You might have seen one of our other tutorials on how to scrape websites, for example with Ruby, JavaScript or Python, and wondered: what about the most widely used server-side programming language for websites, which, at the same time, is the one of the most dreaded? Wonder no more - today it's time for PHP 🥳!
Believe it or not, PHP and web scraping have much in common: just like PHP, web scraping can be used either in a quick and dirty way or in a more elaborate fashion and supported with the help of additional tools and services.
In this article, we'll first look at some libraries/tools that can help us scrape the web with PHP. Please keep in mind that there is no general "best way" - each approach has its use case, depending on what you need, how you like to do things, and what you want to achieve. Later in the article, we'll see how to use some of these tools in a fun mini-project.

1. A Comprehensive List Of PHP Web Scraping Libraries (2026)
The most popular libraries used for web scraping with PHP are listed below:
- Guzzle: A PHP HTTP Client that abstracts away low-level HTTP transport details and let's you send HTTP requests with ease.
- Goutte: A crawling and scraping library for PHP; provides a nice way to send HTTP requests and extract data from HTML/XML responses. It is now deprecated and replaced by HttpBrowser from Symfony BrowserKit.
- Simple HTML DOM Parser: Pure PHP based DOM parser that can extract data from HTML documents (including broken ones). It also supports CSS selectors.
- Php-webdriver: PHP Language bindings for the Selenium web browser control framework. Can be used for running automated/headless web browsers using PHP.
- Symfony Panther: A web scraping and browser testing framework that can control native web browsers without installing additional copies of web browsers.
- DiDOM: A fast and simple HTML/XML parser.
- Chrome PHP: A library that allows you to control Chrome/Chromium using PHP.
- Crawler Detect: A PHP class that let's you detect if an user-agent string is a bot or not. For scraping, you can use it to make sure your user-agent string isn't flagged as a bot.
- Embed: A PHP library that can extract information from web pages; using OEmbed, OpenGraph or even using the HTML structure. Includes adapters for popular websites such as YouTube, Vimeo, Flickr, Instagram, Archive.org, GitHub, and Facebook.
- Httpful: A chainable, saner alternative to cURL that makes sending HTTP requests using PHP easier.
- Roach PHP: A complete webscraping toolkit for PHP, heavily inspired by Scrapy for Python.
- PHP-Spider: A spidering library for PHP that can visit, discover, and crawl URLs using breadth-first or depth-first search.
- Puphpeteer: A bridge library that allows you to access the Puppeteer browser API for Google Chrome.
- Ultimate Web Scraper: A library designed to handle all your scraping needs. Also supports websockets.
- phpQuery: A PHP port jQuery selectors that helps you extract data from HTML pages.
- hQuery: A superfast HTML parser that can extract data from HTML using jQuery/CSS selectors. Claims to process multiple megabytes of HTML data per second.
2. Birthday Scraping - A Fun Mini-Project
For a hands-on demonstration of some of the tools we looked at above, we will try to get a list of people who share the same birthday, as you can see, for instance, on famousbirthdays.com. If you want to code along, please ensure that you have installed a current version of PHP and Composer.
Create a new directory and run the following commands from it:
$ composer init --require="php >= 8.3" --no-interaction
$ composer update
