Introduction
In this article, you will learn how to scrape product information from Walmart, the world's largest company by revenue (US $570 billion), and the world's largest private employer with 2.2 million employees.
You might want to scrape the product pages on Walmart for monitoring stock levels for a particular item or for monitoring product prices. This can be useful when a product is sold out on the website and you want to make sure you are notified as soon as the stock is replenished.
In this article you will learn:
- How to fetch walmart.com product page using Python requests
- How to extract walmart.com product information using BeautifulSoup
- How to not get while scraping Walmart using ScrapingBee
This is what a typical product page on Walmart looks like. This exact product page can be accessed here.
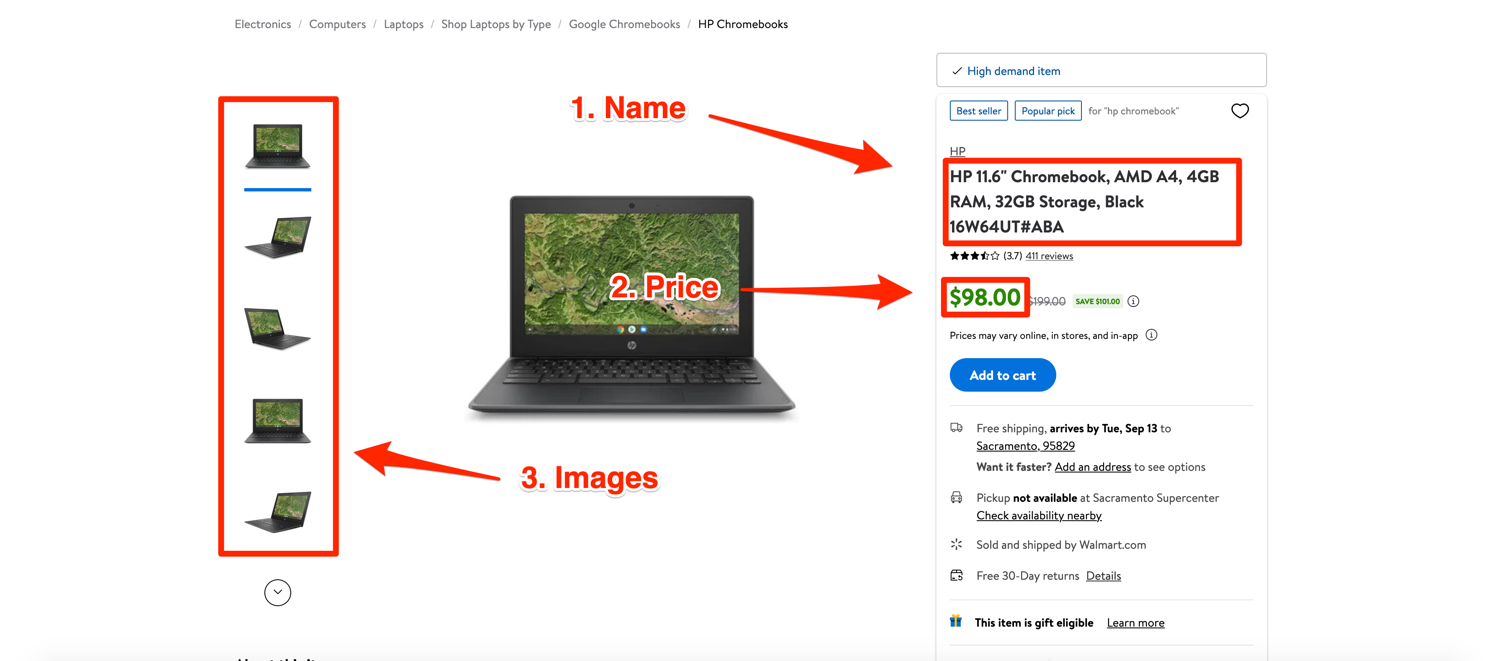
Fetching Walmart.com product page
Let's start by creating a new folder where all of the code will be stored and then create a walmart_scraper.py file in it:
$ mkdir project
$ cd project
$ touch walmart_scraper.py
You will use two libraries during this tutorial: Requests and BeautifulSoup. Requests will allow you to fetch the website via Python and BeautifulSoup will help you in parsing through the HTML of the website and extracting the data you need. To install them, run the following command in the terminal:
$ pip install beautifulsoup4 requests
A typical website is made up of HTML (Hyper Text Markup Language) and that is what the server sends whenever a browser makes a request. The HTML is then parsed by the browser and displayed on the screen. It is possible to make a similar request to fetch the HTML of a web page using requests. To do that, open up the walmart_scraper.py file and write this code:
import requests
url = "https://www.walmart.com/ip/HP-11-6-Chromebook-AMD-A4-4GB-RAM-32GB-Storage-Black-16W64UT-ABA/592161882"
html = requests.get(url)
print(html.text)
If you're an absolute beginner in Python, you can read our full Python web scraping tutorial, it'll teach you everything you need to know to start!
When you try running this code, it should print a bunch of HTML in the console. If you are lucky, you will get the actual product page HTML, but it is possible that you might receive a captcha page in return. You can verify this by checking the first line of the output. If it resembles the following lines then you got served a captcha:
'<html lang="en">\n\n<head>\n <title>Robot or human?</title>\n <meta name="viewport" content="width=device-width">\n
Let's understand what happened here. Walmart knows that the request was made by an automated program and so it blocked it. The simplest way to get around this is to open the link in the browser, solve the captcha, and send some additional information (metadata) to Walmart the next time you try to access it using Python. This additional information is usually a User-Agent string sent as part of request headers. You will try to trick Walmart into believing that the request is coming from a real browser and not an automated program.
