Twitter is a gold mine for data. It started as a micro-blogging website and has quickly grown to become the favorite hangout spot for millions of people. Twitter provides access to most of its data via its official API but sometimes that is not enough.
Web scraping provides some advantages over using the official API. For example, Twitter's API is rate-limited and you need to wait for a while before Twitter approves your application request and lets you access its data but this is not the case with web scraping.
In this article, you will learn how to use Selenium to scrape public profile data from Twitter.
Setting up the prerequisites
This tutorial uses Python 3.10 but should work with most Python versions. Start by creating a new directory where all of your project files will be stored and then create a new Python file within it for the code itself:
$ mkdir scrape_twitter
$ cd scrape_twitter
$ touch app.py
You will need to install a few different libraries to follow along:
You can install both of these libraries using this command:
$ pip install selenium webdriver-manager
Selenium will provide you with all the APIs for programmatically accessing a browser and the webdriver-manager will help you in setting up a browser's binary driver easily without the need to manually download and link to it in your code.
Fetching a profile page
Let's try fetching a Twitter profile page using Selenium to make sure everything is set up correctly. Save the following code in the app.py file:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://twitter.com/yasoobkhalid")
Running this code should open up a Chrome window and navigate it to my Twitter profile. It might take a minute before it opens up the browser window as it might have to download the Chrome driver binary.
The code itself is fairly straightforward. It starts with importing the webdriver, the Service and the ChromeDriverManager. Normally, you would initialize the webdriver by giving it an executable_path for the browser-specific driver binary you want to use:
browser = webdriver.Chrome(executable_path=r"C:\path\to\chromedriver.exe")
The biggest downside for this is that any time the browser updates, you will have to download the updated driver binary for the browser. This gets tiring very quickly and the webdriver_manager library makes it simpler by letting you pass in ChromeDriverManager().install(). This will automatically download the required binary and return the appropriate path so that you don't have to worry about it anymore.
The last line of code asks the driver to navigate to my Twitter profile.
Deciding what to scrape
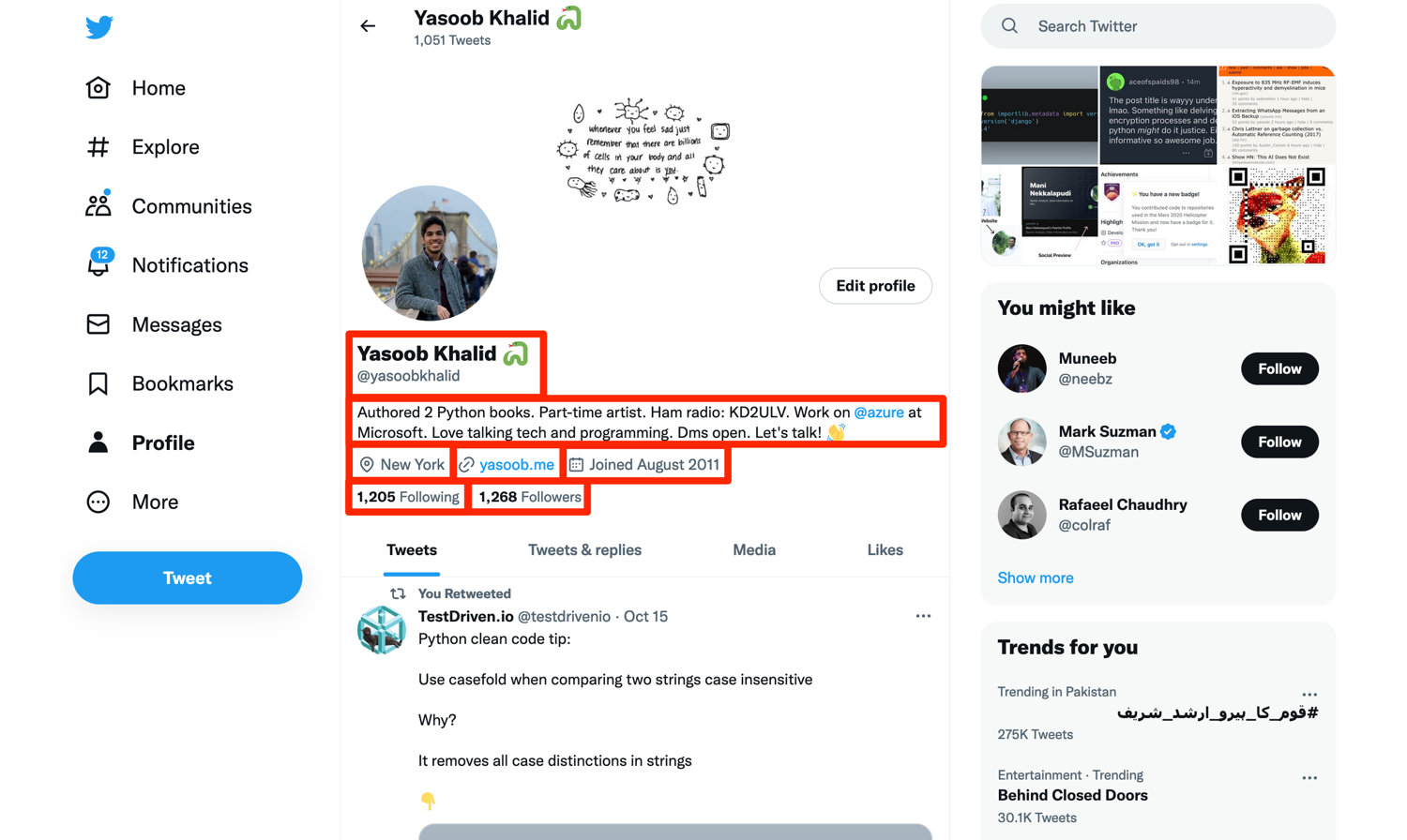
The next step is to figure out what you want to scrape. In this tutorial, you will learn how to scrape:
- profile name
- profile handle
- user location
- User website
- join date
- following count
- followers count
- user tweets
The image below highlights where all of this information is located on the page (except the tweets. We will focus on them in a bit):
Let the extraction begin!
