With more than 28 million listings, Booking.com is one of the biggest websites to look for a place to stay during your trip. If you are opening up a new hotel in an area, you might want to keep tabs on your competition and get notified when new properties open up. This can all be automated with the power of web scraping! In this article, you will learn how to scrape data from the search results page of Booking.com using Python and Selenium and also handle pagination along the way.
This is what a typical search result page looks like on Booking.com. You can access this particular page by going to this url.
Setting up the prerequisites
This tutorial uses Python 3.10 but should work with most Python versions. Start by creating a new directory where all of your project files will be stored and then create a new Python file within it for the code itself:
$ mkdir booking_scraper
$ cd booking_scraper
$ touch app.py
You will need to install a few different libraries to follow along:
You can install both of these libraries using this command:
$ pip install selenium selenium-wire webdriver-manager
Selenium will provide you with all the APIs for programmatically accessing a browser and Selenium Wire will provide additional features on top of it. We will discuss these additional features later on when we use them. The webdriver-manager will help you in setting up a browser's binary driver easily without the need to manually download and link to it in your code.
Fetching Booking.com search result page
Let's try fetching the search result page using Selenium to make sure everything is set up correctly. Save the following code in the app.py file:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
url = "https://www.booking.com/searchresults.en-gb.html?ss=San+Francisco%2C+California%2C+United+States"
driver.get(url)
Note: This URL doesn't contain information about check-in and check-out dates so if you want to scrape information about properties that have availability on certain dates, make sure you select those dates in the search form and copy the resulting URL.
Running this code should open up a Chrome window and navigate it to the search page for properties in San Francisco. It might take a minute before it opens up the browser window as it might have to download the Chrome driver binary.