We're ready!
3. HTTP Requests - Warming Up With A Barebones Approach
When it comes to browsing the web, the one important communication protocol you need to be familiar with is HTTP, the Hypertext Transport Protocol. It defines how participants on the World Wide Web communicate with each other. There are servers hosting resources and clients requesting resources from them.
Your browser is such a client and when we open the developer console (press F12), select the "Network" tab, and open the famous example.com, we can see the full request sent to the server, as well as the full response:
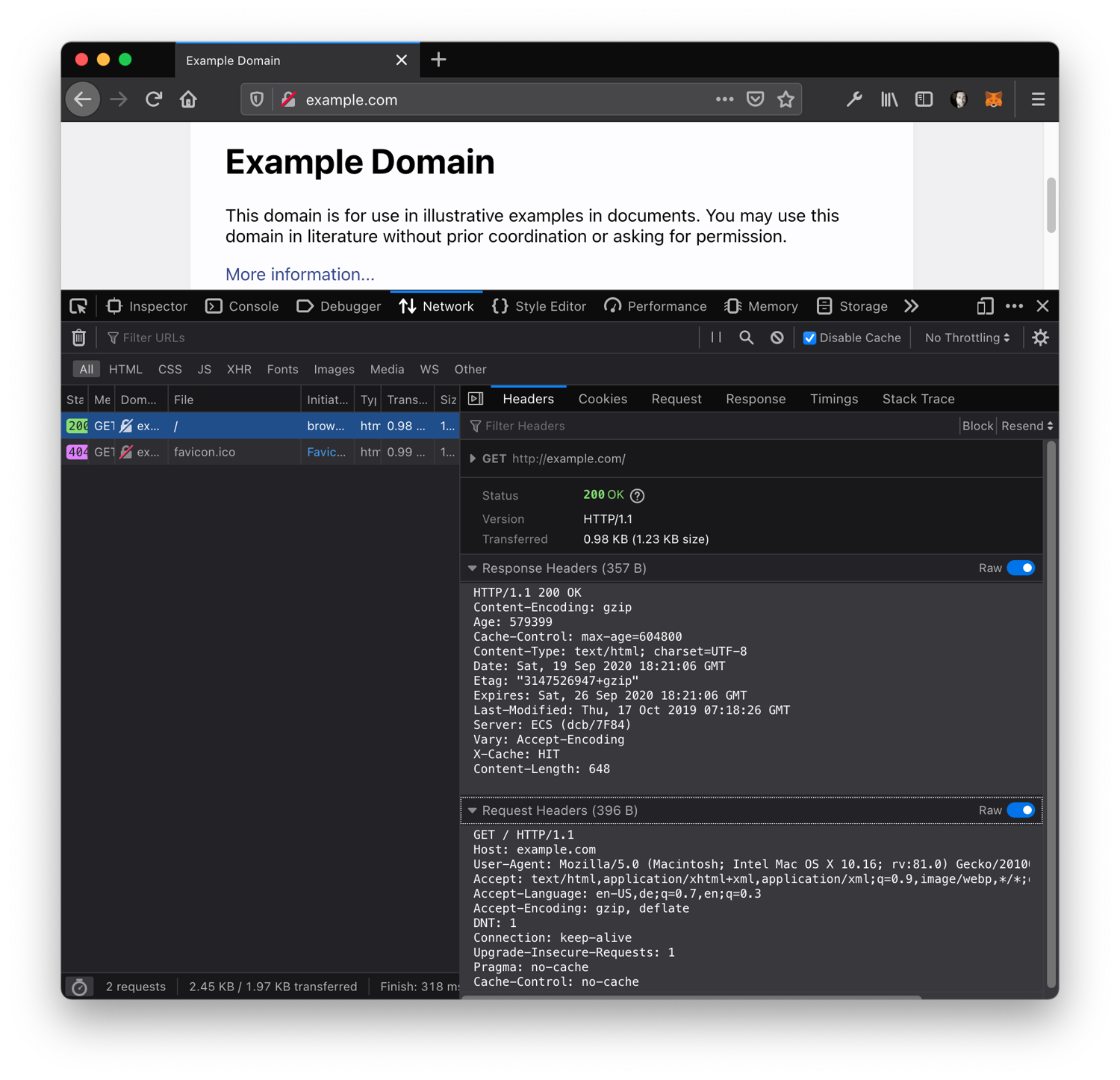
That's quite some request and response headers, but in its most basic form, a request looks like this:
GET / HTTP/1.1
Host: www.example.com
Let's try to recreate with PHP, what the browser just did for us!
fsockopen()
Typically, we won't use much such "low-level" communication, but just for the sake of it, let's create this request with the most basic tool PHP has to offer, fsockopen():
<?php
# fsockopen.php
// HTTP requires "\r\n" In HTTP, lines have to be terminated with "\r\n" because of
$request = "GET / HTTP/1.1\r\n";
$request .= "Host: www.example.com\r\n";
$request .= "\r\n"; // We need to add a last new line after the last header
// We open a connection to www.example.com on the port 80
$connection = fsockopen('www.example.com', 80);
// The information stream can flow, and we can write and read from it
fwrite($connection, $request);
// As long as the server returns something to us...
while(!feof($connection)) {
// ... print what the server sent us
echo fgets($connection);
}
// Finally, close the connection
fclose($connection);
And indeed, if you put this code snippet into a file fsockopen.php and run it with php fsockopen.php, you will see the same HTML that you get when you open http://example.com in your browser.
Next step: performing an HTTP request with Assembler... just kidding! But in all seriousness: fsockopen() is usually not used to perform HTTP requests in PHP; I just wanted to show you that it's possible, using the easiest possible example. While one can handle HTTP tasks with it, it's not fun and requires a lot of boilerplate code that we don't need to write - performing HTTP requests is a solved problem, and in PHP (and many other languages) it's solved by…
cURL
Enter cURL (a client for URLs)!
Let's jump right into the code, it's quite straightforward:
<?php
# curl.php
// Initialize a connection with cURL (ch = cURL handle, or "channel")
$ch = curl_init();
// Set the URL
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
// Set the HTTP method
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');
// Return the response instead of printing it out
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// Send the request and store the result in $response
$response = curl_exec($ch);
echo 'HTTP Status Code: ' . curl_getinfo($ch, CURLINFO_HTTP_CODE) . PHP_EOL;
echo 'Response Body: ' . $response . PHP_EOL;
// Close cURL resource to free up system resources
curl_close($ch);
Now, this already looks less low-level than our previous example, doesn't it? No need to manually compose the HTTP request, establish and manage the TCP connection, or handle the response byte-by-byte. Instead, we only initialise the cURL handle, pass the actual URL, and perform the request using curl_exec.
If, for example, we wanted cURL to automatically handle HTTP redirect 30x codes, we'd only need to add curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);. Plus, there are quite a few additional options and flags to support other use cases.