You can look at the headers a browser sends with the request by opening up developer tools and then inspecting the network requests. This is what it looks like on Firefox for a request sent to walmart.com:
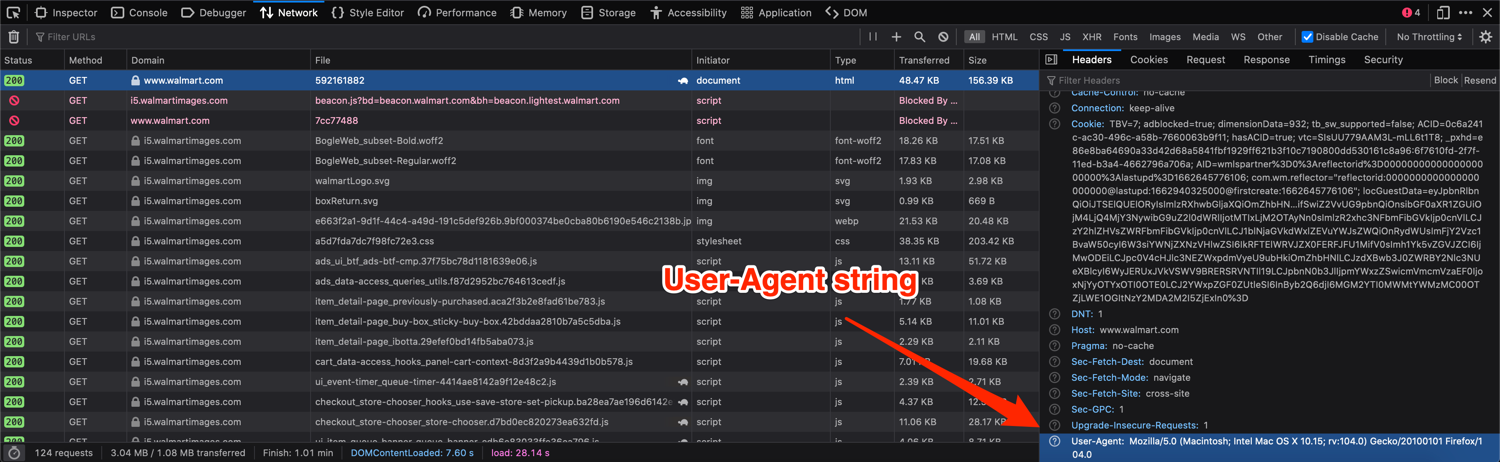
You can send additional headers with a request by passing in a headers dictionary to the requests.get method like so:
import requests
url = "https://www.walmart.com/ip/HP-11-6-Chromebook-AMD-A4-4GB-RAM-32GB-Storage-Black-16W64UT-ABA/592161882"
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:104.0) Gecko/20100101 Firefox/104.0"}
html = requests.get(url, headers=headers)
print(html.text)
If everything goes well, you should see a valid product page HTML displayed on the screen. Now that you have the HTML of the page, it is time to discuss how you can extract the required data from this.
How to extract Walmart.com product information