The code itself is fairly straightforward. It starts with importing the webdriver, the Service, and the ChromeDriverManager. Normally, you would initialize the webdriver by giving it an executable_path for the browser-specific driver binary you want to use:
browser = webdriver.Chrome(executable_path=r"C:\path\to\chromedriver.exe")
The biggest downside for this is that any time the browser updates, you will have to download the updated driver binary for the browser. This gets tiring very quickly and the webdriver_manager library makes it simpler by letting you pass in ChromeDriverManager().install(). This will automatically download the required binary and return the appropriate path so that you don't have to worry about it anymore.
The last line of code asks the driver to navigate to the search result page.
How to extract property information from the search result page
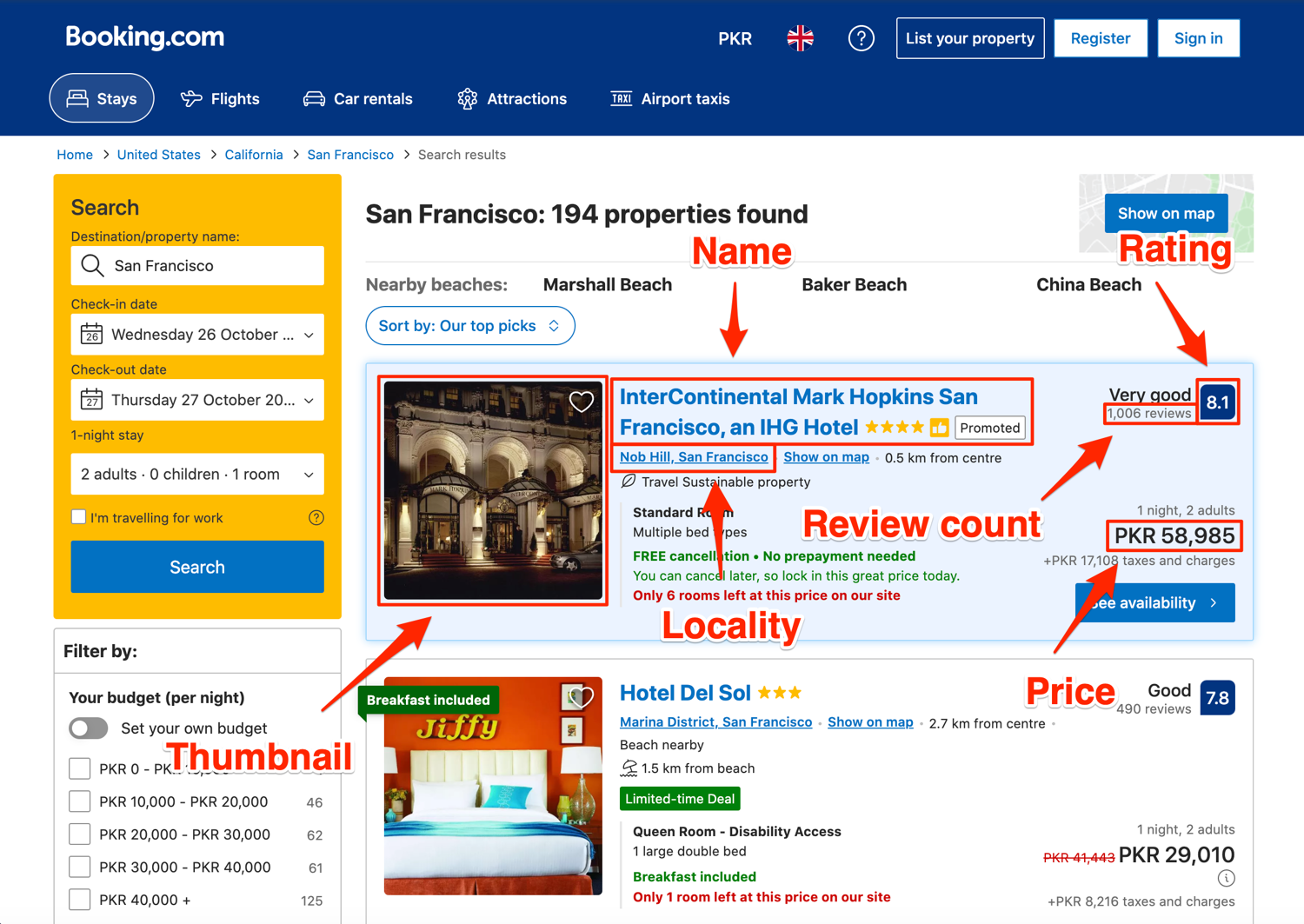
Before you can extract any data, you need to decide which data you even need to extract. In this tutorial, you will learn how to extract the following data from the search results page:
- Name
- Locality
- Rating
- Review count
- Thumbnail
- Price
The image below shows where all of this information is visually located on the result page:
You will be using the default methods (find_element + find_elements) that Selenium provides for accessing DOM elements and extracting data from them. Additionally, you will be relying on CSS selectors and XPath for locating the DOM elements. The exact method you use for locating an element will depend on the DOM structure and which method is the most appropriate.
Extracting property name and link
Let's start by exploring the DOM structure for the property name. Right-click on any property name and click on Inspect. This will open up the Developer Tools:
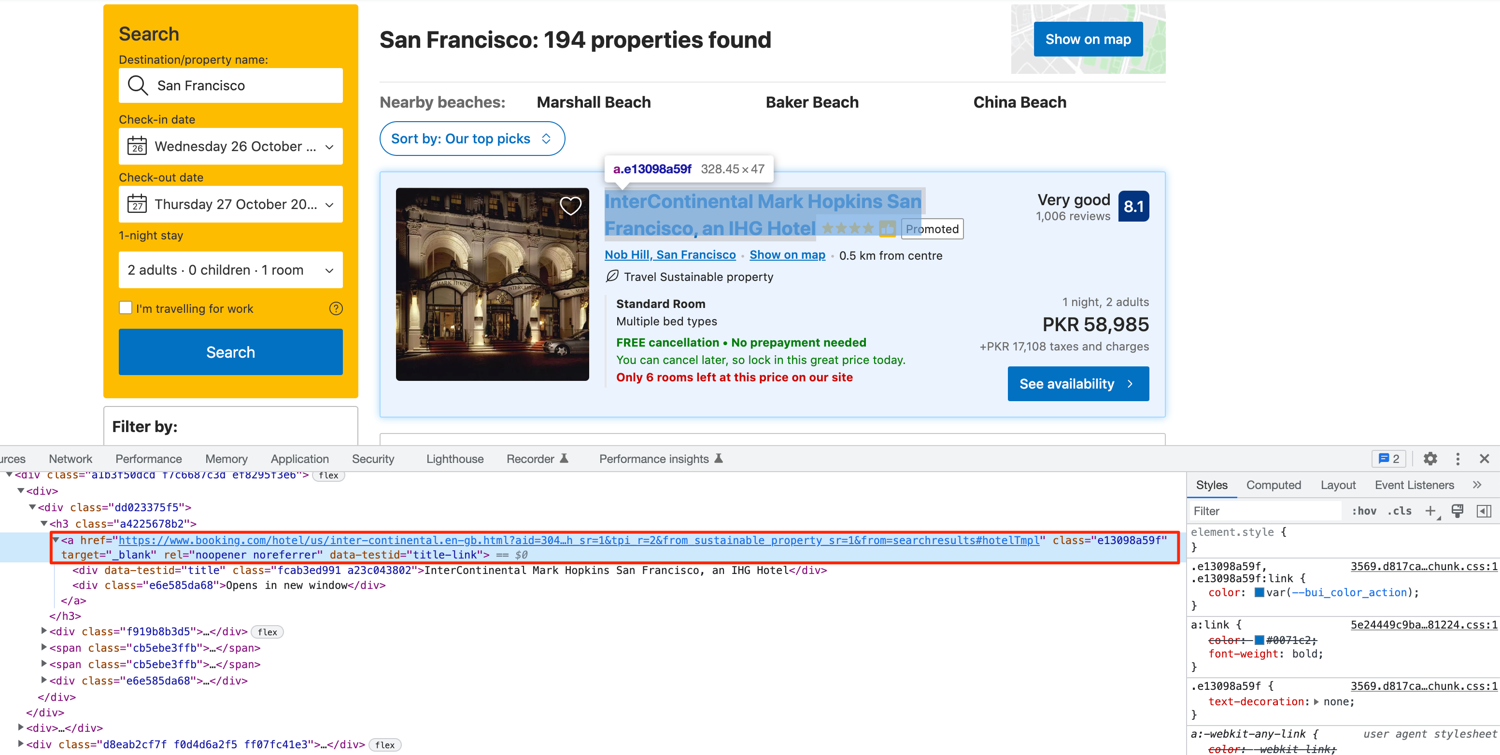
As you can see, the hotel name is encapsulated in an anchor tag. This anchor tag has a data-testid that we can use to extract the property link. The encapsulated div also has a data-testid attribute defined (title) that we can use to extract the hotel name. To make things easier, let's first extract all the property cards in a separate list and then work on each property one by one. This is not a must but it helps to keep everything structured.
