Web scraping is the process of extracting data from a website. Scraping can be a powerful tool in a developer's arsenal when they're looking at problems like automation or investigation, or when they need to collect data from public websites that lack an API or provide limited access to the data.
People and businesses from a myriad of different backgrounds use web scraping, and it's more common than people realize. In fact, if you've ever copy-pasted code from a website, you've performed the same function as a web scraper—albeit in a more limited fashion.

Uses Cases For Web Scraping
Web scraping is used in many sectors and has many applications. Some common uses include:
- Aggregating data from multiple sources: Collecting data from multiple sources and merging them into a single data set.
- Price Monitoring: Monitoring the price of products across multiple websites and comparing the prices to see if there is any price drop. This method is also used for inventory monitoring.
- Lead generation: Some companies specialize in scraping industry and sector-specific websites to collect target-customer data for future lead generation.
In this tutorial, you will learn the basics of web crawling, data extraction, and data parsing using the Elixir language. Due to its high performance, simplicity, and overall stability, Elixir is a great choice for web scraping. You'll also learn how to use Crawly, a complete web-scraping framework for Elixir.
Note: The code examples for this tutorial can be found in this GitHub repository.
Implementing Web Scraping With Elixir
In recent years, graphics cards have been in low supply, despite very high demand, making it difficult to find available stock, and driving prices higher when you could.
Knowledge of web scraping would allow you to find available graphic cards at the lowest possible price. In this tutorial, you'll crawl Amazon's selection of graphic cards to get the lowest-priced graphics cards.
To do this, you'll build a web scraper to extract price information from several websites for this tutorial. The scraper will collect all the price data so that it can be analyzed and compared later. This is a great foundation for building a price alert service, or even a scalping bot you could use to purchase products in limited supply.
Setting Up the Project
To begin, you'll need to create a new Elixir project:
mix new price_spider --sup
The --sup flag is used to create a new project with an OTP skeleton, including the supervision tree. This is needed because our price_spider project will be responsible for spawning and managing several processes.
Once the project is created, you will need to update the list of dependencies in the price_spicer/mix.exs:
defp deps do
[
{:crawly, "~> 0.13.0"},
{:floki, "~> 0.26.0"}
]
end
Fetch the dependencies:
cd price_spider
mix deps.get
The libraries we are installing will be used to scrape data from websites and extract the data collected for further use.
- Crawly is a web scraping framework, and will be used to create the spider.
- Floki is a library for parsing and manipulating HTML documents, and will be used to extract the data from the spider's output.
Before moving forward, you'll also add some baseline configuration to your crawler. Create the configuration file for the application:
mkdir config
touch config/config.exs
Open price_spider/config.exs and add the following:
# General application configuration
import Config
config :crawly,
middlewares: [
{Crawly.Middlewares.UserAgent, user_agents: [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"
]},
{Crawly.Pipelines.WriteToFile, folder: "/tmp", extension: "jl"}
]
This is setting a specific user agent for the crawler. By having it mimic a browser, you minimize the likelihood of being blocked by the website and make it more likely that you'll get the data you need. Tools like ScrapingBee provide a list of rotating proxies and generate valid user agents; this is a great aid when scraping large amounts of data.
Creating the Spider
Web crawlers, often also referred to as spiders or simply crawlers, are a type of bot that systematically goes through the web, collecting and indexing data from web pages.
In the context of Crawly, spiders are user-created behaviors that Crawly uses to scrape data from a set of websites. As with any behavior, your spider needs to implement the following callbacks:
init/0: This is called once, and is used to initialize the spider and any state it needs to maintain.base_url/0: This is called once, and is used to return the base URL of the website being scraped. It's also used to filter irrelevant links and keep the spider focused on the target website.parse_item/1: This is called for each item on the website, and is used to parse the crawler response. It returns aCrawly.ParsedItemstructure.
