answer:
import re
import urllib.request
URL = "https://pypi.org/"
def get_html(input_url: str) -> bytes:
html = urllib.request.urlopen(input_url).read()
return html
def get_all_referenced_urls(input_url: str) -> list:
links_list = []
html = get_html(input_url)
referenced_urls = re.findall(b'href="(https?://.*?)"', html)
print("\n ***** Printing all http(s) URLs ***** \n")
for referenced_url in referenced_urls:
print(referenced_url.decode())
links_list.append(referenced_url.decode())
return links_list
get_all_referenced_urls(URL)
When you copy and paste the above code into a file named extract-link.py and run the script using the command python extract-links.py, you’ll get the list of referenced URL links from the PyPI site.
Filter Empty Tags
HTML supports empty tags—that is, tags that can’t have any nested tags or child nodes. These empty tags are also known as void elements. They usually have a start tag but don’t need an end tag as non-empty tags do. Even if you have specified an end tag in the HTML page for such empty tags, the browser won’t throw an error. You can refer to this article for more information and to see the full list of empty tags in HTML.
Say you want to filter out these empty tags from the PyPI site’s downloaded HTML file. How would you go about it? Copy and paste the code below into a file, filter-empty-tags-from-html.py:
import os
import re
import shutil
import urllib.request
URL = "https://pypi.org/"
HTML_FILE = "file.html"
ALTERED_HTML_FILE = "altered-file.html"
# Source of Empty tags list or Void elements list :
# https://developer.mozilla.org/en-US/docs/Glossary/Void_element
EMPTY_TAGS_LIST = ["area", "base", "br", "col", "embed", "hr", "img", "input", "keygen", "link", "meta", "param",
"source", "track", "wbr"]
def write_html_of_given_url_to_file(input_url: str):
urllib.request.urlretrieve(input_url, HTML_FILE)
def filter_empty_tags(input_file, output_file):
"""
Accepts two files as input. One will be considered as input and the other will be for writing the output which
will store html contents from input file except that of empty tags
:param input_file:
:param output_file:
:return:
"""
shutil.copyfile(input_file, output_file)
for empty_tag in EMPTY_TAGS_LIST:
remove_empty_tag_from_html(output_file, empty_tag)
def remove_empty_tag_from_html(input_file, empty_tag_element: str):
matched = re.compile('<' + empty_tag_element).search
with open(input_file, "r", encoding="utf-8") as file:
with open('temp.html', 'w', encoding="utf-8") as output_file:
for line in file:
if not matched(line): # save lines that do not match
print(line, end='', file=output_file) # this goes to filename due to inplace=1
os.replace('temp.html', input_file)
write_html_of_given_url_to_file(URL)
filter_empty_tags(HTML_FILE, ALTERED_HTML_FILE)
Run the following command:
python filter-empty-tags-from-html.py
This will create two files in the directory where you have placed and executed the above Python script. The original downloaded content of the PyPI site is contained in file.html and the modified HTML content (after filtering out the empty tags) is contained in altered-file.html.
Filter Comments
Using a similar method, you can filter the comments from the HTML page. Comments in HTML are represented as follows:
<!-- I am a HTML comment -->
You can try this for yourself based on what you’ve learned so far. Or, if you want the source code for this use case, copy and paste the Python script below in a file named filter-comments-from-html.py:
import os
import re
import urllib.request
URL = "https://pypi.org/"
HTML_FILE = "file.html"
ALTERED_HTML_FILE = "altered-file.html"
def write_html_of_given_url_to_file(input_url: str):
urllib.request.urlretrieve(input_url, HTML_FILE)
def remove_comments_from_html(input_file, output_file):
matched = re.compile('<!--').search
with open(input_file, "r", encoding="utf-8") as file:
with open('temp.html', 'w', encoding="utf-8") as temp_file:
for line in file:
if not matched(line): # save lines that do not match
print(line, end='', file=temp_file) # this goes to filename due to inplace=1
os.replace('temp.html', output_file)
write_html_of_given_url_to_file(URL)
remove_comments_from_html(HTML_FILE, ALTERED_HTML_FILE)
Then run it using the command python filter-comments-from-html.py. This script filters out the HTML comments from the downloaded site content.