This is what each property card looks like:
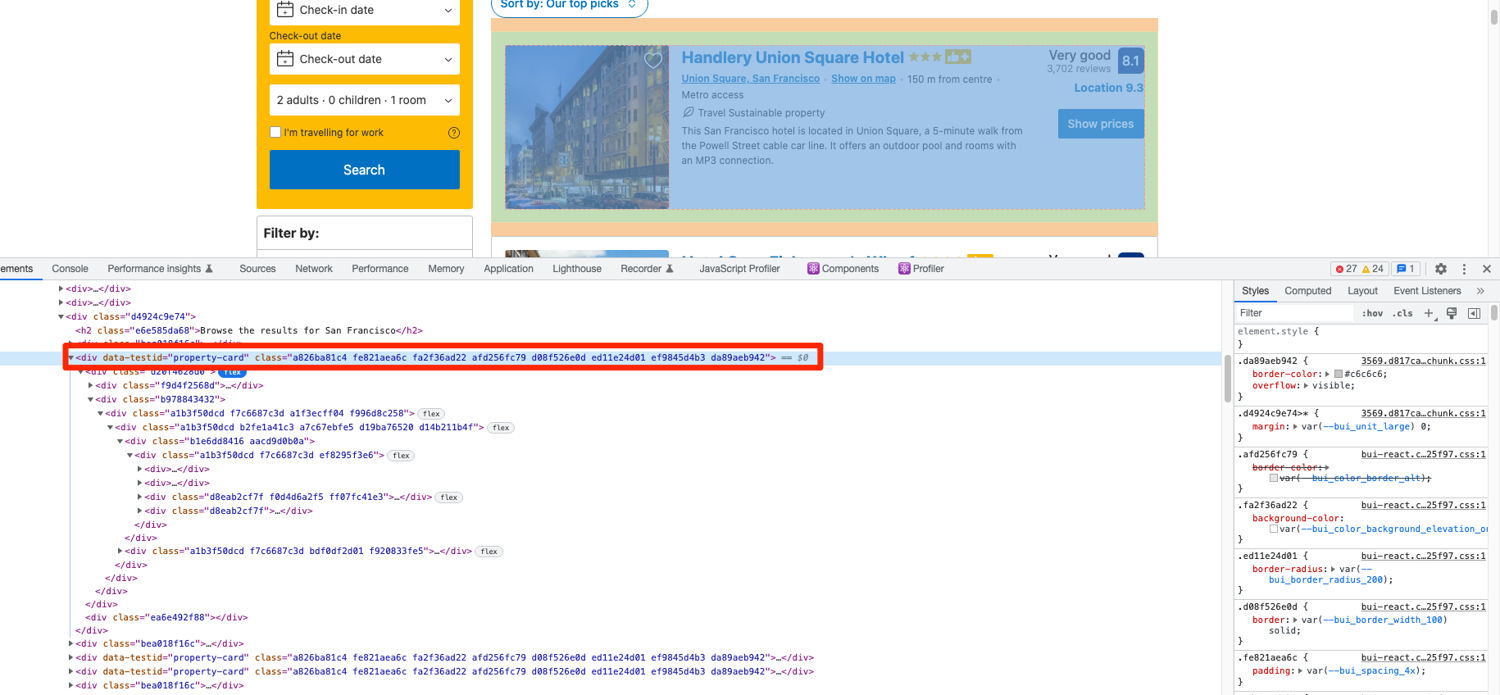
You can extract the property cards by targeting the divs that have the data-testid value set to property-card:
property_cards = driver.find_elements(By.CSS_SELECTOR, 'div[data-testid="property-card"]')
Now you can extract the property name and the property link using the following code:
for property in property_cards:
name = property.find_element(By.CSS_SELECTOR,'div[data-testid="title"]').text