You will be relying on the APIs provided by Selenium to do the web scraping. You will mostly be using XPath and CSS selectors for this purpose. The exact method you will use will be dictated by the HTML structure and which option is more reliable and easy to use.
How to know the page is fully loaded
If you try to extract data as soon as Selenium navigates to the profile page, you will encounter the NoSuchElementException. This occurs because Twitter uses JavaScript to request data from the server and populate the page and the JavaScript hasn't finished executing when the profile page is loaded.
There are a few ways to be sure the page has fully loaded and the data we need is visible on the page. We will be relying on two of these methods.
The first one just makes sure that the page and all of its sub-resources have finished loading. It does this by checking the value of document.readyState property. The value of this property will be "complete" when everything has loaded:
import time
from random import randint
# ...
state = ""
while state != "complete":
print("loading not complete")
time.sleep(randint(3, 5))
state = driver.execute_script("return document.readyState")
The .execute_script method takes in JavaScript code to execute in the current window. There is a random wait added in the while loop just to make sure you are waiting for a little while before checking the status again.
However, this document.readyState method alone is not enough as it takes time for the tweets to be populated on the screen. Twitter launches an XHR request to fetch the tweets after the page has finished loading. If you rely only on this first method and try to extract tweets from the profile, you will encounter the same NoSuchElementException again. This second method will fix this:
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import WebDriverException
# ...
try:
WebDriverWait(driver, 10).until(EC.presence_of_element_located(
(By.CSS_SELECTOR, '[data-testid="tweet"]')))
except WebDriverException:
print("Tweets did not appear!, Try setting headless=False to see what is happening")
Here you are asking Selenium to pause the execution until the DOM element with the data-testid="tweet" attribute is visible on the screen. It will then wait for 10 seconds for this attribute to show up and if it doesn't show up in this time, it will timeout and throw the WebDriverException.
You don't need to worry about how we know about this particular CSS selector for the tweets. We will cover this in a later section.
Extracting the username & handle
Let's open up the profile page in a chrome window, fire up the Developer Tools, and explore the HTML structure of the page:
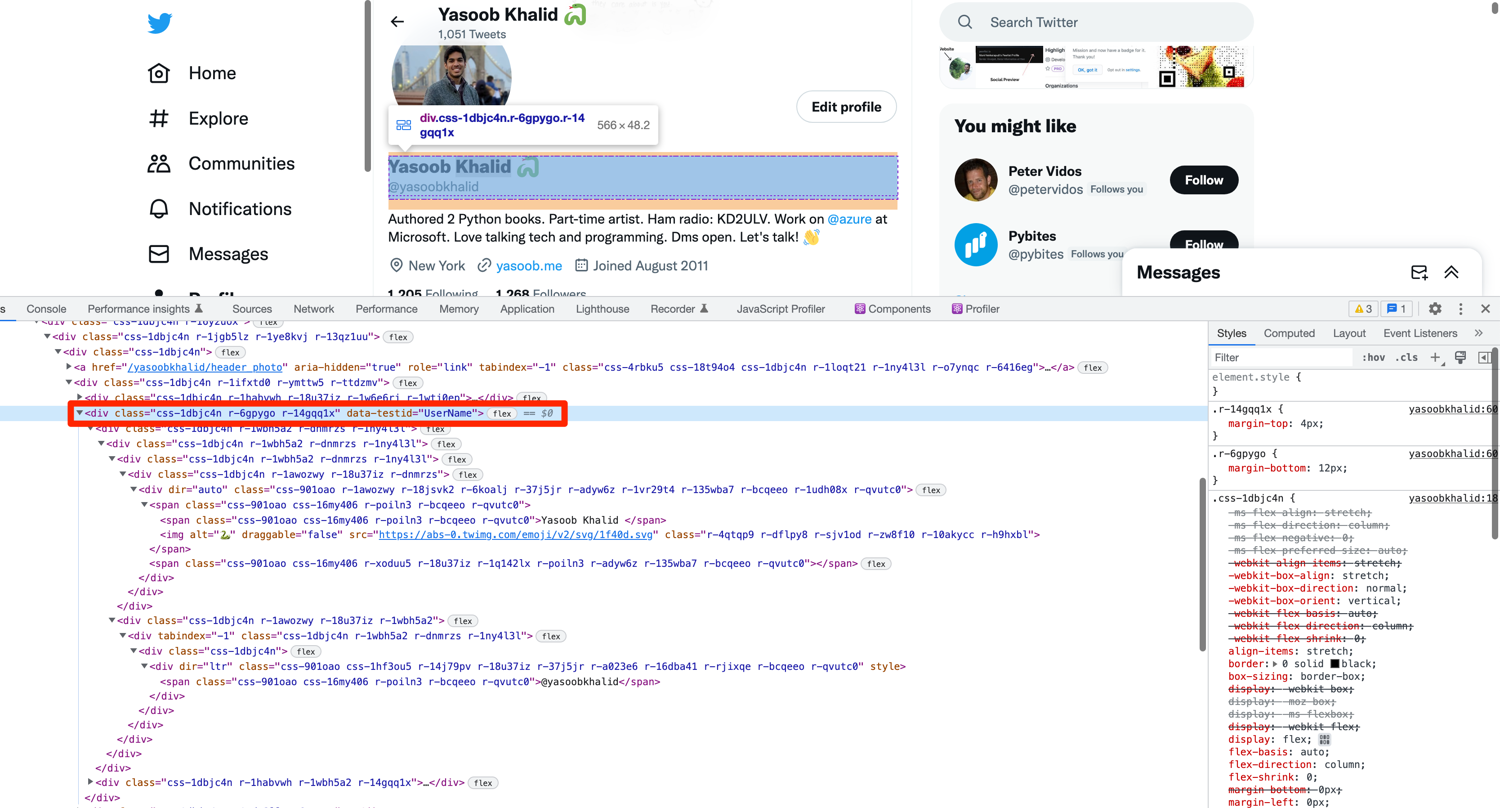
As you can see in the image above, the whole name and handle section is encapsulated in a div. It seems like Twitter generates class names randomly and that is no good if you want to reliably scrape data. Luckily, there does seem to be a data-testid attribute that is unique to this div. If you search for this attribute in the HTML you will quickly observe that there is only one data-testid attribute that has the value of UserName. You can use this to your benefit and tell selenium to extract the name and handle from the div that has this attribute:
from selenium.webdriver.common.by import By
#...