It is important to finalize what data needs to be extracted. We will focus on extracting the following data about a product in this tutorial:
- Name
- Price
- Images
- Description
The pictures below highlight where this data is found on the product page:
For data extraction, you will be using a library called BeautifulSoup. It is not the only library available for this job but it is easy to use, has a nice API, and handles most data extraction use-cases perfectly.
If you followed the initial library installation instructions, you should have it installed and ready to go. Before you can use BeautifulSoup, you need to look at the HTML that is sent back by Walmart, figure out its structure, and pinpoint where exactly the information you need to extract is located.
There are various workflows people like to follow for this part. The most common one is to go to the browser, use the inspect element tool (available in all major browsers) and figure out the closest tag that can be used to extract the required information. Let's start with the product name and see how this works.
Right-click on the product name and click on inspect element. I am using Firefox in this demonstration:

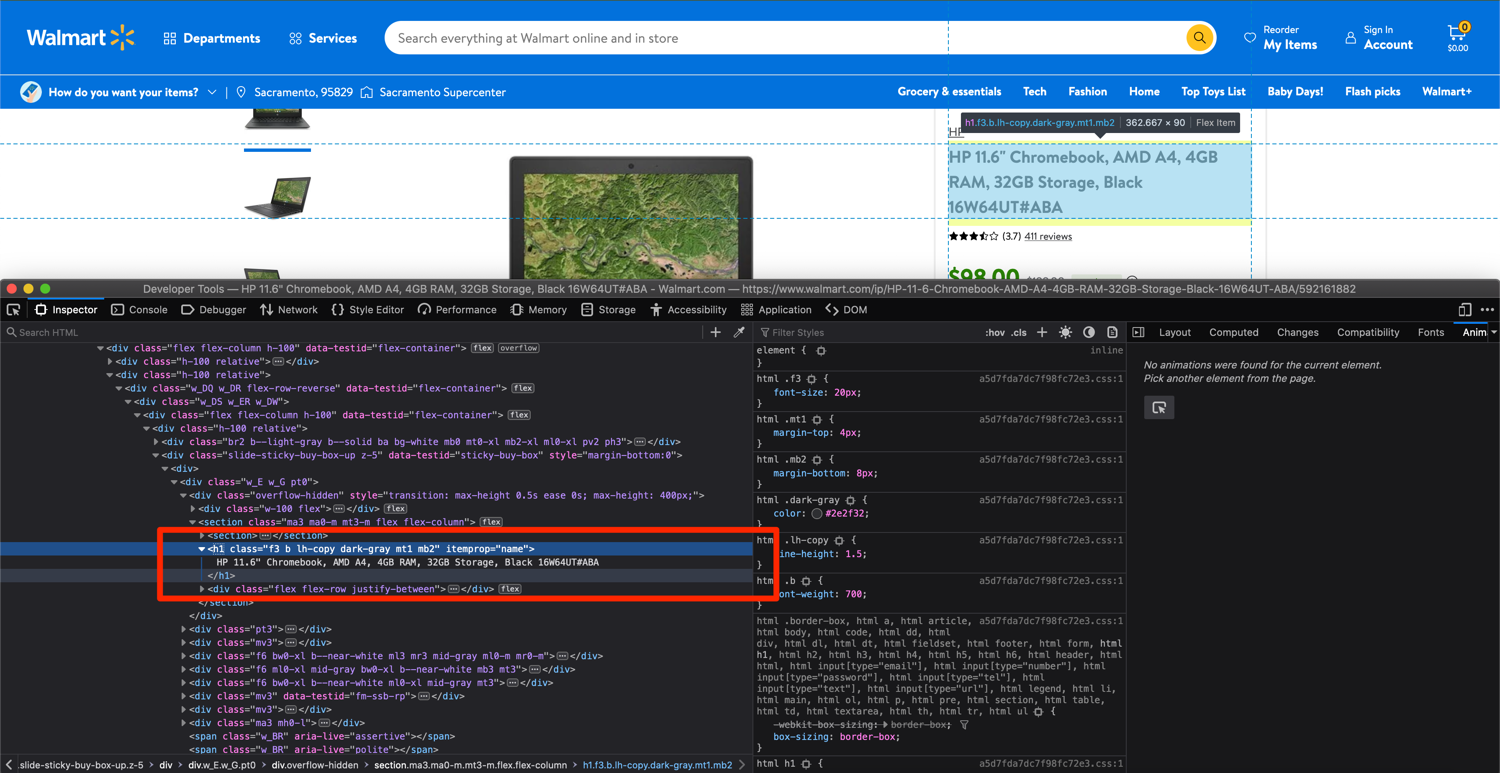
As the image shows, we can extract the product name by searching for an h1 tag that has the itemprop attribute set to "name". Go back to the walmart_scraper.py and write some code to parse the HTML using BeautifulSoup and extract the product name:
import requests
from bs4 import BeautifulSoup
url = "https://www.walmart.com/ip/HP-11-6-Chromebook-AMD-A4-4GB-RAM-32GB-Storage-Black-16W64UT-ABA/592161882"
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:104.0) Gecko/20100101 Firefox/104.0"}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text)
product_name = soup.find('h1', attrs={'itemprop': 'name'}).text
print(product_name)
If you run this script, it should display the product name in the console:
'HP 11.6" Chromebook, AMD A4, 4GB RAM, 32GB Storage, Black 16W64UT#ABA'
The rest of the product information can be extracted in the same way. Let's focus on product thumbnails next. Repeat the same process of inspecting the element and pinpointing the closest tag you can extract:
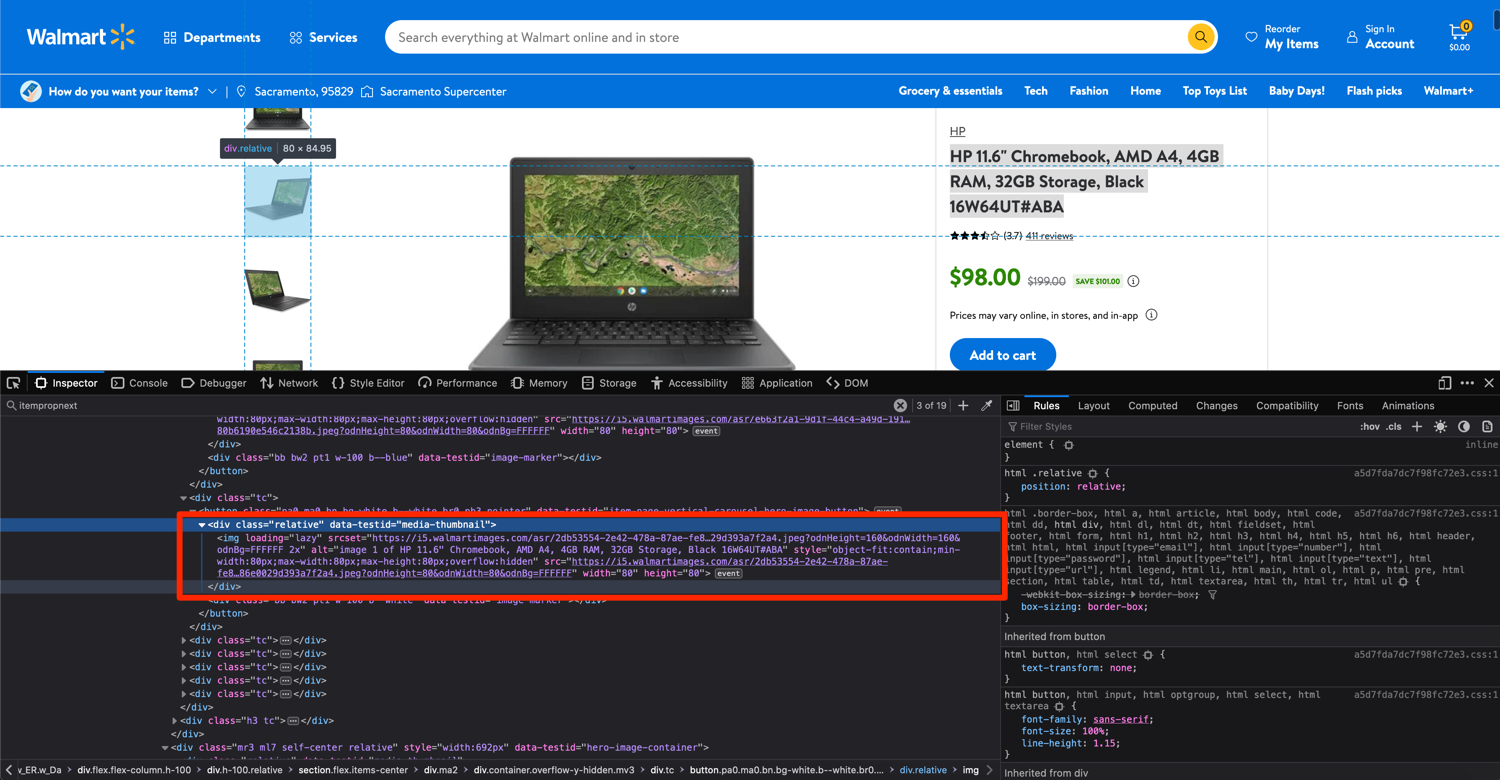
In this case, you can extract the div with the data-testid attribute set to media-thumbnail and then extract the src of the nested img tag. You can use the following code for this purpose:
image_divs = soup.findAll('div', attrs={'data-testid': 'media-thumbnail'})
all_image_urls = []
for div in image_divs:
image = div.find('img', attrs={'loading': 'lazy'})
if image:
image_url = image['src']
all_image_urls.append(image_url)
We are gonna use the same method for the price and extract the span with the itemprop attribute set to price:
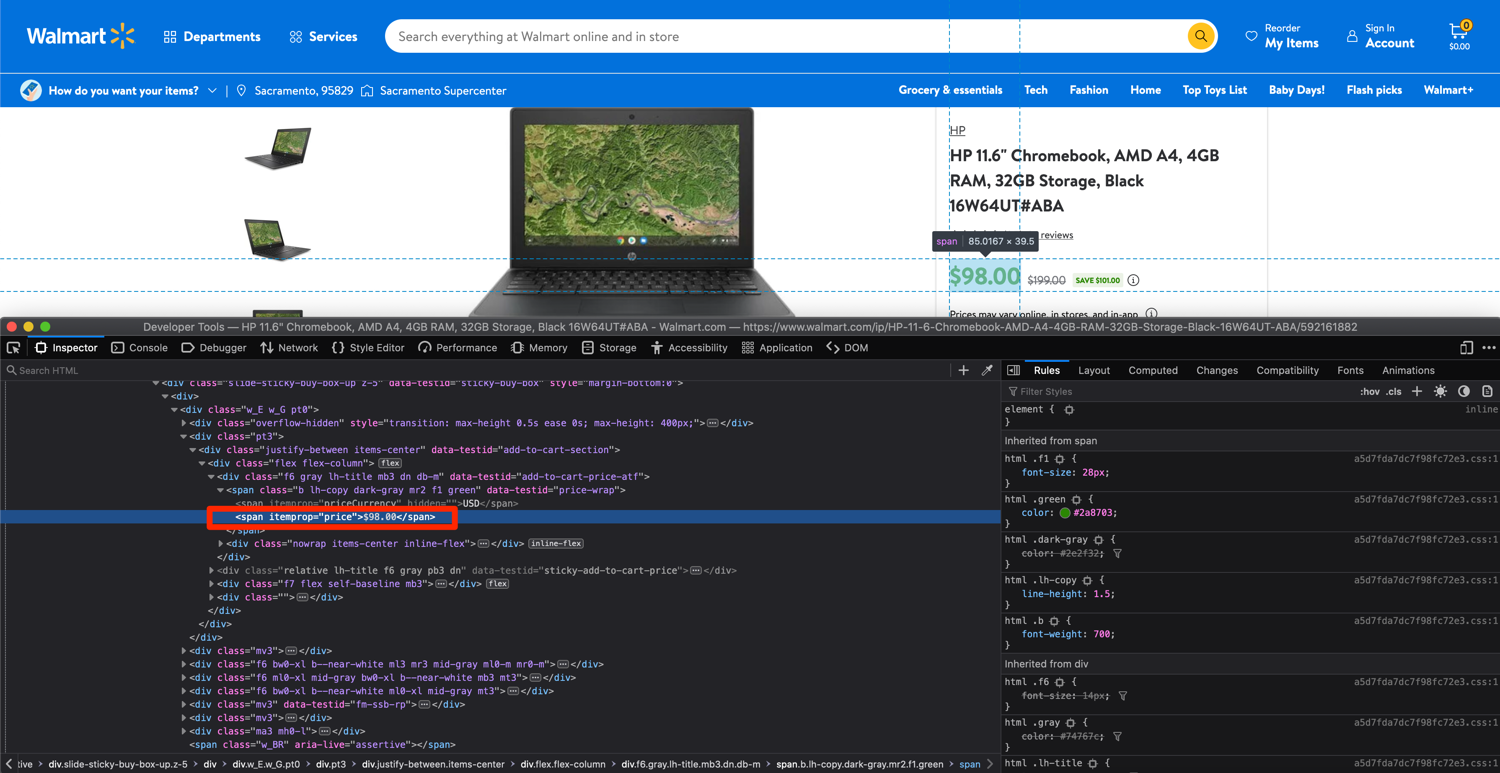
price = soup.find('span', attrs={'itemprop': 'price'}).text