link = property.find_element(By.CSS_SELECTOR,'a[data-testid="title-link"]').get_attribute('href')
Extracting property address and price
The property address can be extracted similarly. Explore the DOM structure in the developer tools and you will see a unique data-testid once again:
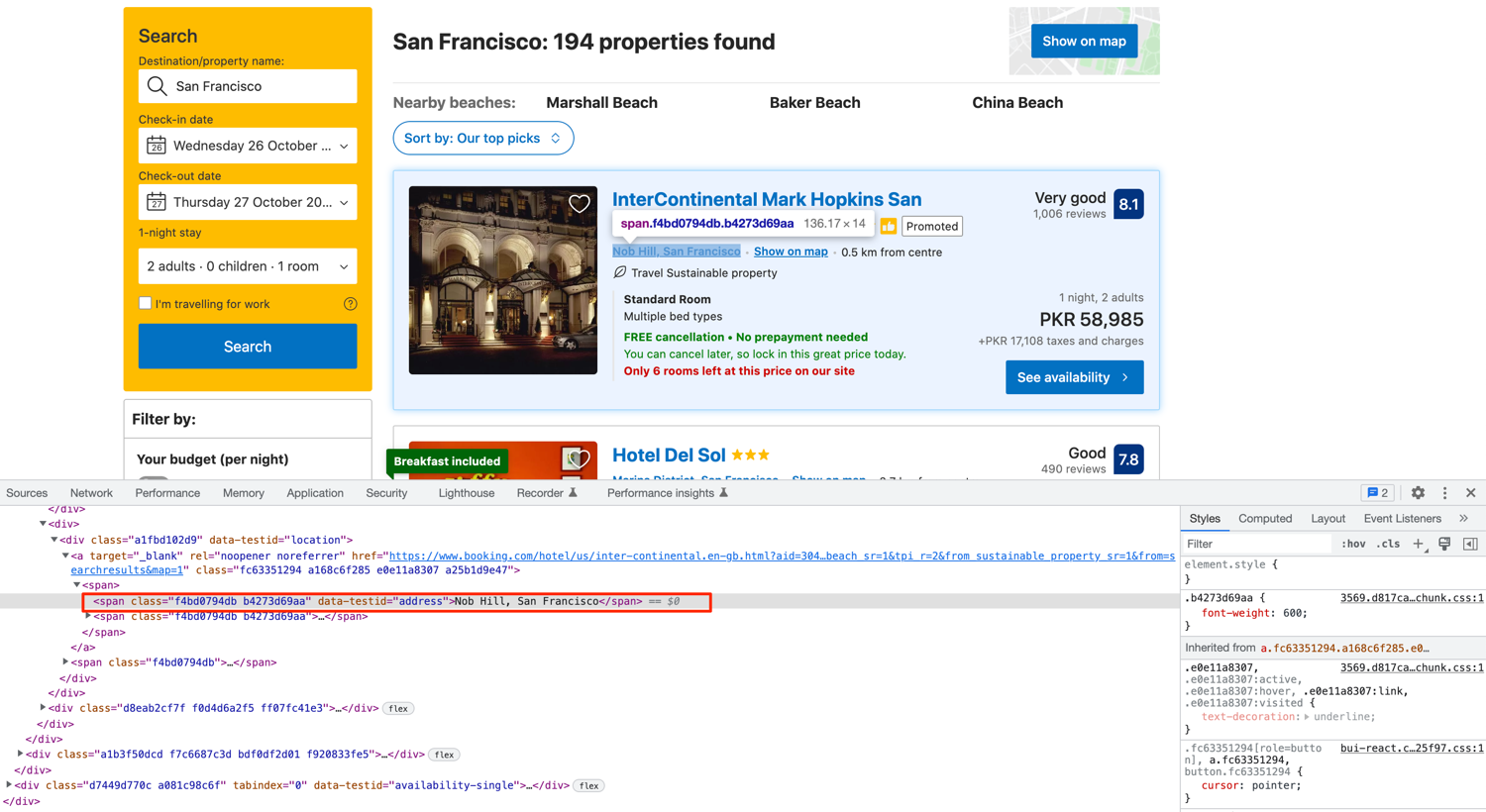
You can use the following code to extract the address/locality:
for property in property_cards:
# ...
address = property.find_element(By.CSS_SELECTOR, '[data-testid="address"]').text
The price also follows the same strategy. This is what the DOM structure looks like:
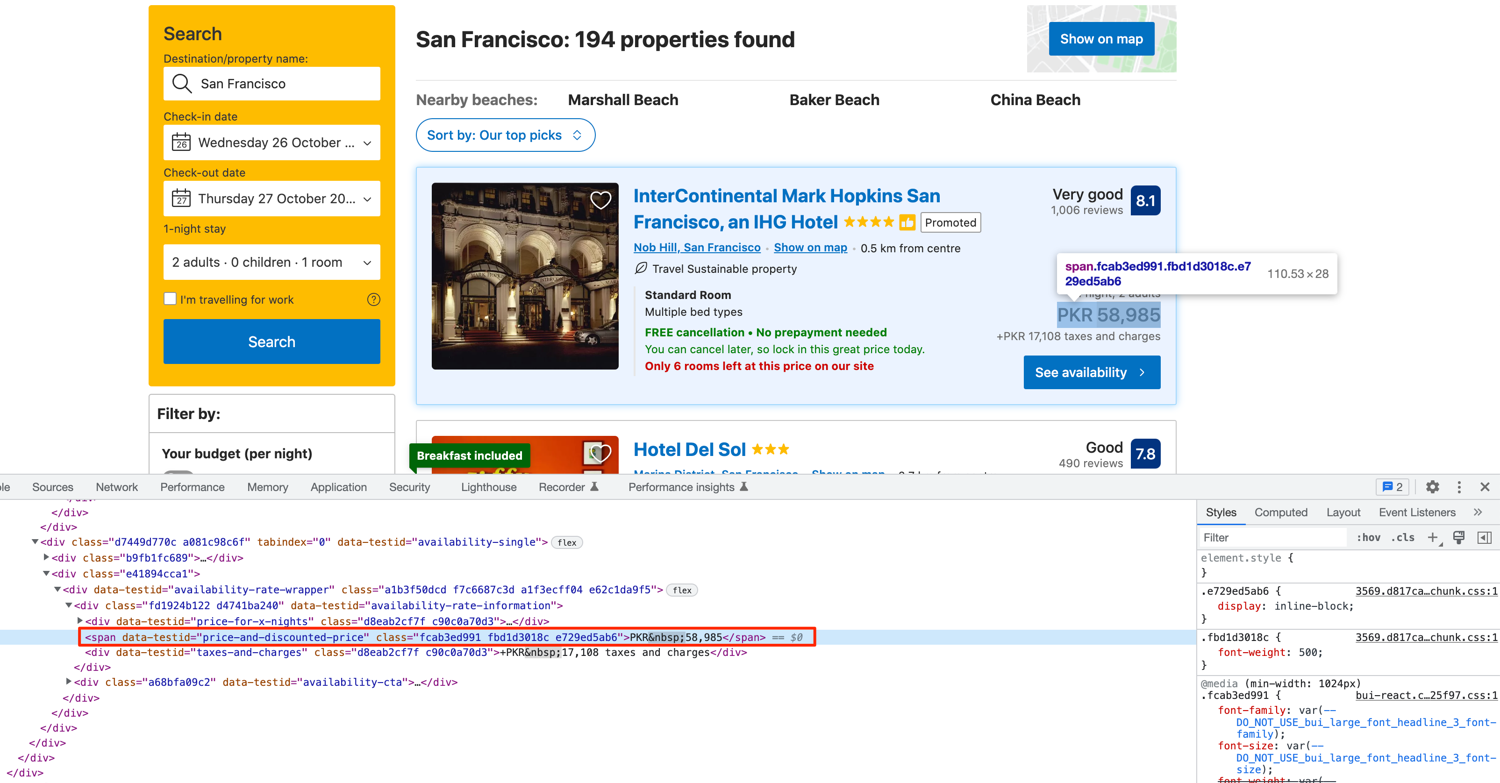
You can extract it by targeting the data-testid value of price-and-discounted-price. Every property listing has this data-testid attribute defined for the final price. This does not include the taxes so you will have to explore the DOM further if you are interested in extracting that too.