Great! Now let's get to actual scraping!
If you would like to learn more about cURL without PHP you can check: How to send a GET request using cURL?, How to send a delete request using cURL? or How to send a POST request using cURL?
4. Strings, Regular Expressions, and Wikipedia
Let's look at Wikipedia as our first data provider. Each day of the year has its own page for historical events, including birthdays! When we open, for example, the page for December 10th (which happens to be my birthday), we can inspect the HTML in the developer console and see how the "Births" section is structured:
This looks nice and organized! We can see that:
- There's an
<h2>header element containing<span id="Births" ...>Births</span>(only one element on the whole page should have an ID named "Births"). - Following, is a list of sub-headings (
<h3>) for individual epochs and their list entry elements (<ul>). - Each list entry is represented by a
<li>item, containing the year, a dash, the name of the person, a comma, and a teaser of what the person is known for.
This is something we can work with, isn't it? Let's go!
<?php
# wikipedia.php
$html = file_get_contents('https://en.wikipedia.org/wiki/December_10');
echo $html;
Wait what? Surprise! Yes, file_get_contents() makes use of PHP's fopen wrappers and (as long as they are enabled) can be used to fetch HTTP URLs. Though primarily really meant for local files, it probably is the easiest and fastest way to perform basic HTTP GET requests and is fine for our example here or for quick one-off scripts, as long as you use it carefully.
Have you read all the HTML that the script has printed out? I hope not, because it's a lot! The important thing is that we know where we should start looking: we're only interested in the part starting with id="Births" and ending right before the next <h2>:
<?php
# wikipedia.php
$html = file_get_contents('https://en.wikipedia.org/wiki/December_10');
$start = stripos($html, 'id="Births"');
$end = stripos($html, '<h2>', $offset = $start);
$length = $end - $start;
$htmlSection = substr($html, $start, $length);
echo $htmlSection;
We're getting closer!
This is not valid HTML anymore, but at least we can see what we're working with! Let's use a regular expression to load all list items into an array so that we can handle each item one by one:
preg_match_all('@<li>(.+)</li>@', $htmlSection, $matches);
$listItems = $matches[1];
foreach ($listItems as $item) {