name, username = driver.find_element(By.CSS_SELECTOR,'div[data-testid="UserName"]').text.split('\n')
Here you are using the CSS_SELECTOR to target this particular div and then extracting the visible text from it. This returns the name and username/handle with a newline character in between. You are then splitting the resulting string at the newline character and assigning the return values to name and username variables.
Extracting user bio
Right-click on the user bio and click on "inspect". This will open up the relevant section of the DOM in the developer tools window:
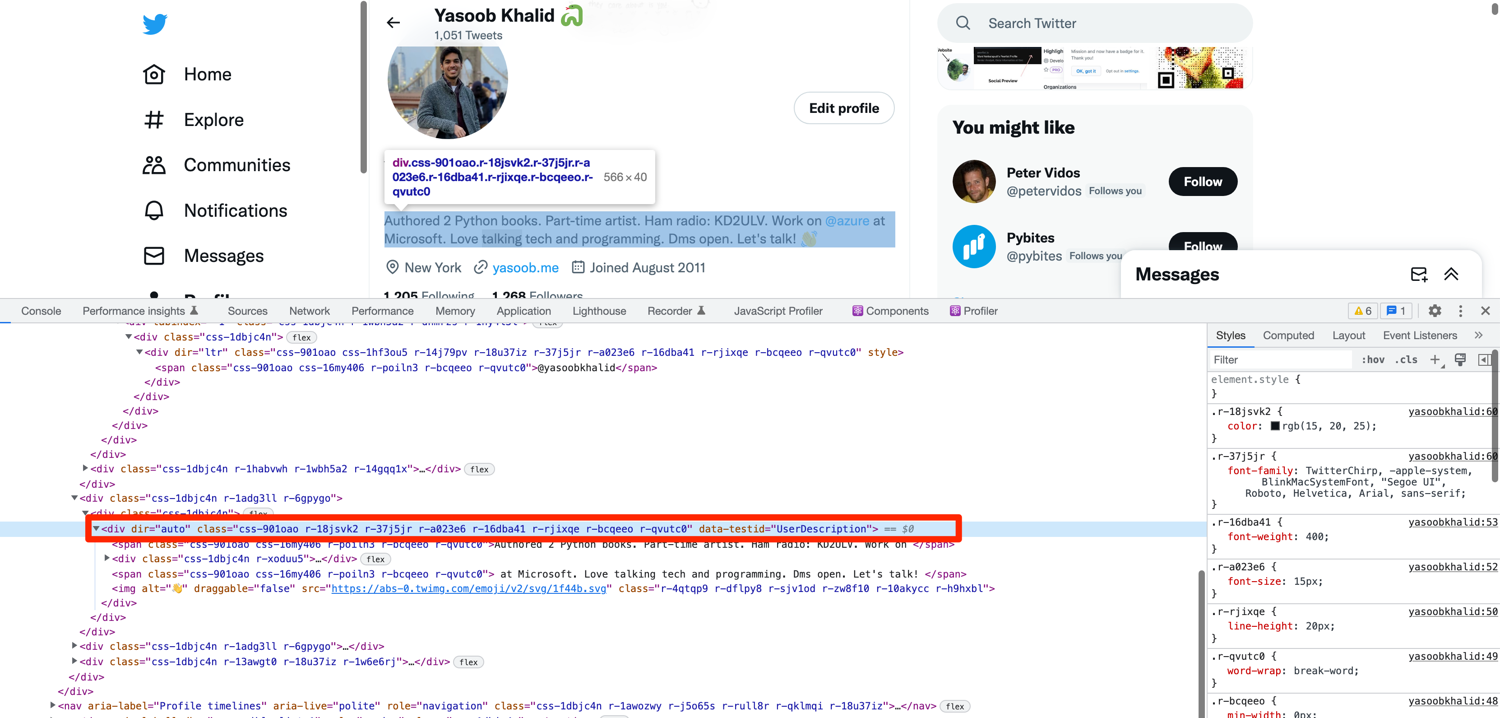
This is the same as the username and handle section. All the CSS classes are randomly generated. However, there is a data-testid attribute for this div as well and it is also unique on this page. You can target this attribute and then extract the text from the div:
bio = driver.find_element(By.CSS_SELECTOR,'div[data-testid="UserDescription"]').text
You can try to be a bit more precise and figure out what children tags you need to extract the bio from but that is going to be unnecessary and somewhat useless as there is no other visible text other than the bio in this div.