The following code works for extracting the price:
for property in property_cards:
price = property.find_element(By.CSS_SELECTOR, '[data-testid="price-and-discounted-price"]').text
Extracting property rating and review count
The rating and review count are nested in a div with a data-testid of review-score:
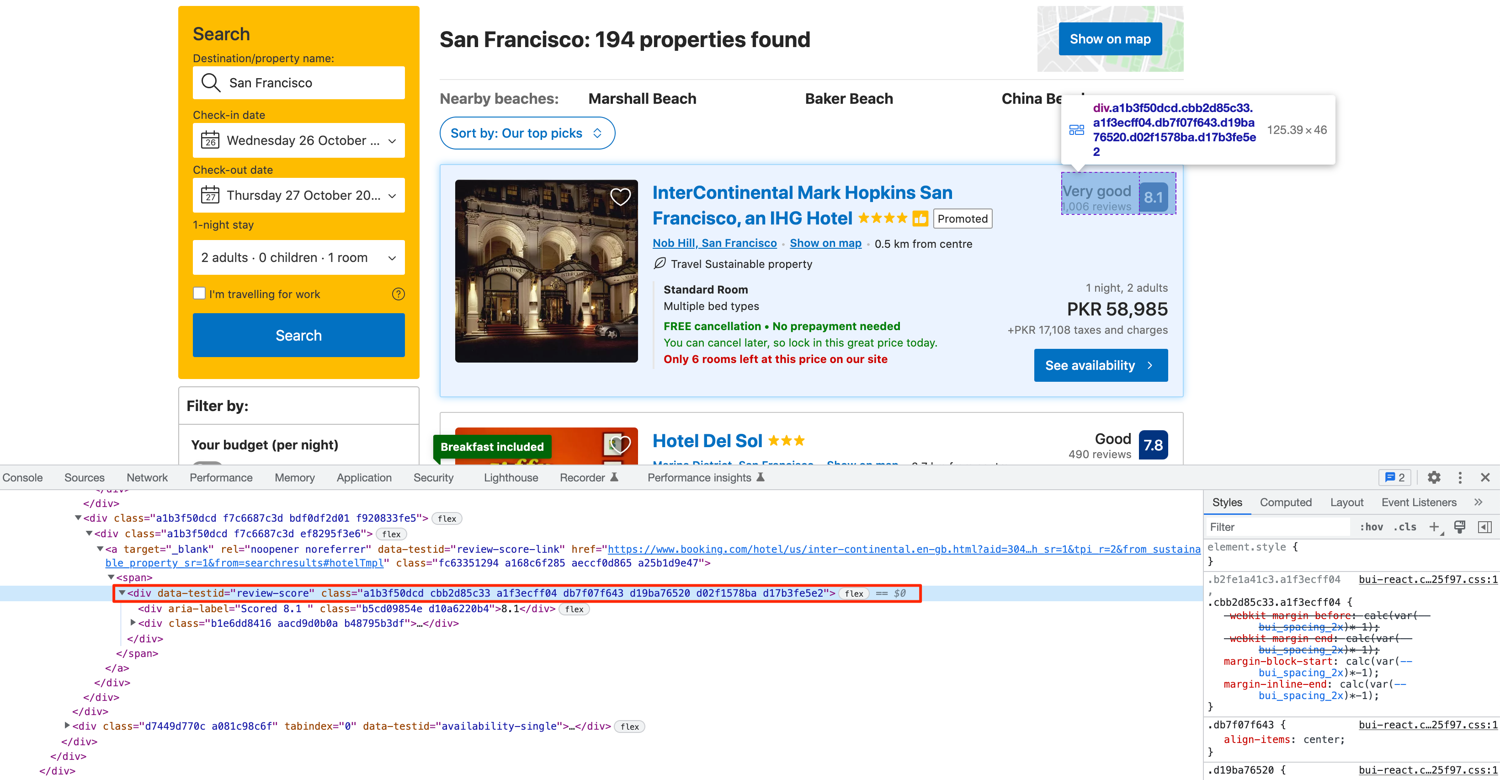
You can follow one of the multiple strategies for extracting the ratings and review count. You can extract them separately by targeting each div or you can be lazy and smart and extract all the visible text from this div and then split it appropriately. This is what raw extraction looks like:
>>> print(property_cards[0].find_element(By.CSS_SELECTOR, '[data-testid="review-score"]').text)
7.8
Good
491 reviews
You can split this text at the newline character (\n) and that should give you the rating and review count. This is how you can do it:
for property in property_cards:
# ...
review_score, _, review_count = property.find_element(By.CSS_SELECTOR, '[data-testid="review-score"]').text.split('\n')
Extracting property thumbnail
The thumbnail is located in an img tag with the data-testid of image:
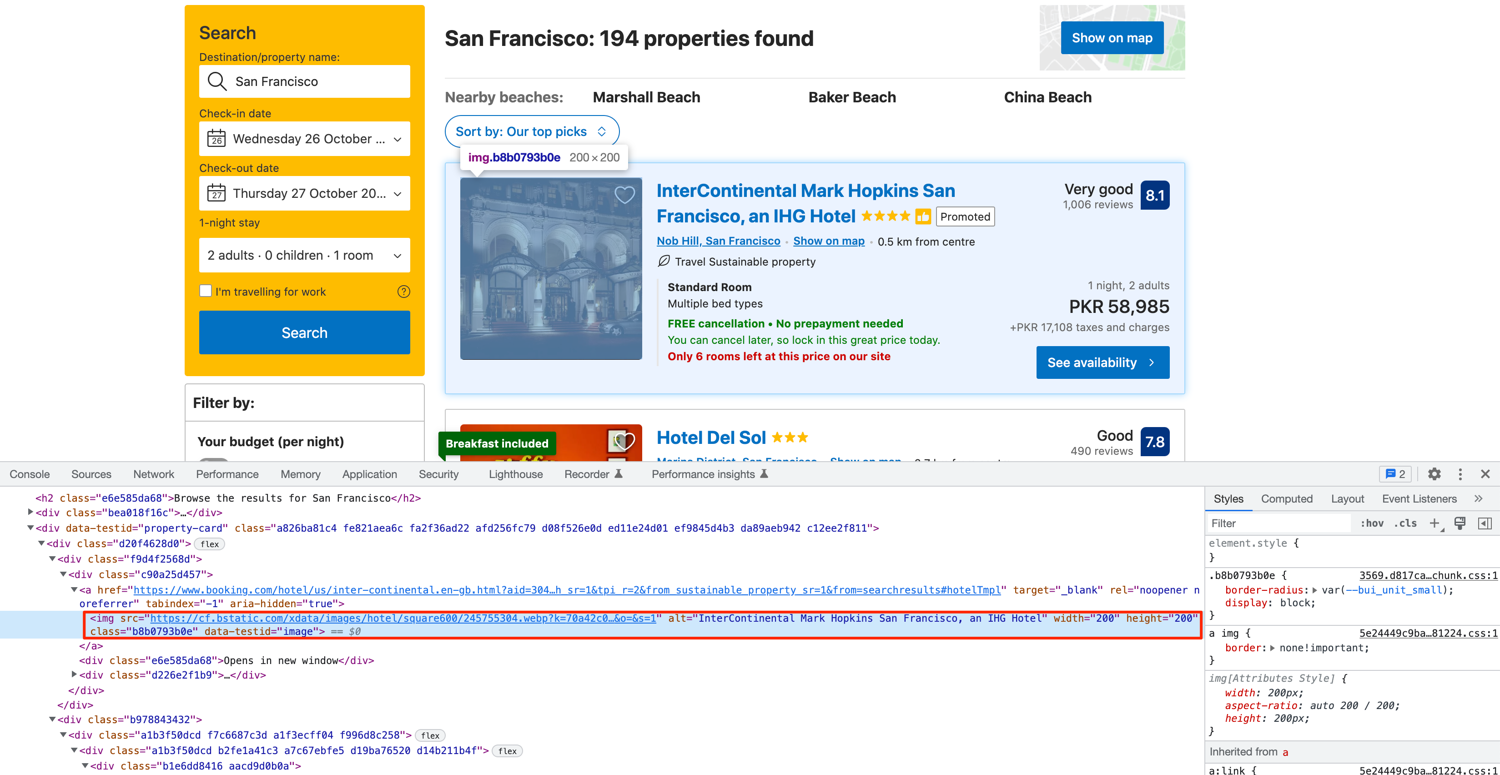
You must have gotten used to it by now. Go ahead and write some code to target this image tag and extract the src attribute:
for property in property_cards:
# ...
image = property.find_element(By.CSS_SELECTOR, '[data-testid="image"]').get_attribute('src')
Navigating to the next result page
You can navigate to the next page of the search results by using the following code statements:
next_page_btn = driver.find_element(By.XPATH, '//button[contains(@aria-label, "Next page")]')
next_page_btn.click()
Now comes the tricky part. Selenium by default does not provide you with any way to verify if a particular background request has returned. This becomes a huge limitation when scraping JS-heavy websites. There is no straightforward way to figure out if the DOM has been updated with new results after pressing the next page button without such a feature. You can go ahead and compare the list of new properties with the already scraped ones and that might give you some idea if the DOM has been updated with new data. However, there is an easier way.