Create your spider in the lib/price_spider/spiders/basic_spider.ex file:
defmodule PriceSpider.BasicSpider do
use Crawly.Spider
@impl Crawly.Spider
def base_url do
"http://www.amazon.com"
end
@impl Crawly.Spider
def init() do
[
start_urls: [
"https://www.amazon.com/ZOTAC-Graphics-IceStorm-Advanced-ZT-A30820J-10PLHR/dp/B09PZM76MG/ref=sr_1_3?crid=1CLZE45WJ15HH&keywords=3080+graphics+card&qid=1650808965&sprefix=3080+%2Caps%2C116&sr=8-3",
"https://www.amazon.com/GIGABYTE-Graphics-WINDFORCE-GV-N3080GAMING-OC-12GD/dp/B09QDWGNPG/ref=sr_1_4?crid=1CLZE45WJ15HH&keywords=3080+graphics+card&qid=1650808965&sprefix=3080+%2Caps%2C116&sr=8-4",
"https://www.amazon.com/ZOTAC-Graphics-IceStorm-Advanced-ZT-A30800J-10PLHR/dp/B099ZCG8T5/ref=sr_1_5?crid=1CLZE45WJ15HH&keywords=3080+graphics+card&qid=1650808965&sprefix=3080+%2Caps%2C116&sr=8-5"
]
]
end
@impl Crawly.Spider
def parse_item(_response) do
%Crawly.ParsedItem{:items => [], :requests => []}
end
end
Run the Spider
It's time for you to run your first spider. Start the Elixir interactive console with iex -S mix and run the following command:
Crawly.Engine.start_spider(PriceSpider.BasicSpider)
You should get a result like the following:
16:02:49.817 [debug] Starting the manager for Elixir.PriceSpider.BasicSpider
16:02:49.822 [debug] Starting requests storage worker for Elixir.PriceSpider.BasicSpider...
16:02:49.827 [debug] Started 4 workers for Elixir.PriceSpider.BasicSpider
What Happened?