Extracting location, website, & join date
The location, website, and join date have a similar extraction method. Look at the image below which shows the DOM structure of the location:
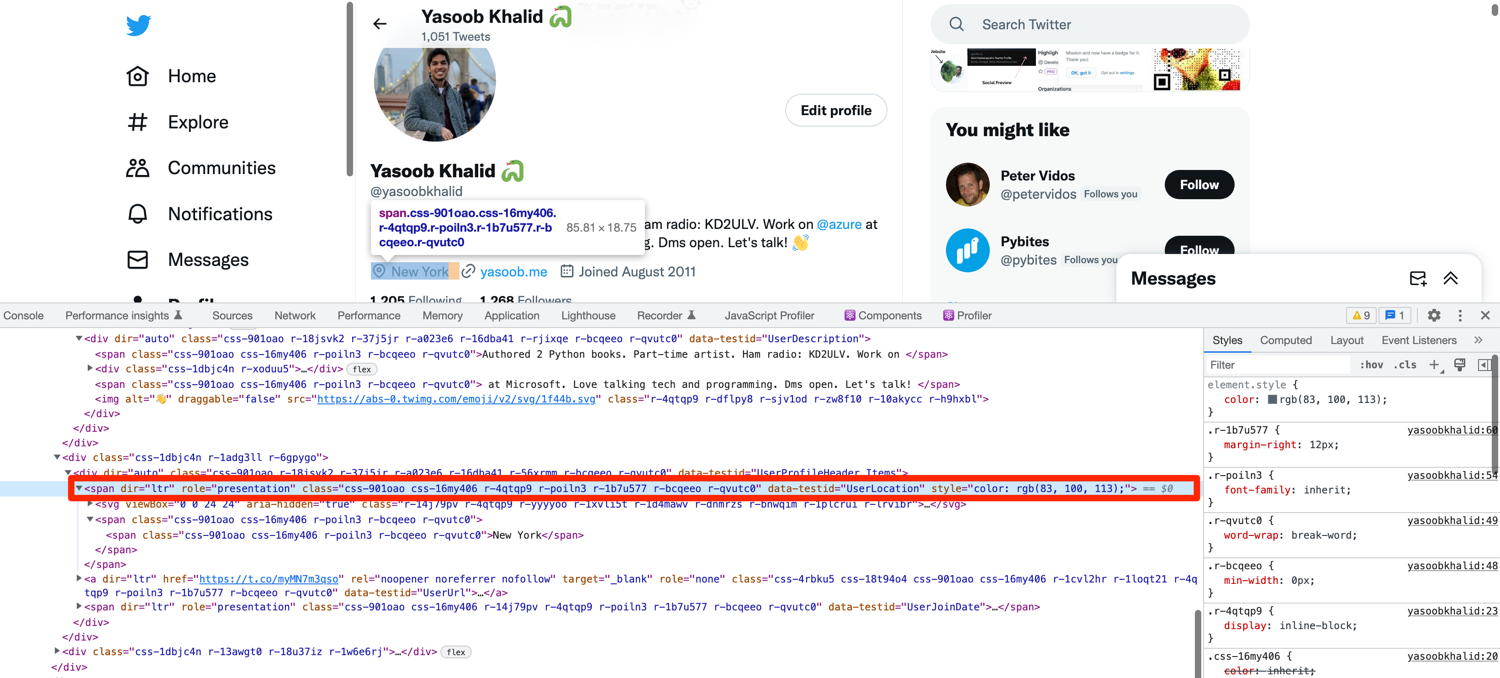
This span also has the data-testid attribute defined. The same is the case for the website and join date. You can extract all three of these using the same method we used for the previous two extractions:
location = driver.find_element(By.CSS_SELECTOR,'span[data-testid="UserLocation"]').text
website = driver.find_element(By.CSS_SELECTOR,'a[data-testid="UserUrl"]').text
join_date = driver.find_element(By.CSS_SELECTOR,'span[data-testid="UserJoinDate"]').text
Extracting followers and following count
This one is going to be slightly different as there doesn't seem to be any data-testid attribute defined for the tags containing the followers and following count. Look at the DOM structure of the parent tags containing the following count:
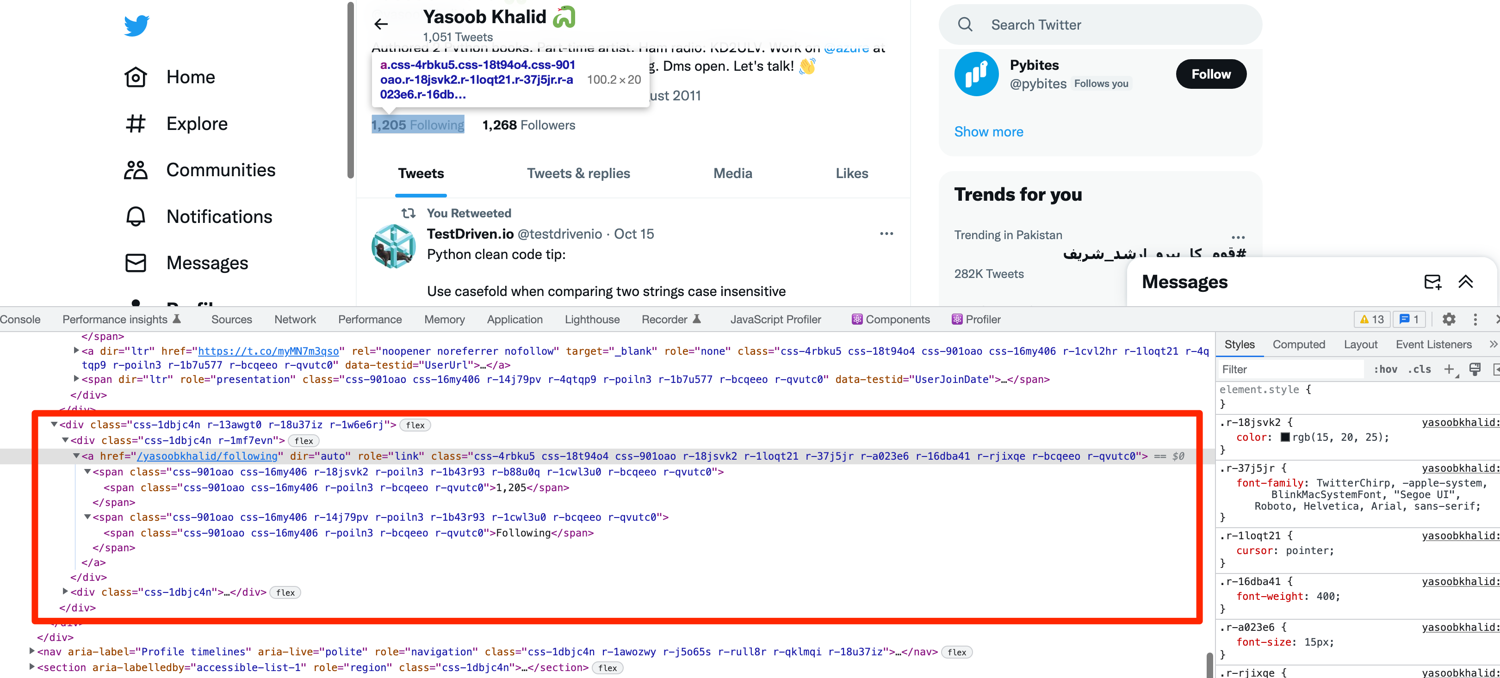
This seems tricky at first but has a surprisingly easy solution. You can use XPath for targeting these tags. XPath allows you to find a tag on the page based on the text it contains. This is useful as there is only one location on the page where the word "Following" is found. Let me show you the XPath and then explain what is happening:
following = driver.find_element(By.XPATH, "//span[contains(text(), 'Following')]/ancestor::a/span").text