This is where Selenium Wire shines. If you followed the installation instructions at the beginning of the article then you already have it installed. Selenium Wire lets you inspect individual requests and figure out if a response has successfully returned or not. Luckily, it is a drop-in replacement for Selenium and doesn't require any code change. Simply update the Selenium import at the top of your app.py file:
from seleniumwire import webdriver
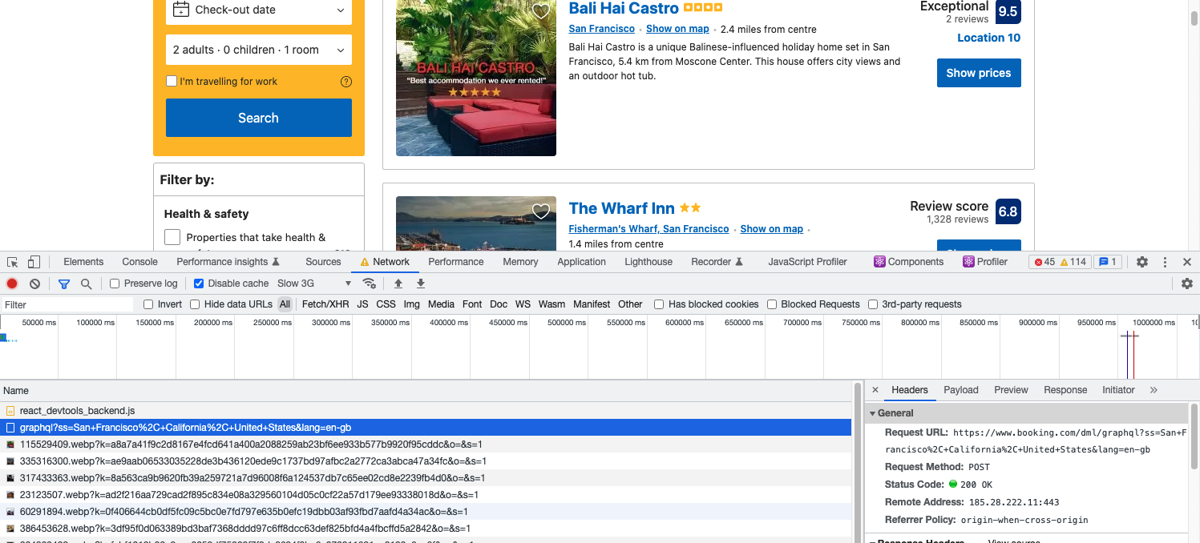
Now, you can wait for the next page request to finish before scraping the listings. You can explore which request is fired when you click on the next page (by going to the Network tab in developer tools) and then pass that URL (or pattern) to driver.wait_for_request method.
It turns out a request to a /dml/graphql endpoint is triggered:
You can add a wait using this code:
driver.wait_for_request("/dml/graphql", timeout=5)
This will wait for the request to finish (or it will timeout after 5 seconds) before continuing execution. There is another tricky situation. If you use the wait as it is and click on next twice, the wait will return if the first request has finished but the second has not. This is because both requests are made to the same URL (only the POST data is different). This will happen when you try to navigate to page three after scraping page two. It has an easy fix though. You can simply delete all the requests that selenium-wire has in memory. This will make sure only the most recent request is in memory.
You can delete old requests like this:
del driver.requests
Complete code
Now you have all the code for extracting the name, locality, rating, review count, thumbnail, and price of all properties from the booking.com search result page. And you also have the code to navigate to the next page of search results.
You can tweak the code a little bit and make it store all the properties in a list and then use those results in whatever way you want. This is just one example of how the code might look:
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
url = "https://www.booking.com/searchresults.en-gb.html?dest_id=20015732&dest_type=city&group_adults=2"
driver.get(url)
properties = []
def extract_properties():
property_cards = driver.find_elements(By.CSS_SELECTOR, 'div[data-testid="property-card"]')
new_property = {}
for property in property_cards:
name = property.find_element(By.CSS_SELECTOR,'div[data-testid="title"]').text
link = property.find_element(By.CSS_SELECTOR,'a[data-testid="title-link"]').get_attribute('href')
review_score, _, review_count = property.find_element(By.CSS_SELECTOR, '[data-testid="review-score"]').text.split('\n')
price = property.find_element(By.CSS_SELECTOR, '[data-testid="price-and-discounted-price"]').text
address = property.find_element(By.CSS_SELECTOR, '[data-testid="address"]').text
image = property.find_element(By.CSS_SELECTOR, '[data-testid="image"]').get_attribute('src')
new_property['name'] = name
new_property['link'] = link
new_property['review_score'] = review_score
new_property['review_count'] = review_count
new_property['price'] = price
new_property['address'] = address
new_property['image'] = image
properties.append(new_property)
total_pages = int(driver.find_element(By.CSS_SELECTOR, 'div[data-testid="pagination"] li:last-child').text)
print(f"Total pages: {total_pages}")
for current_page in range(total_pages):
del driver.requests
extract_properties()
next_page_btn = driver.find_element(By.XPATH, '//button[contains(@aria-label, "Next page")]')
next_page_btn.click()
driver.wait_for_request("/dml/graphql", timeout=5)
Conclusion
This was just a short and quick example of what is possible with Python and Selenium. As your project grows in size, you can explore the option of running multiple drivers in parallel and storing the scraped data in a database. You can also combine the powers of Scrapy and Selenium and use them together. Scrapy is a full-fledged Python web scraping framework that features pause/resume, data filtration, proxy rotation, multiple output formats, remote operation, and a whole load of other features and becomes even more powerful when used in conjunction with Selenium.
I hope you learned something new today. If you have any questions please do not hesitate to reach out. We would love to take care of all of your web scraping needs and assist you in whatever way possible!
Before you go, check out these related reads:

Yasoob is a renowned author, blogger and a tech speaker. He has authored the Intermediate Python and Practical Python Projects books ad writes regularly. He is currently working on Azure at Microsoft.