As soon as you run the command, Crawly schedules the spider to run for each one of your start URLs. When it receives a response, Crawly then passes the response object to the parse_item/1 callback to process the response and extract the data.
There hasn't been any parsing logic implemented in this basic example, so it returns an empty Crawly.ParsedItem structure. In the next section of this tutorial, you'll use Floki to extract the data from the response.
Extracting Data From the Response
As part of Crawly.Spider behavior, parse_item/1 is expected to return a request-and-items structure. Before implementing the logic, let's explore the data you're working with.
Open the Elixir interactive console and run the following command:
response = Crawly.fetch("https://www.amazon.com/ZOTAC-Graphics-IceStorm-Advanced-ZT-A30820J-10PLHR/dp/B09PZM76MG/")
You should see a result similar to the following:
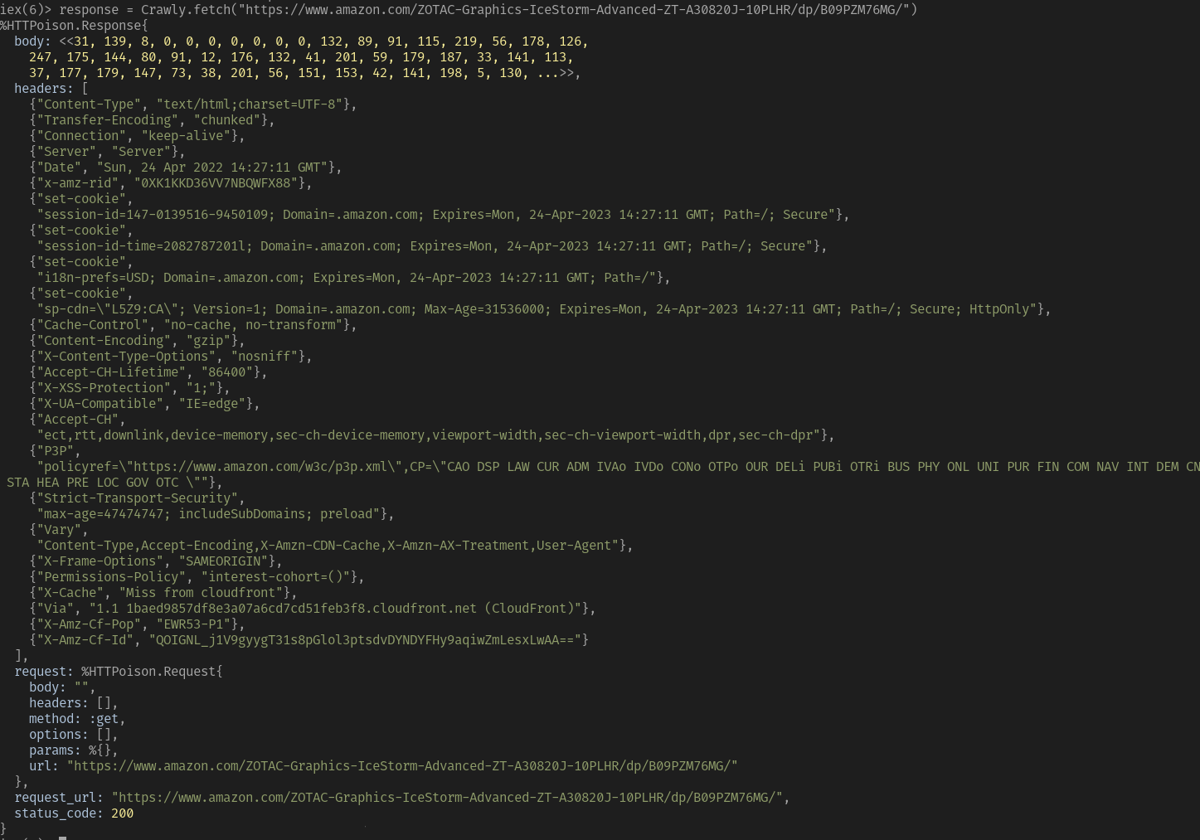
This is the raw response from the website. Next you'll use Floki to extract the data from the response. Notably, we will extract the price from the response.
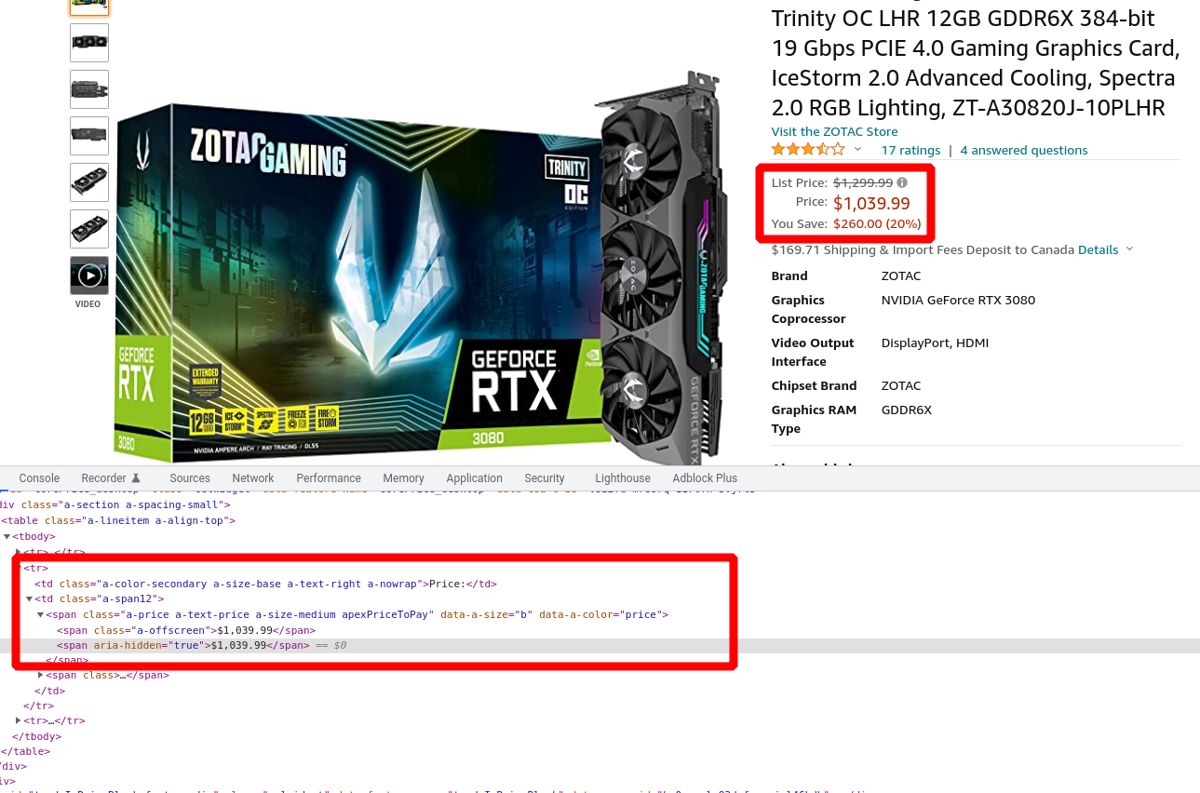
You can locate the price by exploring the data further through the Elixir interactive console. Run the following commands:
response = Crawly.fetch("https://www.amazon.com/ZOTAC-Graphics-IceStorm-Advanced-ZT-A30820J-10PLHR/dp/B09PZM76MG/")
{:ok, document} = Floki.parse_document(response.body)
