Serverless is a term referring to the execution of code inside ephemeral containers (Function As A Service, or FaaS). It is a hot topic in 2019, after the “micro-service” hype, here come the “nano-services”!
Cloud functions can be triggered by different things such as:
- An HTTP call to a REST API
- A job in a message queue
- A log
- IOT event
Cloud functions are a really good fit with web scraping tasks for many reasons. Web Scraping is I/O bound, most of the time is spent waiting for HTTP responses, so we don’t need high-end CPU servers. Cloud functions are cheap (first 1M request is free, then $0.20 per million requests) and easy to set up. Cloud functions are a good fit for parallel scraping, we can create hundreds or thousands of function at the same time for large-scale scraping.
In this introduction, we are going to see how to deploy a slightly modified version of the Craigslist scraper we made on a previous blogpost on AWS Lambda using the serverless framework.

Prerequisites
We are going to use the Serverless framework to build and deploy our project to AWS lambda. Serverless CLI is able to generate lots of boilerplate code in different languages and deploy the code to different cloud providers, like AWS, Google Cloud or Azure.
- An AWS account
- Node and npm
- Serverless CLI and Setup your AWS credentials
- Java 8
- Maven
Architecture
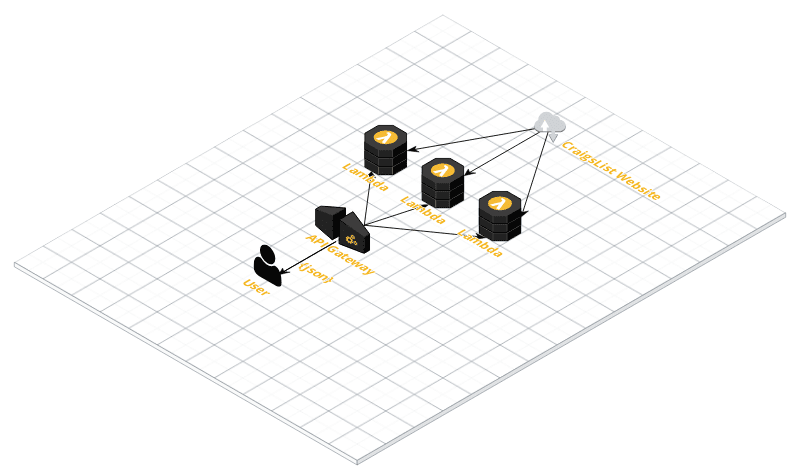
We will build an API using API Gateway with a single endpoint /items/{query} binded on a lambda function that will respond to us with a JSON array with all items (on the first result page) for this query.
Here is a simple diagram for this architecture:
Create the Maven project
Serverless is able to generate projects in lots of different languages: Java, Python, NodeJS, Scala... We are going to use one of these templates to generate a maven project:
serverless create --template aws-java-maven --name items-api -p aws-java-scraper
You can now open this Maven project in your favorite IDE.
Configuration
The first thing to do is to change the serverless.yml config to implement an API gateway route and bind it to the handleRequest method in the Handler.java class.
service: craigslist-scraper-api
provider:
name: aws
runtime: java8
timeout: 30
package:
artifact: target/hello-dev.jar
functions:
getCraigsListItems:
handler: com.serverless.Handler
events:
- http:
path: /items/{searchQuery}
method: get
I also added a timeout to 30 seconds. The default timeout with the serverless framework is 6 seconds. Since we're running Java code the Lambda cold start can take several seconds. And then we will make an HTTP request to Craigslist website, so 30 seconds seems good.
totoFunction code
Now we can modify the Handler.class. The function logic is easy. First, we retrieve the path parameter called "searchQuery". Then we create a CraigsListScraper and call the scrape() method with this searchQuery. It will return a List<Item> representing all the items on the first Craigslist's result page.
We then use the ApiGatewayResponse class that was generated by the Serverless framework to return a JSON array containing every item.
You can find the rest of the code in this repository, with the CraigsListScraper and Item class.