//span[contains(text(), 'Following')]tells Selenium to find the span that contains the text "Following"/ancestor::atells Selenium to go to thea(anchor tag) ancestor of thisspan/spantells selenium to move down to the very first childspanof theatag
Look at the DOM structure above and you will see what is happening. We first target the span containing the "Following" string. Then we traverse upwards to the a tag and then again traverse downwards to the first span child of the a tag and extract the text from it.
The same is the case for the "Followers" count:
followers = driver.find_element(By.XPATH, "//span[contains(text(), 'Followers')]/ancestor::a/span").text
Extracting tweets
The profile page contains tweets as well as retweets. We will not distinguish between them for now and will consider all of them as simply Tweets. Open up the developer tools and start inspecting a tweet:
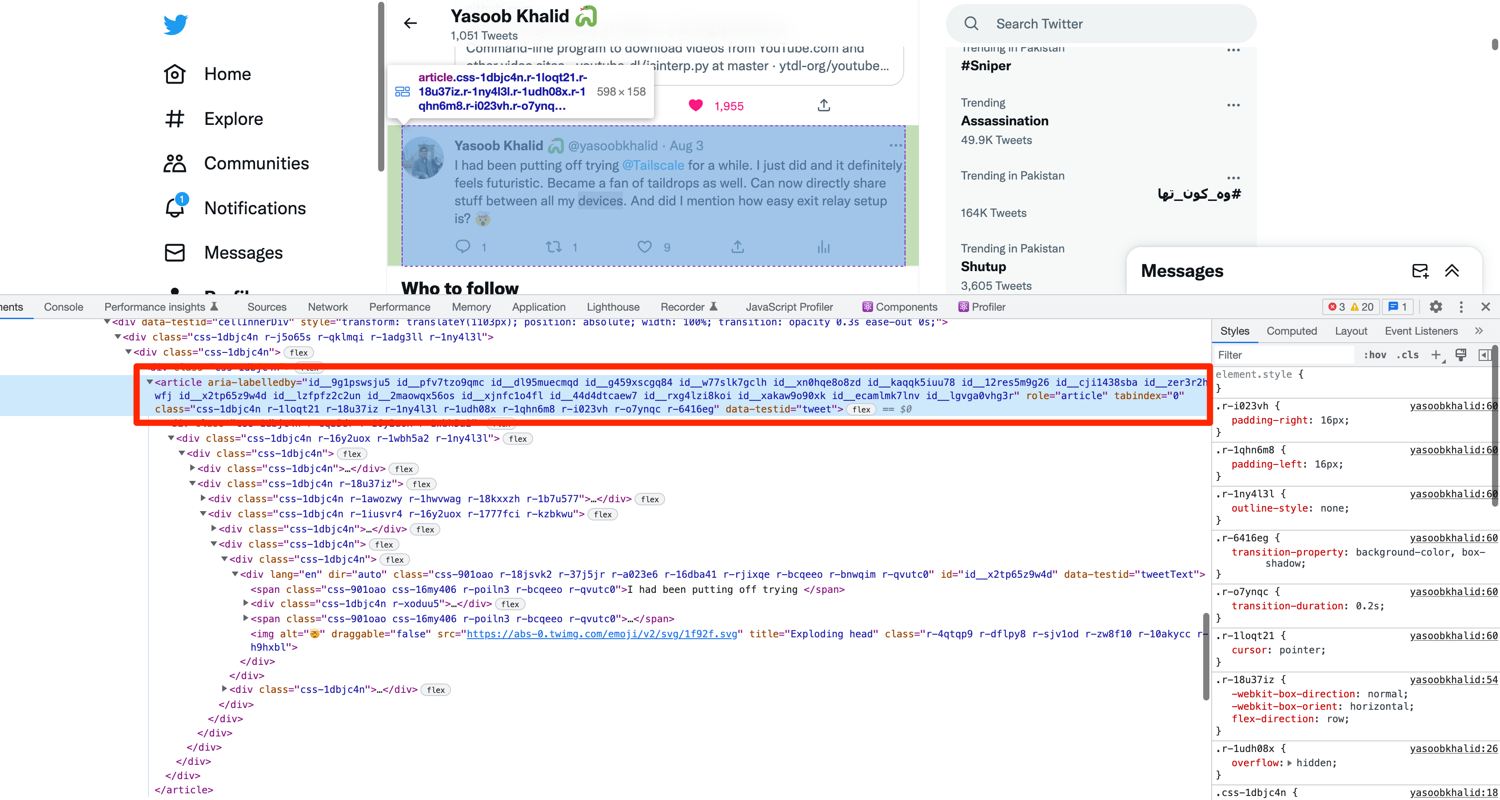
Turns out that the tweets also have a data-testid defined. You can use this to extract all of the tweets from the page:
tweets = driver.find_elements(By.CSS_SELECTOR, '[data-testid="tweet"]')
Note that here we are using find_elements as compared to find_element. find_element only returns the first element with the matching conditions whereas find_elements returns all the elements with the matching conditions. You have to use the latter here because there are multiple tweets on the profile page with the same data-testid and you need to extract all of them.