price = document |> Floki.find(".a-box-group span.a-price span.a-offscreen") |> Floki.text
Assuming everything worked correctly, you should see an output like the following:
iex(3)> price = document |> Floki.find(".a-box-group span.a-price span.a-offscreen") |> Floki.text
"$1,039.99"
Now you can wire everything into your spider:
defmodule PriceSpider.BasicSpider do
use Crawly.Spider
@impl Crawly.Spider
def base_url do
"http://www.amazon.com"
end
@impl Crawly.Spider
def init() do
[
start_urls: [
"https://www.amazon.com/ZOTAC-Graphics-IceStorm-Advanced-ZT-A30820J-10PLHR/dp/B09PZM76MG/",
"https://www.amazon.com/GIGABYTE-Graphics-WINDFORCE-GV-N3080GAMING-OC-12GD/dp/B09QDWGNPG/",
"https://www.amazon.com/ZOTAC-Graphics-IceStorm-Advanced-ZT-A30800J-10PLHR/dp/B099ZCG8T5/"
]
]
end
@impl Crawly.Spider
def parse_item(response) do
{:ok, document} =
response.body
|> Floki.parse_document
price =
document
|> Floki.find(".a-box-group span.a-price span.a-offscreen")
|> Floki.text
|> String.trim_leading()
|> String.trim_trailing()
%Crawly.ParsedItem{
:items => [
%{price: price, url: response.request_url}
],
:requests => []
}
end
end
You can check that things are working correctly by running the following command:
Crawly.Engine.start_spider(PriceSpider.BasicSpider)
Earlier on our initial setup, we configured Crawly to write the results of the crawler into a file in the tmp/ directory. This file will have the same name as the spider, plus a timestamp.