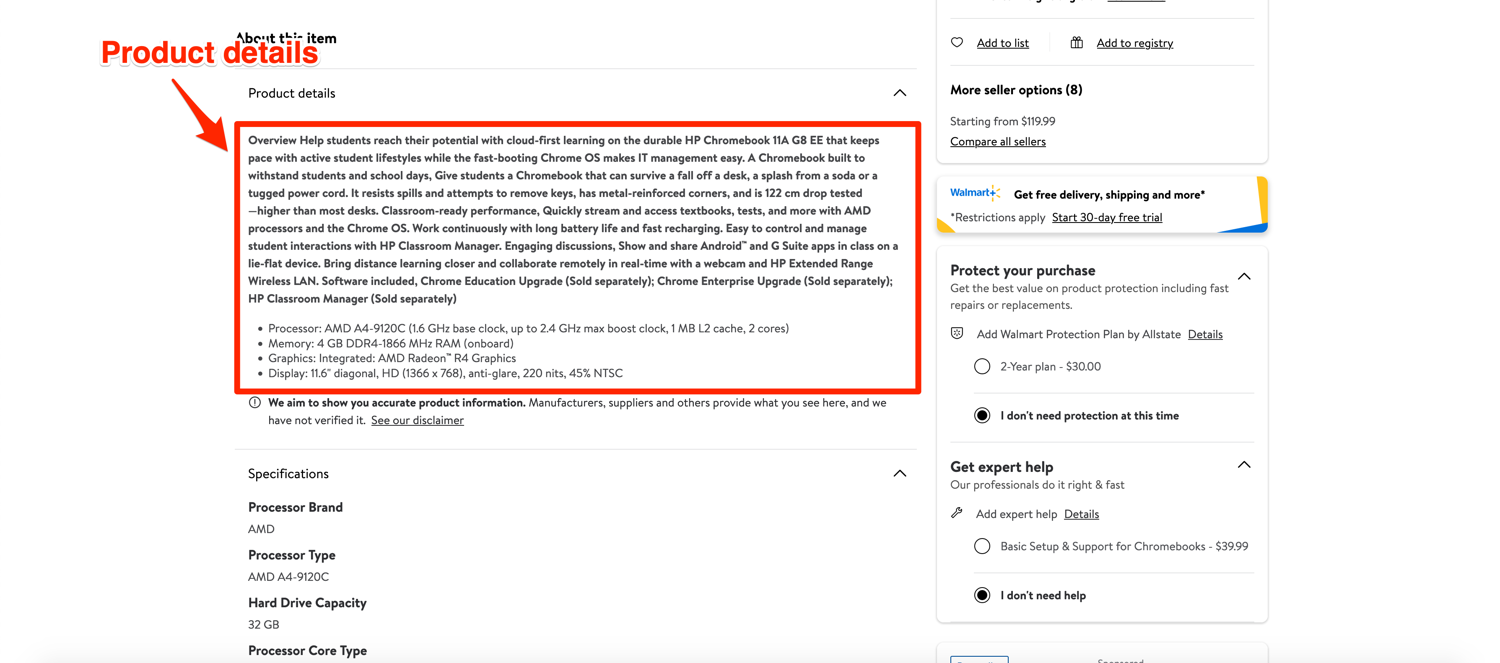
The process for extracting product description is going to be a bit different though. From a cursory look, it looks relatively straightforward. You can extract the data from the divs with the class of dangerous-html. There are only two divs on the page with that class and they contain the information we need.
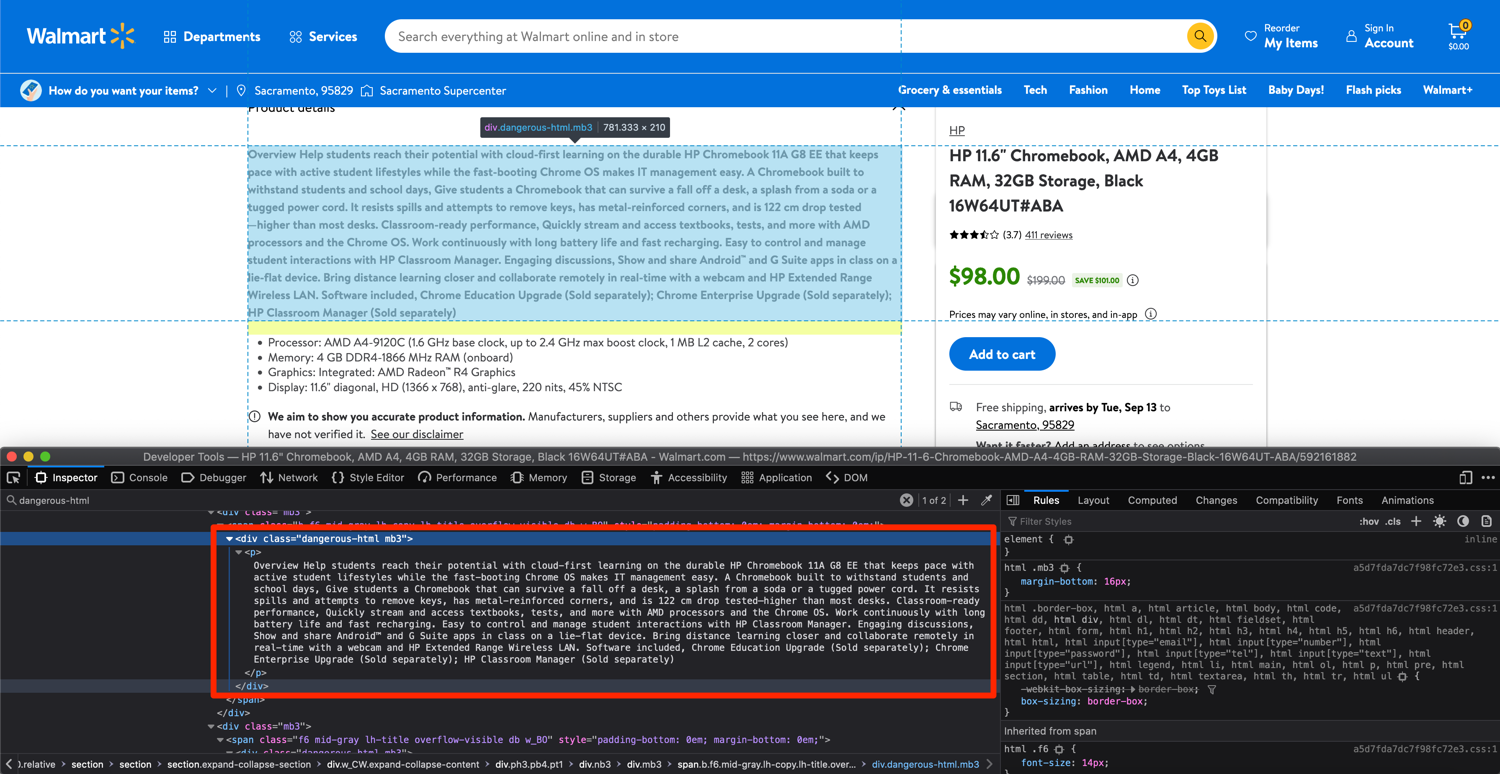
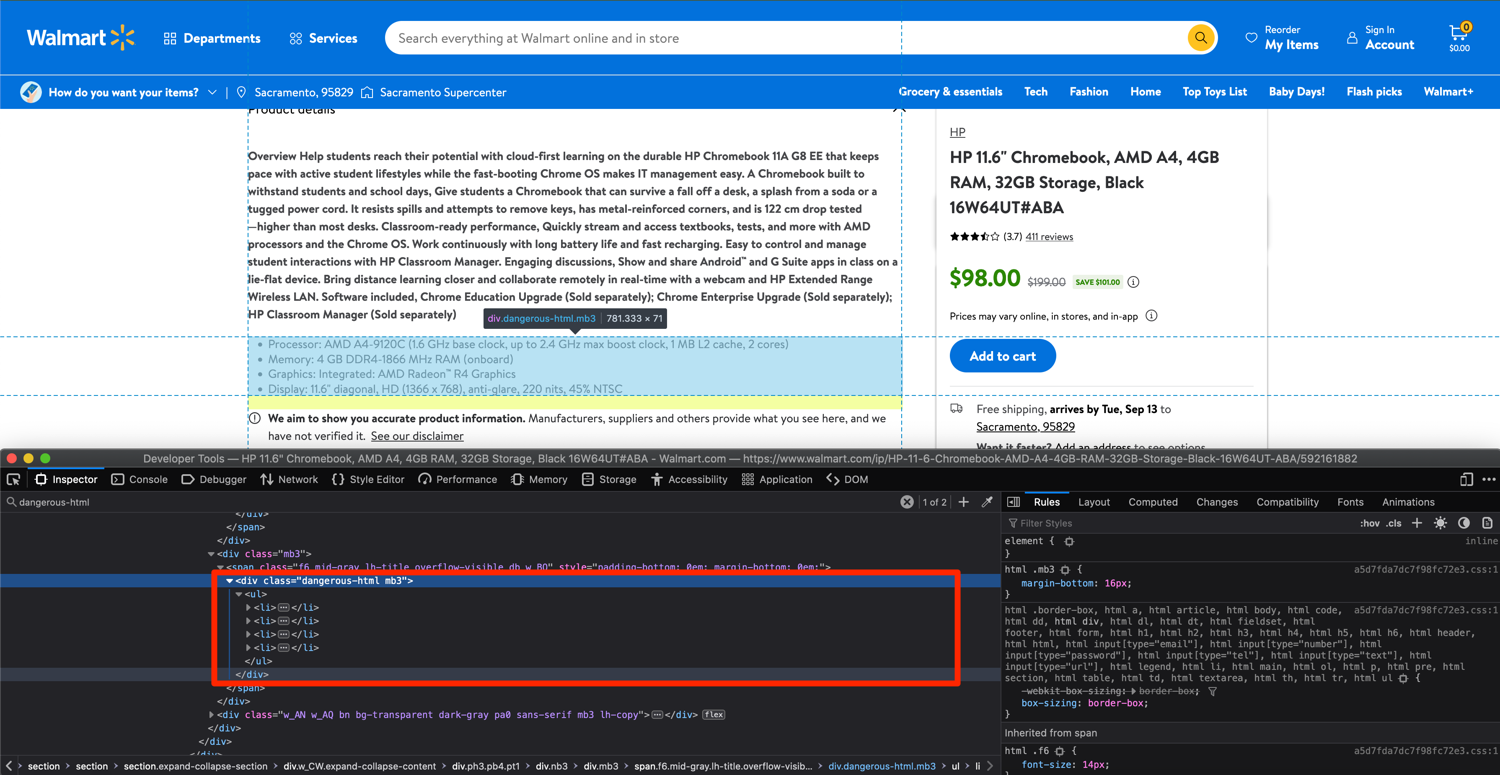
However, once you search the HTML returned by Walmart to your Python script, you will quickly realize that this dangerous-html is not present anywhere in the HTML.
Turns out, extracting all of the data from Walmart is not as simple as what we saw earlier. The HTML you see in the inspector is not the one sent back by Walmart. This is the "processed" version of it. Walmart uses a Javascript framework called NextJS and sends all of the information displayed on the screen as a huge JSON blob.
