In this tutorial, we are going to see how to extract product data from any E-commerce websites with Java. There are lots of different use cases for product data extraction, such as:
- E-commerce price monitoring
- Price comparator
- Availability monitoring
- Extracting reviews
- Market research
- MAP violation
We are going to extract these different fields: Price, Product Name, Image URL, SKU, and currency from this product page:
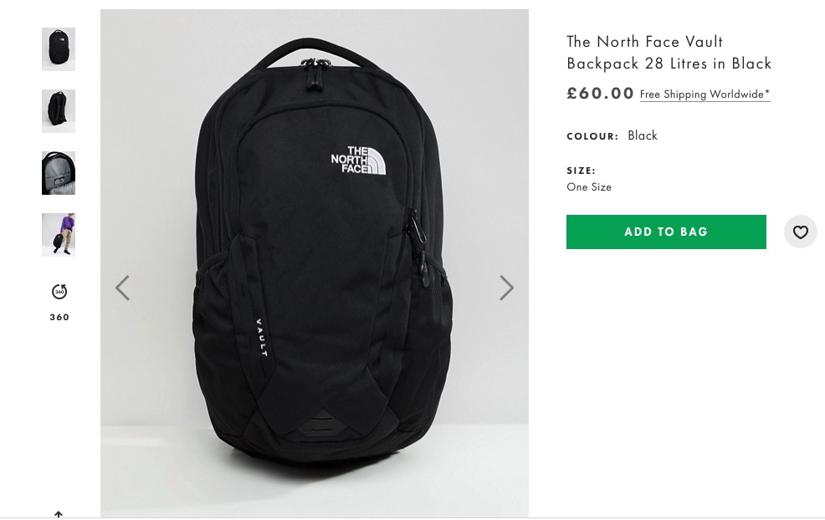
What you will need
We will use HtmlUnit to perform the HTTP request and parse the DOM, add this dependency to your pom.xml.
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.19</version>
</dependency>
We will also use the Jackson library:
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.8</version>
</dependency>
Schema.org
In order to extract the fields we're interested in, we are going to parse https://schema.org metadata from the Html markup.
Schema is a semantic vocabulary that can be added to any webpage. There are many benefits of implementing Schema. Most search engines use it to understand what a page is about (A Product, an Article, a Review, and many more )
According to schema.org, about 10 million websites use it worldwide. That's huge! There are different types of Schema, and today we're going to look at the Product type
It's really convenient because once you wrote a scraper that extracts specific schema data, it will work on any other website using the same schema. No more specific XPath / CSS selectors to write!
In my experience at PricingBot (my previous company), about 40% of E-commerce websites use schema.org metadata in their DOM.
There are three main schema markups:
JSON-LD
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "ItemList",
"url": "http://multivarki.ru?filters%5Bprice%5D%5BLTE%5D=39600",
"numberOfItems": "315",
"itemListElement": [
{
"@type": "Product",
"image": "http://img01.multivarki.ru.ru/c9/f1/a5fe6642-18d0-47ad-b038-6fca20f1c923.jpeg",
"url": "http://multivarki.ru/brand_502/",
"name": "Brand 502",
"offers": {
"@type": "Offer",
"price": "4399 p."
}
},
{
"@type": "Product",
"name": "..."
}
]
}
</script>
RDF-A
<div vocab="http://schema.org/" typeof="ItemList">
<link property="url" href="http://multivarki.ru?filters%5Bprice%5D%5BLTE%5D=39600"><span property="numberOfItems">315</span>
<div property="itemListElement" typeof="Product">
<img property="image" alt="Photo of product" src="http://img01.multivarki.ru.ru/c9/f1/a5fe6642-18d0-47ad-b038-6fca20f1c923.jpeg"> <a property="url" href="http://multivarki.ru/brand_502/"><span property="name">BRAND 502</span></a>
<div property="offers" typeof="http://schema.org/Offer">
<meta property="schema:priceCurrency" content="RUB">руб
<meta property="schema:price" content="4399.00">4 399,00
<link property="schema:itemCondition" href="http://schema.org/NewCondition">
</div>...
<div property="itemListElement" typeof="Product">
...
</div>
</div>
</div>
And the one used in our example, Microdata:
<div class="schema-org">
<div itemscope="" itemtype="https://schema.org/Product">
<img itemprop="image" src="https://images.asos-media.com/products/the-north-face-vault-backpack-28-litres-in-black/10253008-1-black" alt="Image 1 of The North Face Vault Backpack 28 Litres in Black">
<link itemprop="itemCondition" href="https://schema.org/NewCondition">
<span itemprop="productID">10253008</span>
<span itemprop="sku">10253008</span>
<span itemprop="brand" itemscope="" itemtype="https://schema.org/Brand">
<span itemprop="name">The North Face</span>
</span>
<span itemprop="name">The North Face Vault Backpack 28 Litres in Black</span>
<span itemprop="description">Shop The North Face Vault Backpack 28 Litres in Black at ASOS. Discover fashion online.</span>
<span itemprop="offers" itemscope="" itemtype="https://schema.org/Offer">
<link itemprop="availability" href="https://schema.org/InStock">
<meta itemprop="priceCurrency" content="GBP">
<span itemprop="price">60</span>
<span itemprop="eligibleRegion">GB</span>
<span itemprop="seller" itemscope="" itemtype="https://schema.org/Organization">
<span itemprop="name">ASOS</span>
</span>
</span>
</div>
</div>
Note that you can have multiple offers in a single page.