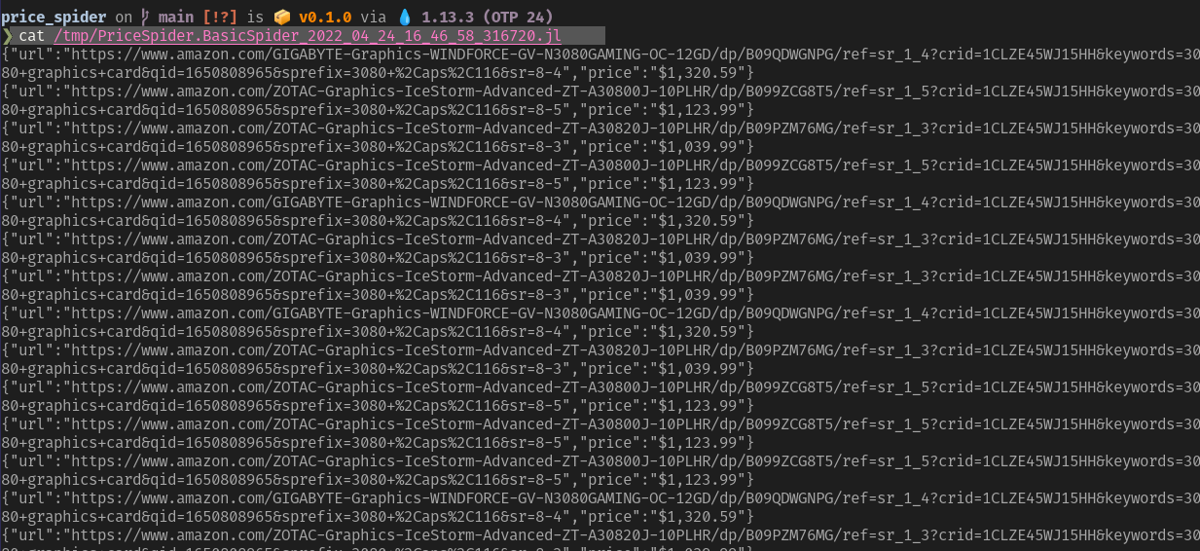
Taking It Further
Now that you have a working Amazon spider, it's time to take it further. At this point, the spider can only crawl the specific URLs that it's been provided with. You can take the spider further by allowing it to discover URLs from a search results page.
Create a new file under lib/price_spider/spiders/amazon_spider.ex and add the following code:
defmodule PriceSpider.AmazonSpider do
use Crawly.Spider
@impl Crawly.Spider
def base_url do
"http://www.amazon.com"
end
@impl Crawly.Spider
def init() do
[
start_urls: [
"https://www.amazon.com/s?k=3080+video+card&rh=n%3A17923671011%2Cn%3A284822&dc&qid=1650819793&rnid=2941120011&sprefix=3080+video%2Caps%2C107&ref=sr_nr_n_2"
]
]
end
@impl Crawly.Spider
def parse_item(response) do
{:ok, document} =
response.body
|> Floki.parse_document()
# Getting search result urls
urls =
document
|> Floki.find("div.s-result-list a.a-link-normal")
|> Floki.attribute("href")
# Convert URLs into requests
requests =
Enum.map(urls, fn url ->
url
|> build_absolute_url(response.request_url)
|> Crawly.Utils.request_from_url()
end)
name =
document
|> Floki.find("span#productTitle")
|> Floki.text()
price =
document
|> Floki.find(".a-box-group span.a-price span.a-offscreen")
|> Floki.text()
|> String.trim_leading()
|> String.trim_trailing()
%Crawly.ParsedItem{
:requests => requests,
:items => [
%{name: name, price: price, url: response.request_url}
]
}
end
def build_absolute_url(url, request_url) do
URI.merge(request_url, url) |> to_string()
end
end
These are the main changes you've made to the spider:
- A new code block retrieves all the URLs from search results.
- Each URL is converted to a request and added to the list of requests on our parsed item.
- A new field is added to our parsed item,
name, which contains the product title. - The new function
build_absolute_urlconverts relative URLs to absolute URLs.