echo "{$item}\n\n";
}

For the years and names… We can see from the output that the first number is the birth year. It's followed by an HTML-Entity – (a dash). Finally, the name is located within the following <a> element. Let's grab 'em all, and we're done 👌.
<?php
# wikipedia.php
$html = file_get_contents('https://en.wikipedia.org/wiki/December_10');
$start = stripos($html, 'id="Births"');
$end = stripos($html, '<h2>', $offset = $start);
$length = $end - $start;
$htmlSection = substr($html, $start, $length);
preg_match_all('@<li>(.+)</li>@', $htmlSection, $matches);
$listItems = $matches[1];
echo "Who was born on December 10th\n";
echo "=============================\n\n";
foreach ($listItems as $item) {
preg_match('@(\d+)@', $item, $yearMatch);
$year = (int) $yearMatch[0];
preg_match('@;\s<a\b[^>]*>(.*?)</a>@i', $item, $nameMatch);
$name = $nameMatch[1];
echo "{$name} was born in {$year}\n";
}
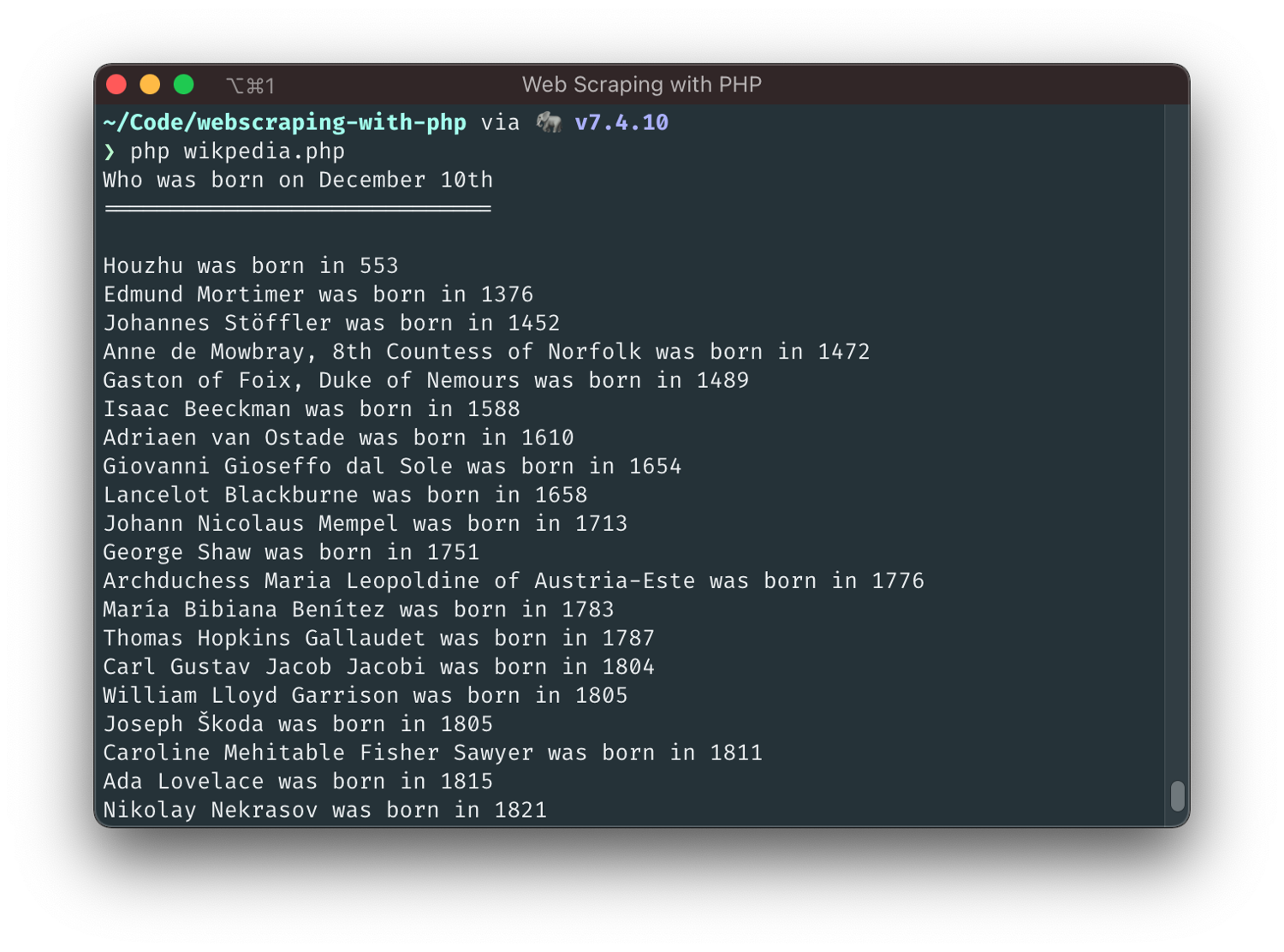
Perfect, isn't it? It works and we managed to get the data we wanted, right? Well, it does work, but we did not choose a particularly elegant approach. Instead of handling the DOM tree, we resorted to "brute-force" string parsing of the HTML code and, in that, missed out on most of what DOM parsers already provide out-of-the-box. Not ideal.
We can do better! When? Now!
5. Guzzle, XML, XPath, and IMDb
Guzzle is a popular HTTP Client for PHP that makes it easy and enjoyable to send HTTP requests. It provides you with an intuitive API, extensive error handling, and even the possibility of extending its functionality with additional plugins/middleware. This makes Guzzle a powerful tool that you don't want to miss. You can install Guzzle from your terminal with composer require guzzlehttp/guzzle.
Let's cut to the chase and have a look at the HTML of https://www.imdb.com/search/name/?birth_monthday=12-10 (Wikipedia's URLs were definitely nicer)
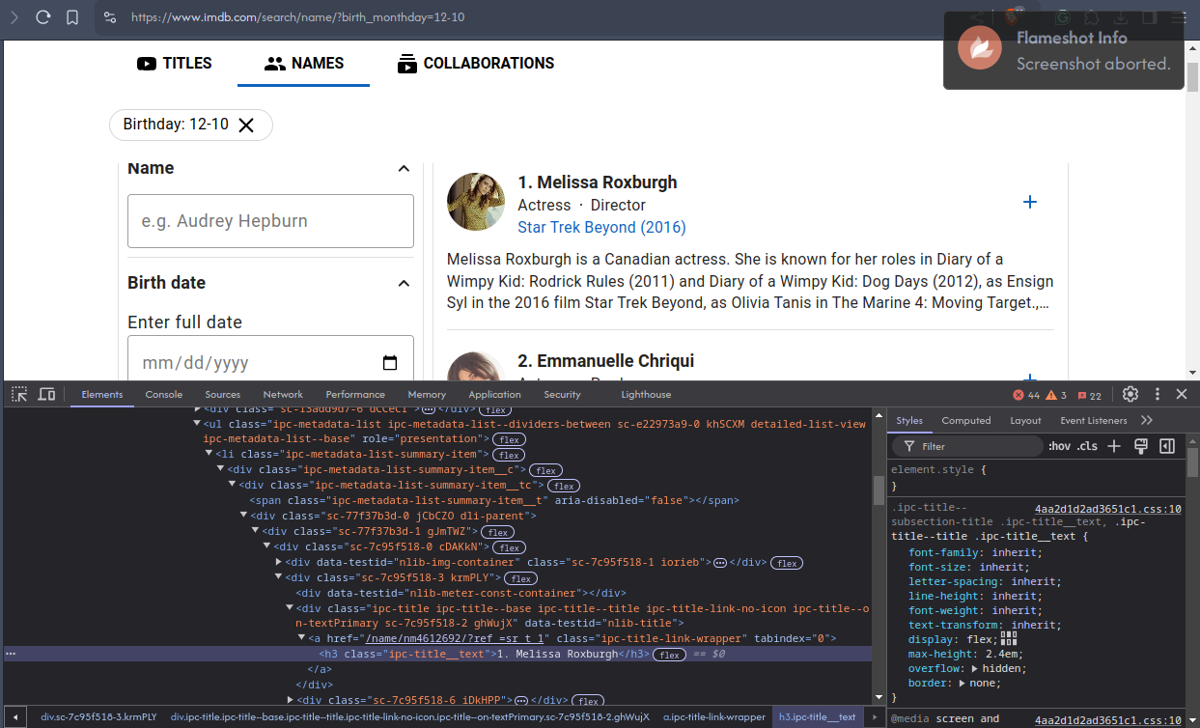
We can see straight away that we'll need a better tool than string functions and regular expressions here. Inside a list with list items, we also see nested <div>s. There's no id="..." that we can use to jump to the relevant content. But worst of all: the birth year is either buried in the biography excerpt or not visible at all! 😱
We'll try to find a solution for the year situation later, but for now, let's at least get the names of our jubilees with XPath, a query language to select nodes from a DOM Document.