From here on you can go over each tweet in this list and extract the relevant data. Let's start by extracting the tweet author. Each tweet's author name and author handle are wrapped in a div with the data-testid of User-Names:
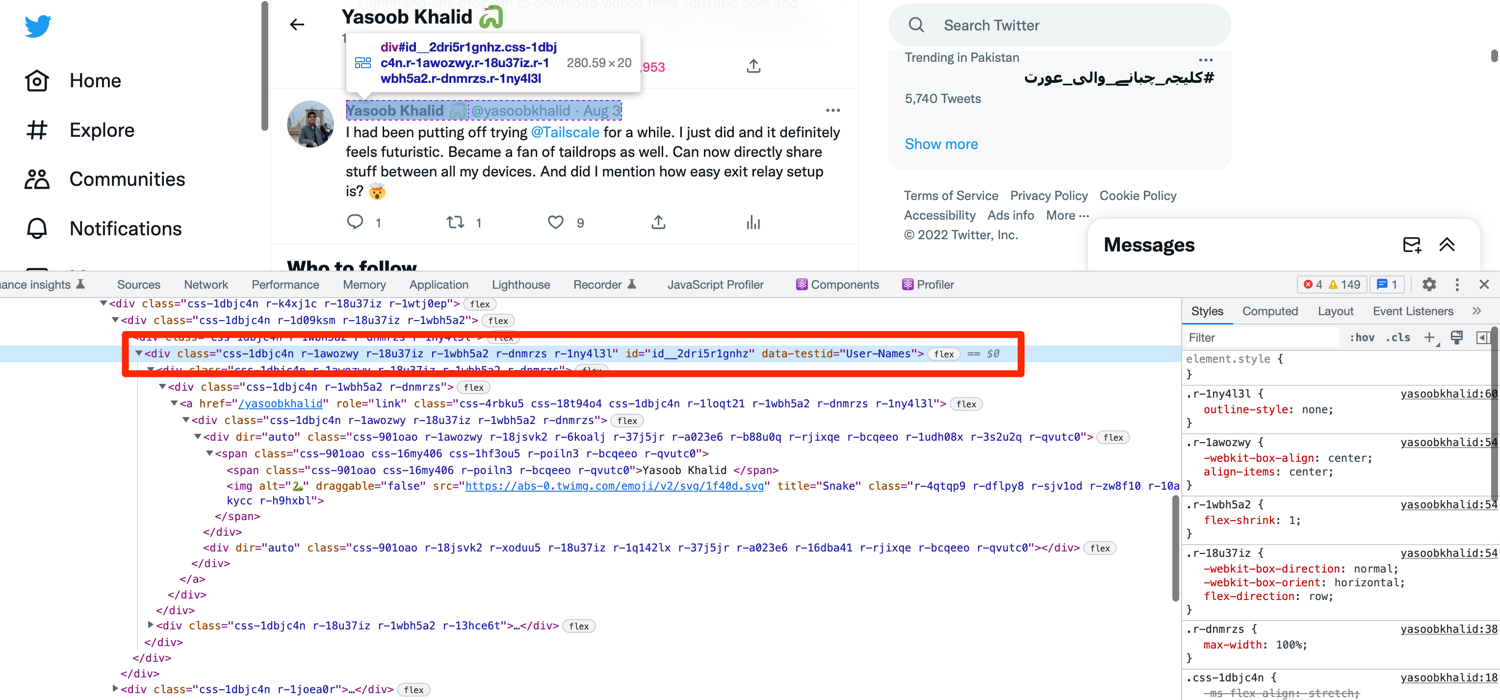
If you try to extract the text from this div, it will return the following:
>>> print(tweet.find_element(By.CSS_SELECTOR,'div[data-testid="User-Names"]').text)
Yasoob Khalid
@yasoobkhalid
·
Aug 3
You can simply split the text at the newline character (\n) and extract the name and handle of the tweet author and the timestamp of the tweet:
for tweet in tweets:
tag_text = tweet.find_element(By.CSS_SELECTOR,'div[data-testid="User-Names"]').text
name, handle, _, timestamp = tag_text.split('\n')
The tweet text is also encapsulated in a div with a distinct data-testid attribute:
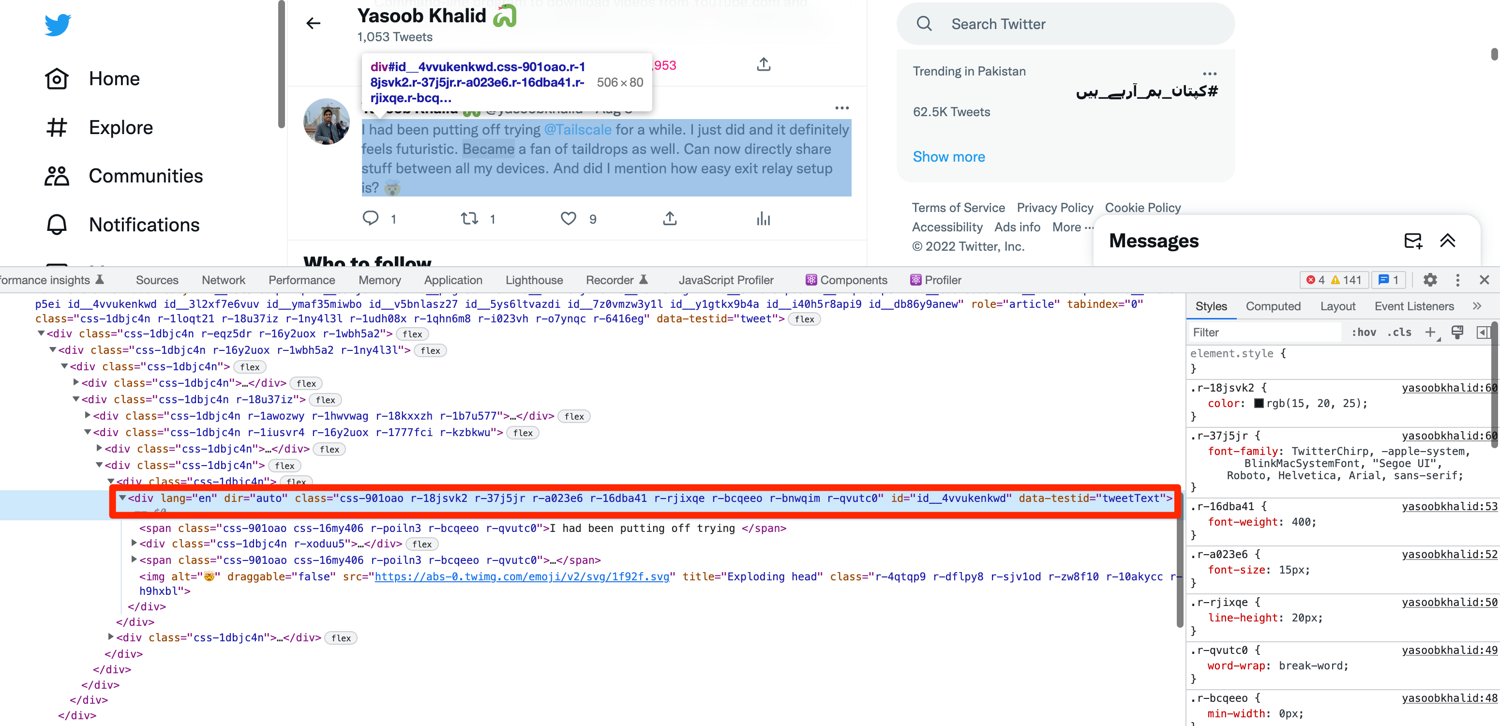
You can extract the tweet text using the following code:
for tweet in tweets:
# ...
tweet_text = tweet.find_element(By.CSS_SELECTOR,'div[data-testid="tweetText"]').text
The likes, retweets, and replies count all follow the same pattern. Right-click on either of these and you will see that there is a data-testid attribute in a parent div for each of them. Here is a screenshot of the DOM structure for the "replies" button:
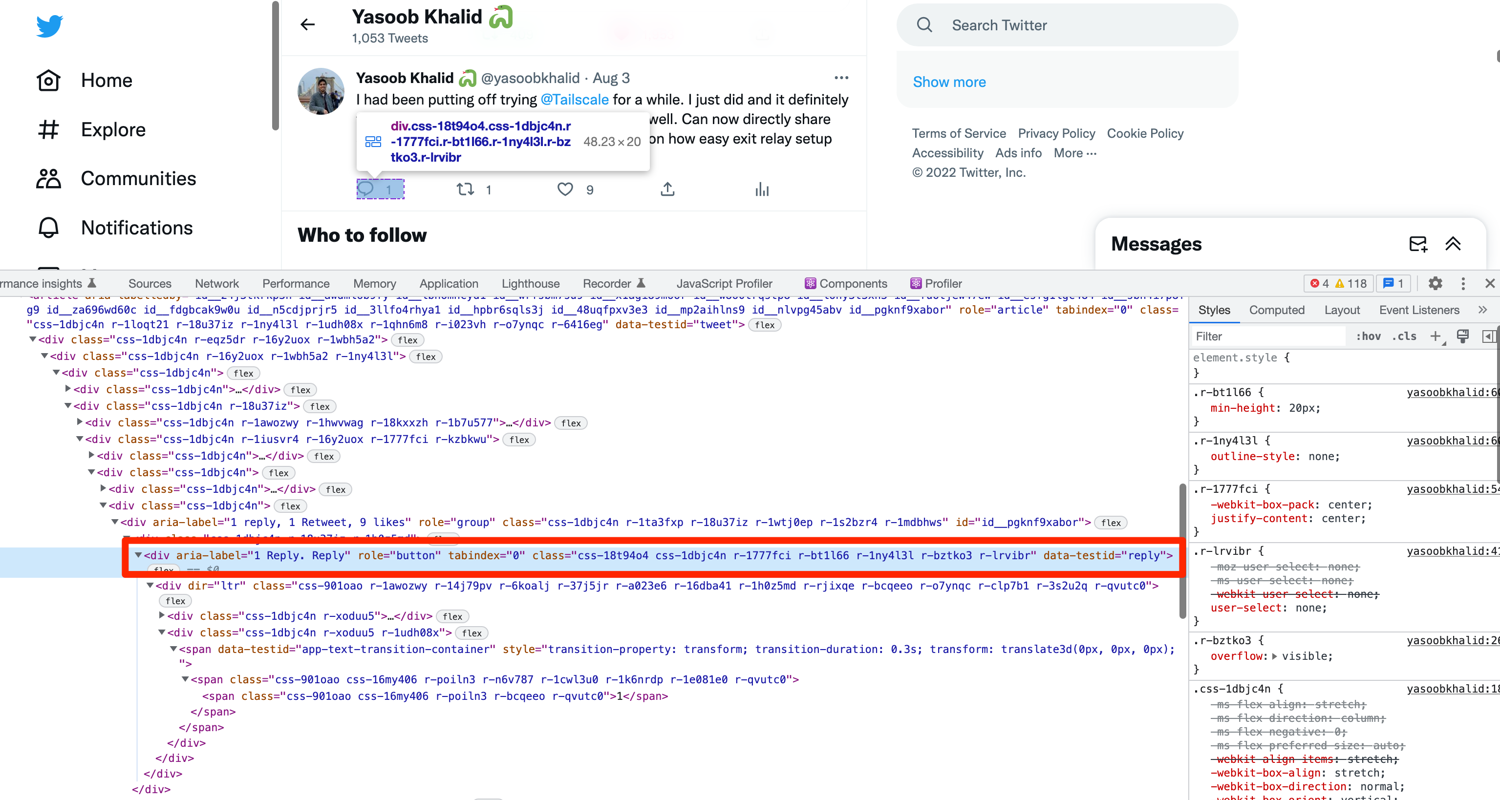
You can extract all of these stats of a tweet using the following code:
for tweet in tweets:
# ...
retweet_count = tweet.find_element(By.CSS_SELECTOR,'div[data-testid="retweet"]').text
like_count = tweet.find_element(By.CSS_SELECTOR,'div[data-testid="like"]').text