Luckily, the solution isn't too involved in this case. Open up the console/terminal where you ran the script and search for the product description in the HTML that was sent back by Walmart. You will observe that there is a script tag with the class of __NEXT_DATA__ that contains all of the information we need in a JSON format:
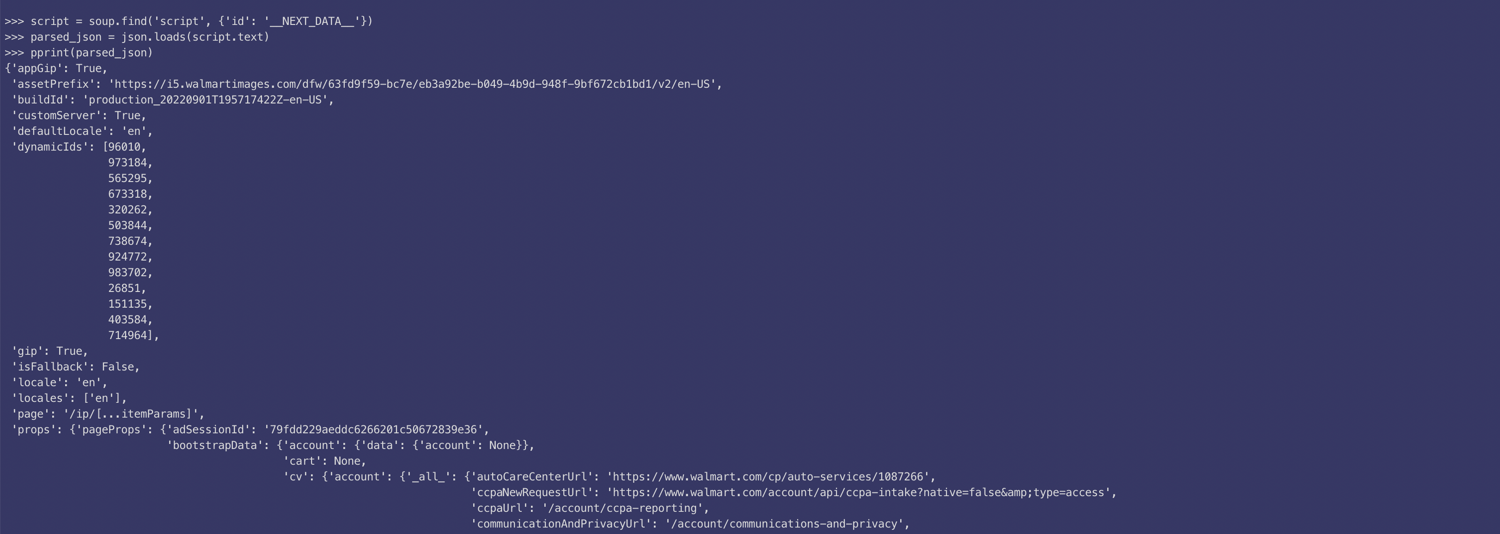
This __NEXT_DATA__ content is used to display all the relevant information on the web page using JavaScript. You can extract and parse this JSON using this code:
import json
script = soup.find('script', {'id': '__NEXT_DATA__'})
parsed_json = json.loads(script.text)
Look through the parsed JSON and figure out the dictionary keys you need to use to extract the required data. This is what works for extracting both sections of the description:
description_1 = parsed_json['props']['pageProps']['initialData']['data']['product']['shortDescription']
description_2 = parsed_json['props']['pageProps']['initialData']['data']['idml']['longDescription']
This will return data in HTML format. You can parse it again using BeautifulSoup and extract the text if required:
description_1_text = BeautifulSoup(description_1).text
description_2_text = BeautifulSoup(description_2).text
You can use the same JSON object to extract all the other information too. All relevant information is stored in this one object. Just for reference, this is what it would look like:
parsed_json['props']['pageProps']['initialData']['data']['product']['name']
parsed_json['props']['pageProps']['initialData']['data']['product']['priceInfo']['currentPrice']['priceString']
parsed_json['props']['pageProps']['initialData']['data']['product']['imageInfo']
At this point, your walmart_scraper.py file should resemble this:
import json
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:104.0) Gecko/20100101 Firefox/104.0"}
url = "https://www.walmart.com/ip/HP-11-6-Chromebook-AMD-A4-4GB-RAM-32GB-Storage-Black-16W64UT-ABA/592161882"
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text)
product_name = soup.find('h1', attrs={'itemprop': 'name'}).text
image_divs = soup.findAll('div', attrs={'data-testid': 'media-thumbnail'})
all_image_urls = []
for div in image_divs:
image = div.find('img', attrs={'loading': 'lazy'})
if image:
image_url = image['src']
all_image_urls.append(image_url)
price = soup.find('span', attrs={'itemprop': 'price'}).text
next_data = soup.find('script', {'id': '__NEXT_DATA__'})
parsed_json = json.loads(next_data.text)
description_1 = parsed_json['props']['pageProps']['initialData']['data']['product']['shortDescription']
description_2 = parsed_json['props']['pageProps']['initialData']['data']['idml']['longDescription']
description_1_text = BeautifulSoup(description_1).text
description_2_text = BeautifulSoup(description_2).text
You can make the required changes and run this script to extract data from whichever product page you want.
If you wish to learn more about BeautifulSoup, checkout our BeautifulSoup tutorial.
Avoid getting blocked with ScrapingBee
There are a few caveats I didn't discuss in detail. The biggest one is that if you run your scraper every so often, Walmart will block it. They have services in place to figure out when a request is made by a script and no simply setting an appropriate User-Agent string is not going to help you bypass that. You will have to use rotating proxies and automated captcha-solving services. This can be too much to handle on your own and luckily there is a service to help with that: ScrapingBee.
You can use ScrapingBee to extract information from whichever product page you want and ScrapingBee will make sure that it uses rotating proxies and solves captchas all on its own. This will let you focus on the business logic (data extraction) and let ScrapingBee deal with all the grunt work.