In our new script, we'll first fetch the page with Guzzle, convert the returned HTML string into a DOMDocument object, and initialize an XPath parser with it:
<?php
# imdb.php
require 'vendor/autoload.php';
$httpClient = new \GuzzleHttp\Client();
$response = $httpClient->get('https://www.imdb.com/search/name/?birth_monthday=12-10', [
'headers' => [
// Pretending we're Chrome on Android
'User-Agent' => 'Mozilla/5.0 (Linux; Android 12; Pixel 6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.58 Mobile Safari/537.36',
]
]);
$htmlString = (string) $response->getBody();
// HTML is often wonky, this suppresses a lot of warnings
libxml_use_internal_errors(true);
$doc = new DOMDocument();
$doc->loadHTML($htmlString);
$xpath = new DOMXPath($doc);
Let's have a closer look at the HTML in the window above:
- The list is contained in a
<ul class="ipc-metadata-list">element - Each direct child of this container is a
<li>, containing multiple nested<div>s - Finally, the name can be found within a
<h3 class="ipc-title__text">element
If we look closer, we can make it even simpler and skip the child <div>s and class names: there is only one <h3> in a list item, and only one list that contains <h3>s, so let's target that directly:
$names = $xpath->evaluate('//ul//h3');
foreach ($names as $name) {
echo $name->textContent.PHP_EOL;
}
Let's break that quickly down.
//ulreturns the<ul>tags- within these
<ul>s, return all<h3>elements (//h3) - We then iterate through the result and print the text content of the
<h3>elements
I hope I explained it well enough for this use case, but in any case, our article "Practical XPath for Web Scraping" here on the blog explains XPath far better and goes much deeper than I ever could, so definitely check it out (but finish reading this one first! 💪)
Guzzle is a great HTTP client, but many others are equally excellent - it just happens to be one of the most mature and most downloaded. PHP has a vast, active community; whatever you need, there's a good chance someone else has written a library or framework for it, and web scraping is no exception.
Finally, if you noticed, we had to specify a User-Agent header while making the HTTP request, with the string spoofing that of Chrome on Android. Otherwise, we'd get blocked by IMDb's WAF (Web Application Firewall) service. This is just one of the many defenses websites can mount against bots. Bypassing these protections and getting the data you need is an ever-changing art in itself, and that's where a service like ScrapingBee can make your life easier. In the next section, let's see how we can use the ScrapingBee API within our PHP code.
6. ScrapingBee API
ScrapingBee provides an API service that enables you to easily bypass any website's anti-scraping measure without managing complex infrastructure. With a single API call, you can fetch a page and extract any data, based on custom path sets. The API provides common scraping features such as JavaScript rendering, Proxy/IP rotation, and HTML parsing - so you don't have to set them up. It also has an AI query feature; using that you can extract structured data from any given URL without wrangling with the HTML structure and CSS/XPath selectors.
Let's do a quick demonstration of the API, for the same use case: getting data from IMDb. We'll try to get the actors' names from the filtered list; first using XPath selectors, and then with AI text prompts. To follow along, you will need a ScrapingBee API key which you can get here with 1,000 free credits.
Regular Method: Using XPath Selectors
<?php
#sb_xpath.php
// add your API key here
$SB_API_KEY = '<YOUR_KEY>';
// define ScrapingBee API endpoint
$SB_ENDPOINT = 'https://app.scrapingbee.com/api/v1/';
// define extract rules
$extract_rules = json_encode([
'actor_names' => [
'selector' => '//ul//h3',
'type' => 'list',
'output' => 'text'
]
]);
// construct the GET query string
$query = http_build_query([
'api_key' => $SB_API_KEY,
'url' => 'https://www.imdb.com/search/name/?birth_monthday=12-10',
'extract_rules' => $extract_rules,
]);
// Prepare cURL
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $SB_ENDPOINT.'?'.$query);
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// send the request and save response to $response
$response = curl_exec($ch);
// stop if fails
if (!$response) {
die('Error: "' . curl_error($ch) . '" - Code: ' . curl_errno($ch));
}
$json_body = json_encode(json_decode($response), JSON_PRETTY_PRINT);
echo 'HTTP Status Code: ' . curl_getinfo($ch, CURLINFO_HTTP_CODE) . PHP_EOL;
echo "Response Body: \n" . $json_body . PHP_EOL;
// close curl resource to free up system resources
curl_close($ch);
In the above code, we initialized cURL and called the ScrapingBee endpoint with the URL we need to scrape, and an extract_rules parameter specifying the field name we need in the output, along with the same XPath selector that we used earlier. Let's see what this gives us:
HTTP Status Code: 200
Response Body:
{
"actor_names": [
"1. Melissa Roxburgh",
"2. Emmanuelle Chriqui",
"3. Kenneth Branagh",
...