reply_count = tweet.find_element(By.CSS_SELECTOR,'div[data-testid="reply"]').text
You can distinguish between an original tweet and a retweet by comparing the tweet author handle with the profile page handle. If they don't match then you are looking at a retweet.
Complete code
The complete code so far looks something like this:
import time
from random import randint
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import WebDriverException
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://twitter.com/yasoobkhalid")
state = ""
while state != "complete":
print("loading not complete")
time.sleep(randint(3, 5))
state = driver.execute_script("return document.readyState")
try:
WebDriverWait(driver, 10).until(EC.presence_of_element_located(
(By.CSS_SELECTOR, '[data-testid="tweet"]')))
except WebDriverException:
print("Tweets did not appear!, Try setting headless=False to see what is happening")
bio = driver.find_element(By.CSS_SELECTOR,'div[data-testid="UserDescription"]').text
name, username = driver.find_element(By.CSS_SELECTOR,'div[data-testid="UserName"]').text.split('\n')
location = driver.find_element(By.CSS_SELECTOR,'span[data-testid="UserLocation"]').text
website = driver.find_element(By.CSS_SELECTOR,'a[data-testid="UserUrl"]').text
join_date = driver.find_element(By.CSS_SELECTOR,'span[data-testid="UserJoinDate"]').text
following = driver.find_element(By.XPATH, "//span[contains(text(), 'Following')]/ancestor::a/span").text
followers = driver.find_element(By.XPATH, "//span[contains(text(), 'Followers')]/ancestor::a/span").text
tweets = driver.find_elements(By.CSS_SELECTOR, '[data-testid="tweet"]')
