If you are an internet user, it is safe to assume that you are no stranger to YouTube. It is the hub for videos on internet and even back in 2020, 500 hours of videos were being uploaded to YouTube every minute! This has led to the accumulation of a ton of useful data on the platform. You can extract and make use of some of this data via the official YouTube API but it is rate limited and doesn't contain all the data viewable on the website. In this tutorial, you will learn how you can scrape YouTube data using Selenium. This tutorial will specifically focus on extracting information about videos uploaded by a channel but the techniques are easily transferrable to extracting search results and individual video data.
Setting up the prerequisites
This tutorial will use Python 3.10 but should work with most recent Python versions. Start by creating a new directory for the project and an app.py file for storing all the code:
$ mkdir scrape_youtube
$ cd scrape_youtube
$ touch app.py
You will need to install a few different libraries to follow along:
You can install both of these libraries using this command:
$ pip install selenium webdriver-manager
Selenium will provide you with all the APIs for programmatically accessing a browser and the webdriver-manager will help you in setting up a browser's binary driver easily without the need to manually download and link to it in your code.
Fetching the channel page
Let's try and fetch a channel's uploaded videos page using Selenium to make sure everything is set up correctly. Save the following code in app.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://www.youtube.com/@YasoobKhalid/videos")
Running this code will open up a Chrome window and navigate it to my YouTube channel. If this is the first time you are using webdriver_manager then it might take a few seconds for the Chrome window to open as webdriver_manager has to download the latest chromedriver.
The code is fairly straightforward. It imports webdriver, Service, and ChromeDriverManager and then creates a Chrome driver instance. Generally, you pass in the path to a webdriver executable to webdriver.Chrome but it becomes tedious to keep it updated with the latest Chrome version installed on your system. webdriver_manager makes it super simple by automatically downloading the required chromedriver binary and returning the path to that. This way you don't have to worry about manually downloading the binary with every Chrome update.
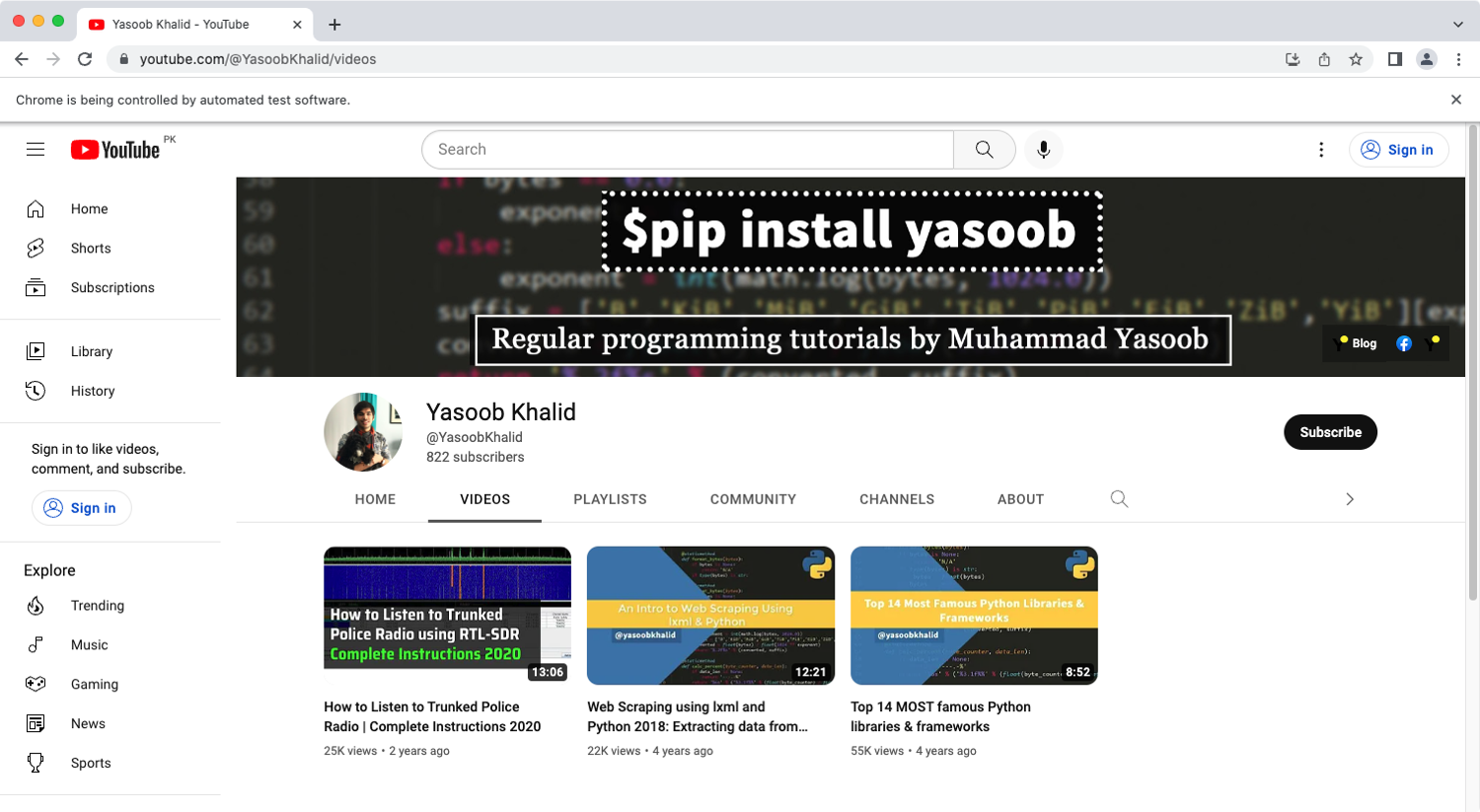
This is what the chrome window might look like on a successful run:
Deciding what to scrape
It is always a good idea to plan what you want to scrape before writing any code. In this tutorial, you will be scraping:
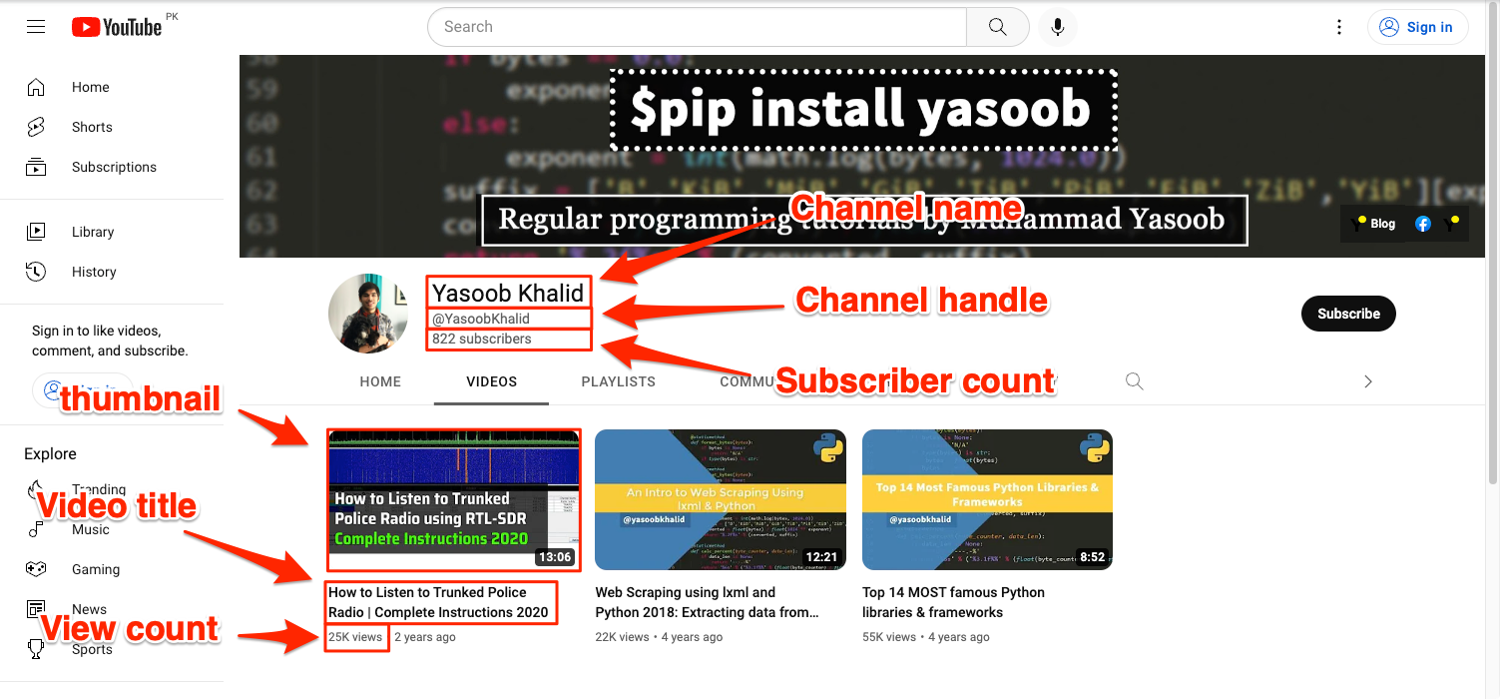
- channel name
- channel handle
- subscriber count
- video titles
- video view counts
- video thumbnails
The screenshot below highlights where all of this information is stored on the page:
You will be using the default methods (find_element + find_elements) that Selenium provides for accessing DOM elements and extracting data from them. Additionally, you will be relying on CSS selectors and XPath for locating the DOM elements. The exact method you use for locating an element will depend on the DOM structure and which method is the most appropriate.