"48. Teddy Wilson",
"49. Bobby Flay",
"50. Una Merkel"
]
}
We get a neat list with the names of 50 actors in the response body. Wasn't that easy?
Using AI Selectors
I'll be honest: when this tutorial was first written, IMDb had a different HTML structure. Two years later, IMDb had changed its HTML structure and the examples had stopped working because the HTML elements and class names had changed. This is the kind of scenario where the ScrapingBee AI selector feature would come in particularly handy. Using this feature, you can define ai_extract_rules using AI prompts instead of CSS/XPath selectors, and the AI will get the data you need, in a structured format! To do this, we'll change just the query string from the above API call:
// define AI extract rules
$ai_extract_rules = json_encode([
'actor_names' => 'List of Actor Names in the Page',
]);
// construct the GET query string
$query = http_build_query([
'api_key' => $SB_API_KEY,
'url' => 'https://www.scrapingbee.com/blog/api-for-dummies-learning-api/',
'ai_extract_rules' => $ai_extract_rules,
]);
Let's see what this gives us:
HTTP Status Code: 200
Response Body:
{
"actor_names": [
"Melissa Roxburgh",
"Emmanuelle Chriqui",
"Kenneth Branagh",
...
"Teddy Wilson",
"Bobby Flay",
"Una Merkel"
]
}
With a very minor change in the code, we dropped our reliance on CSS/XPath selectors, and yet obtained a similar output. In fact, the AI output is cleaner - the leading numbers have been removed automatically and we have just the names.
In addition to dealing with changing HTML structures, the AI query feature can be very helpful when you are scraping from multiple websites with diverse HTML structures; or even if you simply do not want to dive into the HTML structure of a site. Read more about ScrapingBee's AI Web Scraping Feature here.
For further reading on AI Web Scraping here are a couple of guides on how to do it:
- How to Easily Scrape Any Shopify Store With AI
- Free AI-Powered Proxy Scraper for Getting Fresh Public Proxies
7. Goutte, Symfony, and IMDB
Goutte is an HTTP client made for web scraping. It was created by Fabien Potencier, the creator of the Symfony Framework, and used to combine several Symfony components to make web scraping very comfortable:
- The BrowserKit component simulates the behavior of a web browser that you can use programmatically.
- Think of the DomCrawler component as DOMDocument and XPath on steroids - except that steroids, and DomCrawler is good!
- The CssSelector component translates CSS selectors to XPath expressions.
- The Symfony HTTP Client is developed and maintained by the Symfony team and, naturally, easily integrates into the overall Symfony ecosystem.
At this time, the Goutte library has been deprecated. The author instead suggests that we use the HttpBrowser class from the Symfony BrowserKit component. The last version of Goutte is only a proxy to this class, and the migration can be done by replacing
Goutte\ClientwithSymfony\Component\BrowserKit\HttpBrowserin our code.
To get started, let's individually install the Symfony components that used to be a part of Goutte:
composer require symfony/browser-kit
composer require symfony/dom-crawler
composer require symfony/css-selector
composer require symfony/http-client
Next, let's recreate the previous XPath example with it:
<?php
# goutte_xpath.php
require 'vendor/autoload.php';
$client = new Symfony\Component\BrowserKit\HttpBrowser();
$crawler = $client->request('GET', 'https://www.imdb.com/search/name/?birth_monthday=12-10');
$crawler->evaluate('//ul//h3')->each(function ($node) {
echo $node->text().PHP_EOL;
});
This alone is already pretty good - we saved the step where we had to explicitly disable XML warnings and didn't need to instantiate an XPath object ourselves. Now, let's use a "native" CSS selector instead of the manual XPath evaluation (thanks to the CssSelector component):
<?php
# goutte_css.php
require 'vendor/autoload.php';
$client = new Symfony\Component\BrowserKit\HttpBrowser();
$crawler = $client->request('GET', 'https://www.imdb.com/search/name/?birth_monthday=12-10');
$crawler->filter('ul h3')->each(function ($node) {
echo $node->text().PHP_EOL;
});
I like where this is going; our script is more and more looking like a conversation that even a non-programmer can understand, not just code 🥰. However, now is the time to find out if you're coding along or not 🤨: does this script return results when running it? Because for me, it didn't at first - I spent an hour debugging why and finally discovered a solution. It should've been fixed by now, but if it hasn't:
composer require masterminds/html5
As it turns out, the reason why the DOMCrawler doesn't report XML warnings is that it just throws away the parts it cannot parse. The additional library helps with HTML5 specifically, and after installing it, the script runs as expected.