How Regex Fails With Arbitrary HTML
So far, you’ve explored how regex can be used to parse an HTML page. However, if you need to parse an arbitrary HTML with irregular tags or no standard format, you’ll see that regex misses some important information.
Create a sample html file, arbitrary-html-file.html, with the following content:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Arbitrary HTML</title>
</head>
<body>
<div id="1">
<h1>Heading 1 of Section 1</h1>
<h2>Heading 2 of Section 1</h2>
<h3>Heading 3 of Section 1</h3>
</div>
<div id="2">
<h1>Heading 1 of Section 2</h1>
<h2>Heading 2 of Section 2</h2>
<h3>Heading 3 of Section 2</h3>
</div>
<div id="3">
<h1>Heading 1 of Section 3</h1>
<h2>
<p>Heading 2 of Section 3</p>
<br>
</h2>
<h3>Heading 3 of Section 3</h3>
</div>
</body>
</html>
Notice that the <h2> tag of the third <div> is nested with child tags, <p>, and an empty tag, <br>. If your goal is to extract all the information available as part of all <h2> tags, such an HTML format would present a challenge.
Copy and paste the following code into a file named regex-failure-with-arbitrary-html.py:
import re
ARBITRARY_HTML_FILE = "./arbitrary-html-file.html"
def extract_h2_info_from_arbitrary_html_file(input_file):
matched = re.compile("(<h2>(.*)</h2>)").search
with open(ARBITRARY_HTML_FILE, "r") as input_file:
for line in input_file:
if matched(line):
print(line)
extract_h2_info_from_arbitrary_html_file(ARBITRARY_HTML_FILE)
Both of these files—arbitrary-html-file.html and regex-failure-with-arbitrary-html.py—should be present in the same directory. Now run the following:
python regex-failure-with-arbitrary-html.py
You will get an output like this:
<h2>Heading 2 of Section 1</h2>
<h2>Heading 2 of Section 2</h2>
Notice that the information in the third <h2> tag is not able to be retrieved using the regex parser, as the page content is non-standard and has a different format than the other <h2> tags—the current regex expression cannot handle it. You can introduce custom rules to process such cases, but there's no standard recommended solution, which makes parsing using regex difficult. To simplify things, you can use an alternative solution like ScrapingBee, BeautifulSoup, JSoup, or Selenium.
ScrapingBee is a web scraping platform that can help you with general-purpose projects—like extracting reviews or testimonials from a site, real estate scraping, or price tracking—all without getting blocked by the entity hosting or managing the site. It can also help with more advanced cases of web scraping, like extracting information from nested elements, extracting attributes, or scraping the resulting pages of a search engine. The ScrapingBee API works brilliantly to make your data extraction work effortless to improve your team’s productivity. Also, for non-coders, ScrapingBee has its no-code web scraping feature, by which even business users can scrape their target sites with ease. You can check out this blog to learn more about no-code web scraping.
Conclusion
Web scraping is incredibly useful in extracting information that can help your business in decision-making or even automating certain business strategies. For instance, pricing your products competitively by comparing your product prices to those on competitors' sites doesn’t have to require manual action.
In this article, you learned about web scraping’s use cases in several domains. You carried out HTML parsing yourself by downloading content from a site and extracting information like links and string patterns from it using regex. You also learned how to filter for empty tags and comments.
Regex can be great for HTML parsing, but it has its limitations. To parse and extract data from arbitrary HTML, consider using an alternative solution like ScrapingBee to make things fast and easy.
All of the source code from this article can be found in this GitHub repo.

Rajkumar has nearly sixteen years of experience in the software industry as a developer, data modeler, tester, project lead. Currently, he is a principal architect at an MNC.