for tweet in tweets:
tag_text = tweet.find_element(By.CSS_SELECTOR,'div[data-testid="User-Names"]').text
name, handle, _, timestamp = tag_text.split('\n')
tweet_text = tweet.find_element(By.CSS_SELECTOR,'div[data-testid="tweetText"]').text
retweet_count = tweet.find_element(By.CSS_SELECTOR,'div[data-testid="retweet"]').text
like_count = tweet.find_element(By.CSS_SELECTOR,'div[data-testid="like"]').text
reply_count = tweet.find_element(By.CSS_SELECTOR,'div[data-testid="reply"]').text
print(name, handle)
print(tweet_text)
print("--------------")
Feel free to tweak it to suit your needs!
Conclusion
In this tutorial, you learned how to scrape data from a Twitter profile using Selenium. You can continue in the same manner and extract whatever additional data you need. You can also automate page scrolling and login functionality so that you can extract as many tweets as you can.
Or better yet, you can stand on the shoulders of giants and use popular open-source programs that already do all of this for you. One such example is the Twitter scraper selenium project on GitHub that uses Selenium as well and contains a ton of additional features. It automatically extracts images and videos from tweets and also contains code for auto-scrolling to continue extracting additonal tweets.
If you have any further questions related to web scraping, feel free to reach out to us! We would love to help you.

Yasoob is a renowned author, blogger and a tech speaker. He has authored the Intermediate Python and Practical Python Projects books ad writes regularly. He is currently working on Azure at Microsoft.