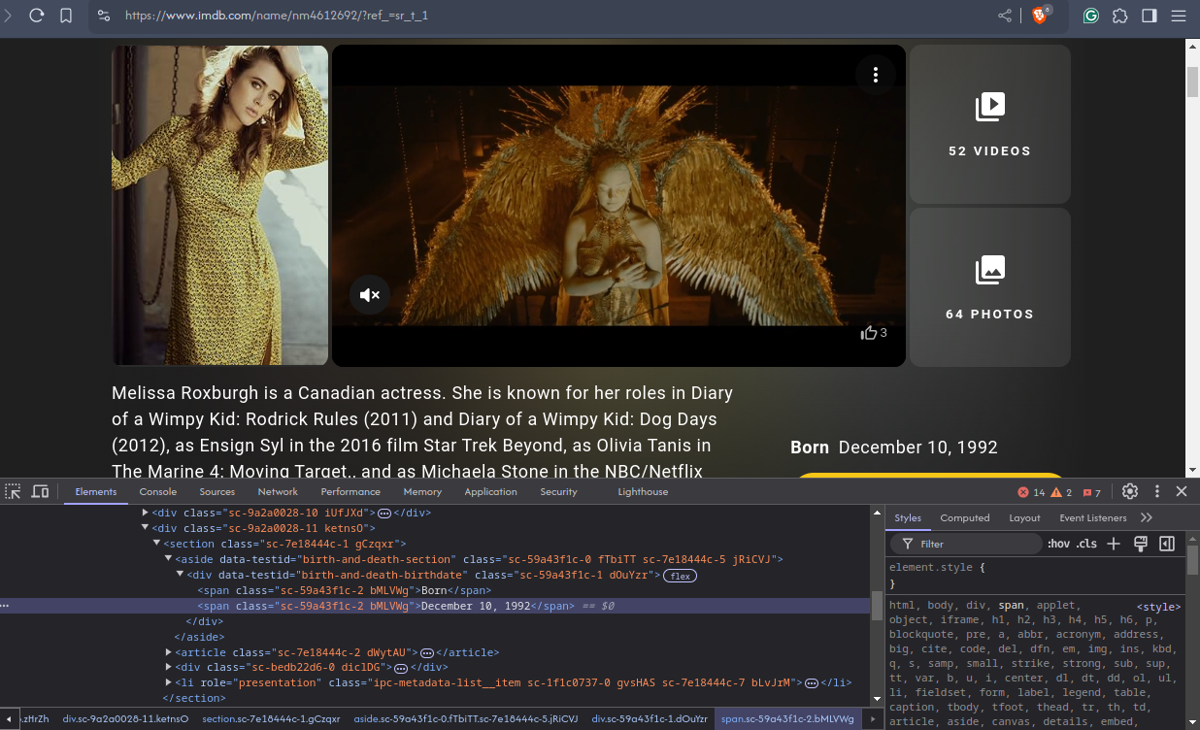
We will talk more about this later, but for now, let's remember that we're still missing the birth years of our jubilees. This is where a web scraping library like Goutte really shines: we can click on links! And indeed: if we click one of the names in the birthday list to go to a person's profile, we can see a "Born: [birthdate]" line, and in the HTML a <div data-testid='birth-and-death-birthdate'> element containing two <span>s:
This time, I will not explain the single steps that we're going to perform beforehand, but just present you the final script; I believe that it can speak for itself:
<?php
# imdb_birthdates.php
require 'vendor/autoload.php';
$client = new Symfony\Component\BrowserKit\HttpBrowser();
$crawler = $client
->request('GET', 'https://www.imdb.com/search/name/?birth_monthday=12-10');
$crawler
->filter('ul a.ipc-title-link-wrapper')
->each(function ($node) use ($client) {
$name = $node->text();
$birthday = $client
->click($node->link())
->filter('div[data-testid="birth-and-death-birthdate"] span')
->getNode(1)
->textContent.PHP_EOL;
$year = explode(", ", $birthday)[1];
echo "{$name} was born in {$year}";
});
Look at this clean output:
1. Melissa Roxburgh was born in 1992
2. Emmanuelle Chriqui was born in 1975
3. Kenneth Branagh was born in 1960
...
23. Teyana Taylor was born in 1990
24. Kristine DeBell was born in 1954
25. Harold Gould was born in 1923
As there are 25 people on the page, 25 additional GET requests have to be made, so the run of the script will take a bit longer now, but we now have the birthdays for each of these 25 people as well.
Great, but what about the others you say? And you are right, there are more than 1,000 people listed on IMDb, who share December 10th as their birthday and we should not just ignore them.
9. Headless Browsers
When content is split into different pages, it always gets a bit tricky, as you'll need to handle the page management as well and change to the next page, once you have accessed all data on the current page. IMDb used to follow a traditional approach with Next » buttons, and we simply had to scrape the next page using the link and run the same code, repeating until there was no next page. Now, that has changed; IMDb loads more data dynamically using JavaScript when the next button is pressed.