You can run your new spider by running the following command:
Crawly.Engine.start_spider(PriceSpider.AmazonSpider)
After running the enhanced version of the spider, you should see more items processed:
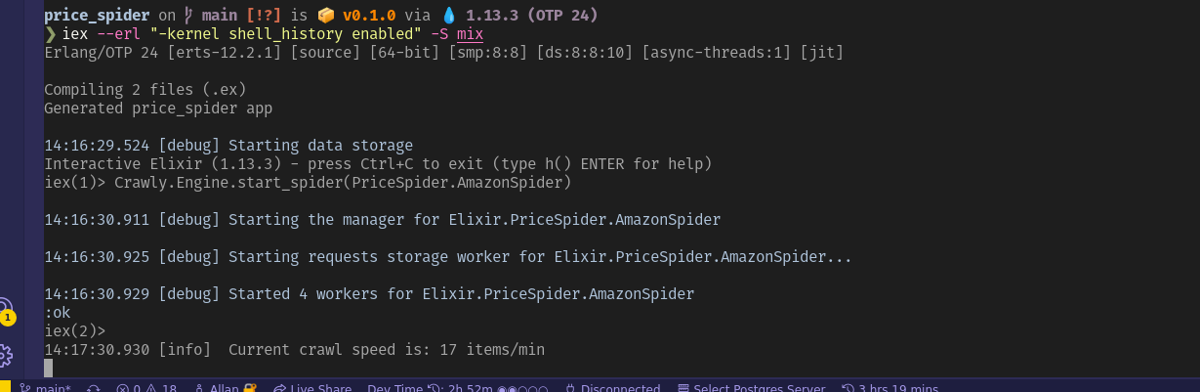
You can see the generated list of items by looking at your tmp/ directory file, which should look something like this:
{"url":"https://www.amazon.com/ASUS-Graphics-DisplayPort-Axial-tech-2-9-Slot/dp/B096L7M4XR/ref=sr_1_30?keywords=3080+video+card&qid=1650820592&rnid=2941120011&s=pc&sprefix=3080+video%2Caps%2C107&sr=1-30","price":"$1,786.99","name":"ASUS ROG Strix NVIDIA GeForce RTX 3080 Ti OC Edition Gaming Graphics Card (PCIe 4.0, 12GB GDDR6X, HDMI 2.1, DisplayPort 1.4a, Axial-tech Fan Design, 2.9-Slot, Super Alloy Power II, GPU Tweak II)"}
{"url":"https://www.amazon.com/ASUS-Graphics-DisplayPort-Military-Grade-Certification/dp/B099ZC8H3G/ref=sr_1_28?keywords=3080+video+card&qid=1650820592&rnid=2941120011&s=pc&sprefix=3080+video%2Caps%2C107&sr=1-28","price":"$1,522.99","name":"ASUS TUF Gaming NVIDIA GeForce RTX 3080 V2 OC Edition Graphics Card (PCIe 4.0, 10GB GDDR6X, LHR, HDMI 2.1, DisplayPort 1.4a, Dual Ball Fan Bearings, Military-Grade Certification, GPU Tweak II)"}
{"url":"https://www.amazon.com/GIGABYTE-Graphics-WINDFORCE-GV-N3080VISION-OC-10GD/dp/B098TZX3NT/ref=sr_1_23?keywords=3080+video+card&qid=1650820592&rnid=2941120011&s=pc&sprefix=3080+video%2Caps%2C107&sr=1-23","price":"$1,199.99","name":"GIGABYTE GeForce RTX 3080 Vision OC 10G (REV2.0) Graphics Card, 3X WINDFORCE Fans, LHR, 10GB 320-bit GDDR6X, GV-N3080VISION OC-10GD REV2.0 Video Card"}
You've successfully crawled Amazon and extracted the prices of video cards, data that you could use as the basis for any number of other applications.
Conclusion
In this tutorial, you've learned how to use Crawly to crawl websites and extract data from them. You've also learned the basics of web scraping, and have the foundation to build web crawlers and web scrapers.
Keep in mind that you've only scratched the surface of what Crawly can do, and more powerful features are available. These features include things like request spoofing, which is a way to simulate a different user agent, or a different IP address; item validation through pipelines; filtering previously seen requests and items; concurrency control; and robots.txt enforcement.
As you do more web scraping, it's important to consider the ethical implications of crawling websites and how to do it responsibly. A great starting point can be found in Crawly's official documentation.

Allan MacGregor is a software engineer and entrepreneur based in Toronto, with experience in building projects and developing innovative solutions.