Let's look at a quick example of how you can use ScrapingBee. First, go to the terminal and install the ScrapingBee Python SDK:
$ pip install scrapingbee
Next, go to the ScrapingBee website and sign up for an account:
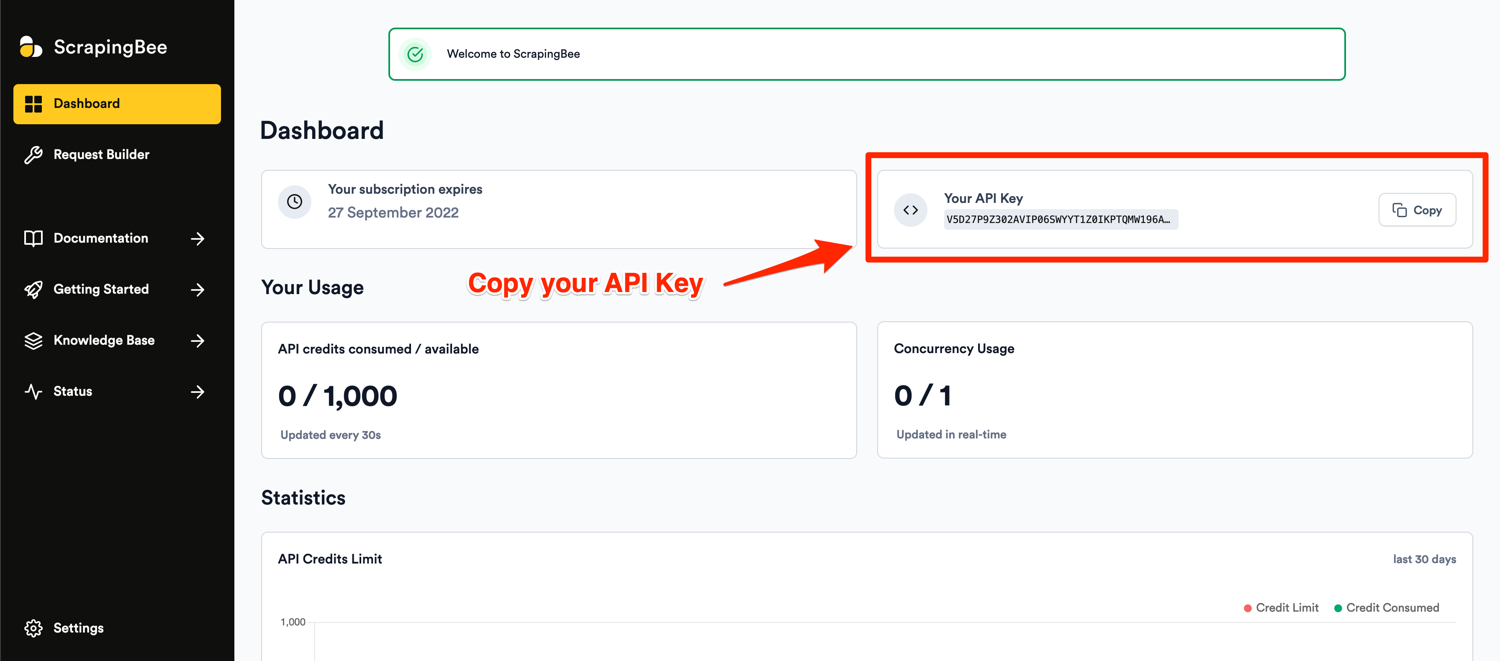
After successful signup, you will be greeted with the default dashboard. Copy your API key from this page and start writing some code in a new Python file:
I will show you the code and then explain what is happening:
import json
from scrapingbee import ScrapingBeeClient
from bs4 import BeautifulSoup
client = ScrapingBeeClient(api_key='YOUR_API_KEY')
url = "https://www.walmart.com/ip/HP-11-6-Chromebook-AMD-A4-4GB-RAM-32GB-Storage-Black-16W64UT-ABA/592161882"
response = client.get(
url,
params={
'extract_rules':{
"name": {
"selector": "h1[itemprop='name']",
"output": "text",
},
"price": {
"selector": "span[itemprop='price']",
"output": "text",
},
"images": {
"selector": "div[data-testid='media-thumbnail'] > img[loading='lazy']",
"output": "@src",
"type": "list",
},
"next_script": {
"selector": "script[id='__NEXT_DATA__']",
"output": "html",
},
}
}
)
if response.ok:
soup = BeautifulSoup(response.json()['next_script'])
parsed_json = json.loads(soup.text)
description_1 = parsed_json['props']['pageProps']['initialData']['data']['product']['shortDescription']
description_2 = parsed_json['props']['pageProps']['initialData']['data']['idml']['longDescription']
description_1_text = BeautifulSoup(description_1).text
description_2_text = BeautifulSoup(description_2).text
Don't forget to replace YOUR_API_KEY with your API key from ScrapingBee. The code is similar to what you wrote using requests and BeautifulSoup. This code, however, makes use of ScrapingBee's powerful extract rules. It allows you to state the tags and selectors that you want to extract the data from and ScrapingBee will return you the scraped data. It is not as useful in this case because you need to do some post-processing of the HTML using BeautifulSoup before you can extract the data. It really shines where all the data is stored in the HTML rather than being stuffed away in a script tag.
💡: By default, urls scraped through ScrapingBee are scraped through a real Chrome instances called an headless browser. In this case, it means that NextJS, the JS framework used by Walmart, can do all its magic before we return you the result.
In the code above, you ask ScrapingBee to give you the information directly that is already in the typical HTML tags and additionally you ask it to return the extracted script tag as well. The rest of the code is the same as before and needs no explanation. ScrapingBee will make sure that you are charged only for a successful response which makes it a really good deal.
Conclusion
I just scratched the surface of what is possible with Python and showed you just a single approach to how you can leverage all the different Python packages to extract data from Walmart.
If your project grows in size and you want to extract a lot more data and want to automate even more stuff, you should definitely look into web scraping tools like Scrapy web scraper. It is a full-fledged Python web scraping framework that features pause/resume, data filtration, proxy rotation, multiple output formats, remote operation, and a whole load of other features.
You can also wire up ScrapingBee with Scrapy to utilize the power of both and make sure your scraping is not affected by websites that continuously throw a captcha.
I hope you learned something new today. If you have any questions please do not hesitate to reach out. We would love to take care of all of your web scraping needs and assist you in whatever way possible!
Before you go, check out these related reads:

Yasoob is a renowned author, blogger and a tech speaker. He has authored the Intermediate Python and Practical Python Projects books ad writes regularly. He is currently working on Azure at Microsoft.