Here's a thing: when we looked at the HTML DOM tree in the Developer Console, we didn't see the actual HTML code that has been sent from the server to the browser, but the final result of the browser's interpretation of the DOM Tree. If a site does not use JavaScript, that output will not differ much, but the more JavaScript the site runs, the more likely it will change the DOM tree from what the server originally sent.
When a website uses AJAX to dynamically load content, or when even the complete HTML is generated dynamically with JavaScript, we cannot access it by just downloading the original HTML document from the server. Tools like BrowserKit/Goutte can simulate a lot when it comes to browser behaviour, but they still have their limits. This is where so-called headless browsers come into play.
A headless browser runs a full-fledged browser engine without the graphical user interface and it can be controlled programmatically in a similar way as we did before with the simulated browser.
Symfony Panther is a standalone library that provides the same APIs as Goutte - this means you could use it as a drop-in replacement in our previous Goutte scripts. A nice feature is that it can use an already existing installation of Chrome or Firefox on your computer so that you don't need to install additional software.
So let's extend our previous code example in a way, that it does not only crawl the first page but gets us the first 250 actors.
After installing Panther with composer require symfony/panther we could write our script for example like this:
<?php
# headless.php
require 'vendor/autoload.php';
$client = \Symfony\Component\Panther\Client::createFirefoxClient();
// or "createChromeClient()" for a Chrome instance
// $client = \Symfony\Component\Panther\Client::createChromeClient();
$main_page = $client
->request('GET', 'https://www.imdb.com/search/name/?birth_monthday=12-10');
$links = $main_page->filter('ul a.ipc-title-link-wrapper');
while ($links->count() < 250) {
// click the more button
$client->executeScript("document.querySelector('span.single-page-see-more-button button').click()");
// allow some time for data to load
sleep(5);
// extract all actors' <a> elements
$links = $main_page->filter('ul a.ipc-title-link-wrapper');
}
// Extract hrefs from the <a> elements.
$urls = $links->each(function ($node) use ($client) {
return $node->getAttribute('href');
});
// Get birthday from each page
foreach ($urls as $url) {
$page = $client
->request('GET', 'https://www.imdb.com'.$url);
$name = $page->filter('h1')->first()->getText();
$birthday = $page
->filter('div[data-testid="birth-and-death-birthdate"] span')
->getElement(3)
->getText();
$year = explode(", ", $birthday)[1];
echo "{$name} was born in {$year}".PHP_EOL;
}
Output snippet:
Melissa Roxburgh was born in 1992
Emmanuelle Chriqui was born in 1975
Kenneth Branagh was born in 1960
Michael Schoeffling was born in 1960
Fionnula Flanagan was born in 1941
Michael Clarke Duncan(1957-2012) was born in 1957
Patrick John Flueger was born in 1983
Summer Phoenix was born in 1978
Nia Peeples was born in 1961
...250 lines
Summary
At this point, our code is still pretty concise and yet does almost all we went out to do - except it gets only 250 out of all the 1,000+ actor profiles. It starts at the given IMDb link, collects the listed profiles, page-by-page and then the dates of birth from the pages of the individual actors.
As the component handles everything by default request-by-request, it will certainly take a bit of time to fetch all 1,000+ profiles and that's exactly an opportunity to build upon for further enhancements:
- Get all the actors: we could scrape the actor count shown on the results page, and use that as the upper limit instead of 250.
- Guzzle supports concurrent requests. Perhaps we could leverage that to improve the processing speed; get the actor page links with BrowserKit and then the individual pages with Guzzle.
- IMDb features pictures for most of their listings, wouldn't it be lovely to have the profile picture of each actor? (hint:
ul img.ipc-image[src])
Conclusion
We've learned about several ways to scrape the web with PHP today. Still, there are a few topics that we haven't spoken about - for example, website owners often prefer their sites to be accessed only by end-users and are not too happy if they are accessed in any automated fashion.
- When we loaded all the pages in quick succession, IMDb could have interpreted this as unusual and could have blocked our IP address from further accessing their website.
- Many websites have rate limiting in place to prevent Denial-of-Service attacks.
- Depending on in which country you live and where a server is located, some sites might not be available from your computer.
- Managing headless browsers for different use cases can take a performance toll on your machine (mine sounded like a jet engine at times).
ℹ️ For more on the basics of Goutte check out our Goutte tutorial.
That's where services like ScrapingBee can help: you can use the ScrapingBee API to delegate thousands of requests per second without the fear of getting limited or even blocked so that you can focus on what matters: the content 🚀.
I hope you liked this article, if you're more old school, check out this Web scraping with Perl article
If you'd rather use something free, we have also benchmarked thoroughly the most used free proxy provider.
If you want to read more about web scraping without being blocked, we have written a complete guide on how to avoid getting blocked while scraping, but we still would be delighted if you decided to give ScrapingBee a try, the first 1,000 requests are on us!