@Override
public ApiGatewayResponse handleRequest(Map<String, Object> input, Context context) {
LOG.info("received: {}", input);
try{
Map<String,String> pathParameters = (Map<String,String>)input.get("pathParameters");
String query = pathParameters.get("searchQuery");
CraigsListScraper scraper = new CraigsListScraper();
List<Item> items = scraper.scrape(query);
return ApiGatewayResponse.builder()
.setStatusCode(200)
.setObjectBody(items)
.setHeaders(Collections.singletonMap("X-Powered-By", "AWS Lambda & serverless"))
.build();
}catch(Exception e){
LOG.error("Error : " + e);
Response responseBody = new Response("Error while processing URL: ", input);
return ApiGatewayResponse.builder()
.setStatusCode(500)
.setObjectBody(responseBody)
.setHeaders(Collections.singletonMap("X-Powered-By", "AWS Lambda & Serverless"))
.build();
}
}
We can now build the project:
mvn clean install
And deploy it to AWS:
serverless deploy
Serverless: Packaging service...
Serverless: Creating Stack...
Serverless: Checking Stack create progress...
.....
Serverless: Stack create finished...
Serverless: Uploading CloudFormation file to S3...
Serverless: Uploading artifacts...
Serverless: Uploading service .zip file to S3 (13.35 MB)...
Serverless: Validating template...
Serverless: Updating Stack...
Serverless: Checking Stack update progress...
.................................
Serverless: Stack update finished...
Service Information
service: items-api
stage: dev
region: us-east-1
stack: items-api-dev
api keys:
None
endpoints:
GET - https://tmulioizdf.execute-api.us-east-1.amazonaws.com/dev/items/{searchQuery}
functions:
getCraigsListItems: items-api-dev-getCraigsListItems
You can then test your function using curl or your web browser with the URL given in the deployment logs (serverless info will also show this information.)
Here is a query to look for "macBook pro" :
curl https://tmulioizdf.execute-api.us-east-1.amazonaws.com/dev/items/macBook%20pro | json_reformat 1 ↵
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 19834 100 19834 0 0 7623 0 0:00:02 0:00:02 --:--:-- 7622
[
{
"title": "2010 15\" Macbook pro 3.06ghz 8gb 320gb osx maverick",
"price": 325,
"url": "https://sfbay.craigslist.org/eby/sys/d/macbook-pro-306ghz-8gb-320gb/6680853189.html"
},
{
"title": "Apple MacBook Pro A1502 13.3\" Late 2013 2.6GHz i5 8 GB 500GB + Extras",
"price": 875,
"url": "https://sfbay.craigslist.org/pen/sys/d/apple-macbook-pro-alateghz-i5/6688755497.html"
},
{
"title": "Apple MacBook Pro Charger USB-C (Latest Model) w/ Box - Like New!",
"price": 50,
"url": "https://sfbay.craigslist.org/pen/sys/d/apple-macbook-pro-charger-usb/6686902986.html"
},
{
"title": "MacBook Pro 13\" C2D 4GB memory 500GB HDD",
"price": 250,
"url": "https://sfbay.craigslist.org/eby/sys/d/macbook-pro-13-c2d-4gb-memory/6688682499.html"
},
{
"title": "Macbook Pro 2011 13\"",
"price": 475,
"url": "https://sfbay.craigslist.org/eby/sys/d/macbook-pro/6675556875.html"
},
{
"title": "Trackpad Touchpad Mouse with Cable and Screws for Apple MacBook Pro",
"price": 39,
"url": "https://sfbay.craigslist.org/pen/sys/d/trackpad-touchpad-mouse-with/6682812027.html"
},
{
"title": "Macbook Pro 13\" i5 very clean, excellent shape! 4GB RAM, 500GB HDD",
"price": 359,
"url": "https://sfbay.craigslist.org/sfc/sys/d/macbook-pro-13-i5-very-clean/6686879047.html"
},
...
Note that the first invocation will be slow, it took 7 seconds for me. The next invocations will be much quicker.
Go further
This was just a little example, here are some ideas to improve this :
- Better error handling
- Protect the API with an API Key (really easy to implement with API Gateway)
- Save the items to a DynamoDB database
- Send the search query to an SQS queue, and trigger the lambda execution with the queue instead of an HTTP request
- Send a notification with SNS if an Item is less than a certain price point.
If you like web scraping and are tired taking care of proxies, JS rendering and captchas, you can check our new web scraping API, the first 1000 API calls are on us.
This is the end of this tutorial.
I hope you enjoyed the post. Don't hesitate to experiment with Lambda and other cloud providers, it's really fun, easy, and can drastically reduce your infrastructure costs, especially for web-scraping or asynchronous related tasks.
If you are more into Python, have a look at our 👉 python web scraping tutorial

Kevin worked in the web scraping industry for 10 years before co-founding ScrapingBee. He is also the author of the Java Web Scraping Handbook.