totoExtracting the data
The first thing is to create a basic POJO of a Product:
public class Product {
private BigDecimal price;
private String name;
private String sku;
private URL imageUrl;
private String currency;
// ...getters & setters
Then we need to go to the target URL and create a basic microdata parser to extract the fields we are interested in. I'm using HtmlUnit for this, which is a pure Java headless browser. I could have used lots of different libraries like Jsoup or Selenium + Headless Chrome.
But in most cases, HtmlUnit is a good solution because it's lighter than Selenium + Headless Chrome, but offer more features than a raw HTTP client + JSoup (which only handles Html parsing).
For "Javascript-heavy" websites, relying on frontend frameworks like React / Vue.js, Headless Chrome is the way to go!
WebClient client = new WebClient();
client.getOptions().setCssEnabled(false);
client.getOptions().setJavaScriptEnabled(false);
String productUrl = "https://www.asos.com/the-north-face/the-north-face-vault-backpack-28-litres-in-black/prd/10253008";
HtmlPage page = client.getPage(productUrl);
HtmlElement productNode = ((HtmlElement) page
.getFirstByXPath("//*[@itemtype='https://schema.org/Product']"));
URL imageUrl = new URL((((HtmlElement) productNode.getFirstByXPath("./img")))
.getAttribute("src"));
HtmlElement offers = ((HtmlElement) productNode.getFirstByXPath("./span[@itemprop='offers']"));
BigDecimal price = new BigDecimal(((HtmlElement) offers.getFirstByXPath("./span[@itemprop='price']")).asText());
String productName = (((HtmlElement) productNode.getFirstByXPath("./span[@itemprop='name']")).asText());
String currency = (((HtmlElement) offers.getFirstByXPath("./*[@itemprop='priceCurrency']")).getAttribute("content"));
String productSKU = (((HtmlElement) productNode.getFirstByXPath("./span[@itemprop='sku']")).asText());
On the first lines, I created the HtmlUnit HTTP client and disabled Javascript because we don't need it to get the Schema markup.
Then it's just basic XPath expressions to select the interesting DOM nodes we want.
This parser is far from perfect, it doesn't extract everything and it doesn't handle multiple offers. However, this will give you an idea about how to extract Schema data.
We can then create the Product object, and print it as a JSON string:
Product product = new Product(price, productName, productSKU, imageUrl, currency);
ObjectMapper mapper = new ObjectMapper();
String jsonString = mapper.writeValueAsString(product) ;
System.out.println(jsonString);
Avoid getting blocked
Now that we are able to extract the product data we want, we have to be careful not to get blocked.
For various reasons, there are sometimes anti-bot mechanisms implemented on websites. The most obvious reason to protect sites from bots is to prevent heavy automated traffic to impact a website’s performance (and you must be careful with concurrent requests, by adding delays...). Another reason is to stop bad behavior from bots like spam.
There are various protection mechanisms. Sometime your bot will be blocked if it does too many requests per second/hour/ day. Sometimes there is a rate limit on how many requests per IP address. The most difficult protection is when there is a user behavior analysis. For example, the website could analyze the time between requests, if the same IP is making requests concurrently.
The easiest solution to hide our scrapers is to use proxies. In combination with random user-agent, using a proxy is a powerful method to hide our scrapers, and scrape rate-limited web pages. Of course, it’s better not be blocked in the first place, but sometimes websites allow only a certain amount of request per day/hour.
In these cases, you should use a proxy. There are lots of free proxy list, I don’t recommend using these because there are often slow, unreliable, and websites offering these lists are not always transparent about where these proxies are located. Sometimes the public proxy list is operated by a legit company, offering premium proxies, and sometimes not...
What I recommend is using a paid proxy service, or you could build your own.
Setting a proxy to HtmlUnit is easy:
ProxyConfig proxyConfig = new ProxyConfig("host", myPort);
client.getOptions().setProxyConfig(proxyConfig);
Go further
As you can see, thanks to Schema.org data, extracting product data is much easier now than it was ten years ago.
But there are still challenges such as handling websites that haven't implemented Schema, handling IP blocking and rate limits, rendering Javascript...
That is exactly why we've been working with my partner Pierre on a Web Scraping API
ScrapingBee is an API to extract any HTML from any website without having to deal with proxies, CAPTCHAs and headless browsers. A single API call, with only the product URL you to want to extract data from.
I hope you enjoyed this post, as always you can find the full code in this Github repository: https://github.com/ksahin/introWebScraping
💡 Want to learn more about scraping e-commerce data? Check out our guides on scraping minimum advertised prices and How to scrape e-commerce websites
Before you go, check out these related reads:

Kevin worked in the web scraping industry for 10 years before co-founding ScrapingBee. He is also the author of the Java Web Scraping Handbook.