Scraping channel information
Go ahead and explore the HTML structure of the page and try to identify tags that can reliably be targeted to extract the required information.
Extracting channel title
You can start with the channel name. Right-click on the channel name and click on Inspect in the context menu. This will fire up Developer Tools and will show you the HTML structure of the channel name:
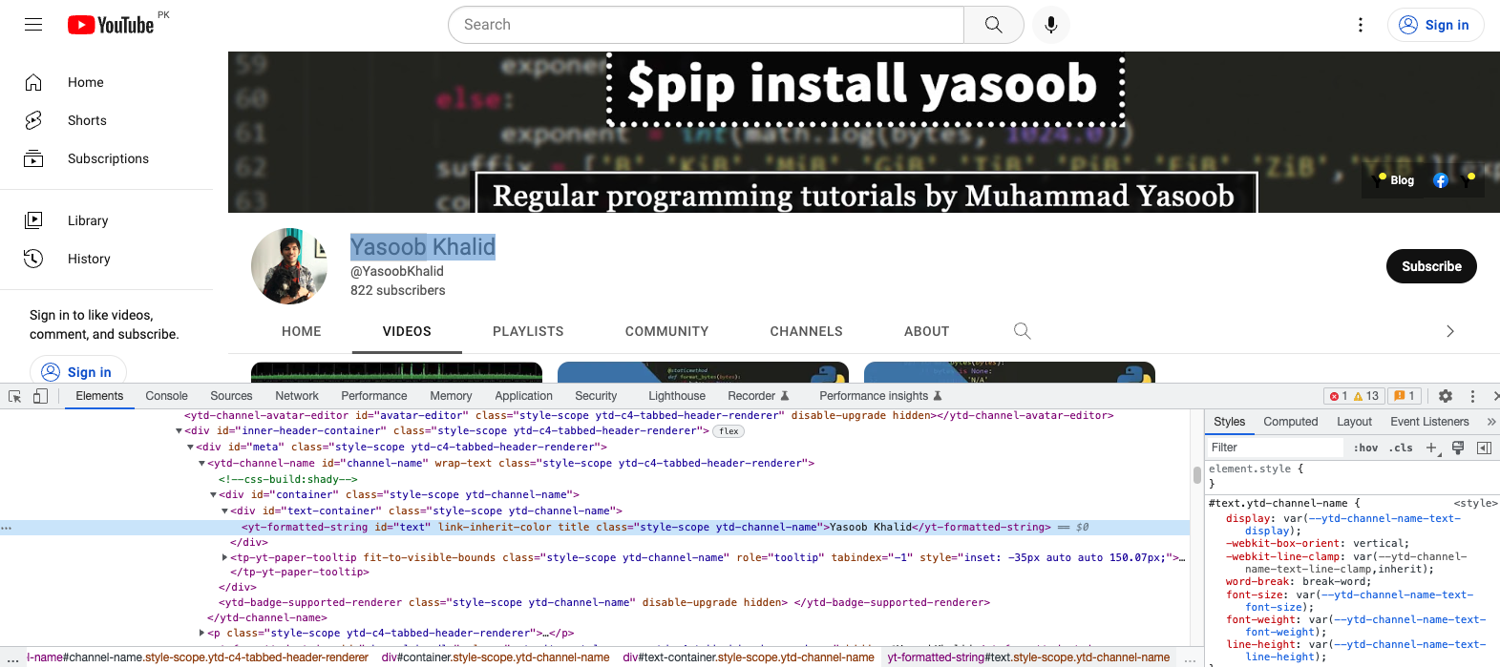
As you can see in the screenshot above, the channel title is encapsulated in a yt-formatted-string tag that has a class of ytd-channel-name. You can use this information to target this element using XPath and extract the text from within it. This is what the code will look like:
from selenium.webdriver.common.by import By
# ...
channel_title = driver.find_element(By.XPATH, '//yt-formatted-string[contains(@class, "ytd-channel-name")]').text
If you have ever worked with Selenium and/or XPath before then the code will look recognizable. It makes use of the find_element method to return the first element on the page that is matched by the XPath expression. The XPath expression itself makes use of some basic XPath features and works like this:
//yt-formatted-stringmatches all tags on the page that are namedyt-formatted-string[contains(@class, "ytd-channel-name")]filters theyt-formatted-stringtags based on the class name and only returns those tags that contain theytd-channel-nameclass
You could have tried to use the following XPath:
//yt-formatted-string[@class="ytd-channel-name"]
However, it would not have worked as it tries to match all yt-formatted-string tags that have the exact class of ytd-channel-name and no additional classes. You might be wondering what happens if we add the additional class to the XPath as well:
//yt-formatted-string[@class="style-scope ytd-channel-name"]
Well, it will work perfectly fine. However, it is better to make your XPaths a bit flexible just in case the class names change in the future, and using one less class name is more flexible than hardcoding two class names.
Extracting channel handle
Next up, explore the HTML structure of the channel handle:
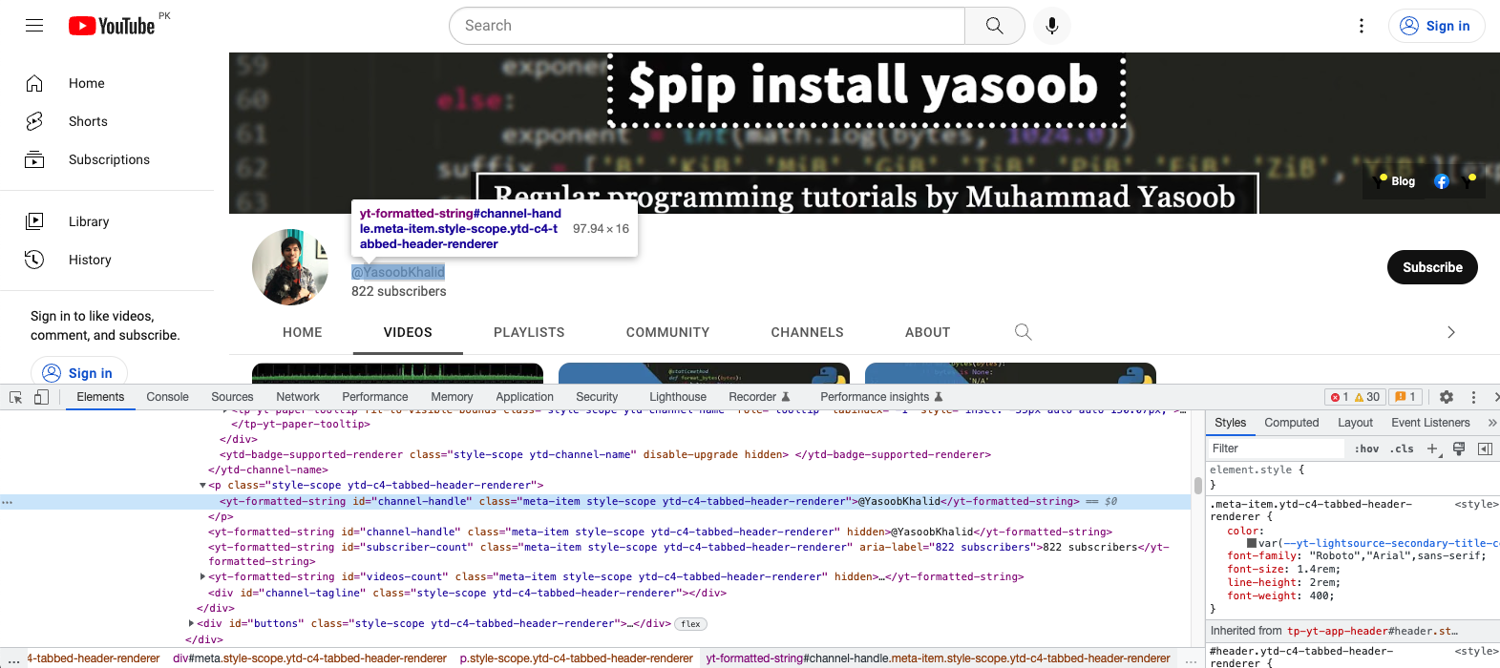
Seems like you can use the id of channel-handle this time and use that to target this element:
handle = driver.find_element(By.XPATH, '//yt-formatted-string[@id="channel-handle"]').text
Even though there is another yt-formatted-string tag with the same id right underneath the one you extracted, you don't need to worry too much about it for two reasons:
- Selenium will always return the first tag that matches the XPath due to the usage of
find_elementmethod as compared tofind_elements - Both tags have the same text so even if they were interchanged we would end up with the same text
Extracting subscriber count
The subscriber count is located right underneath the tag containing the channel handle:
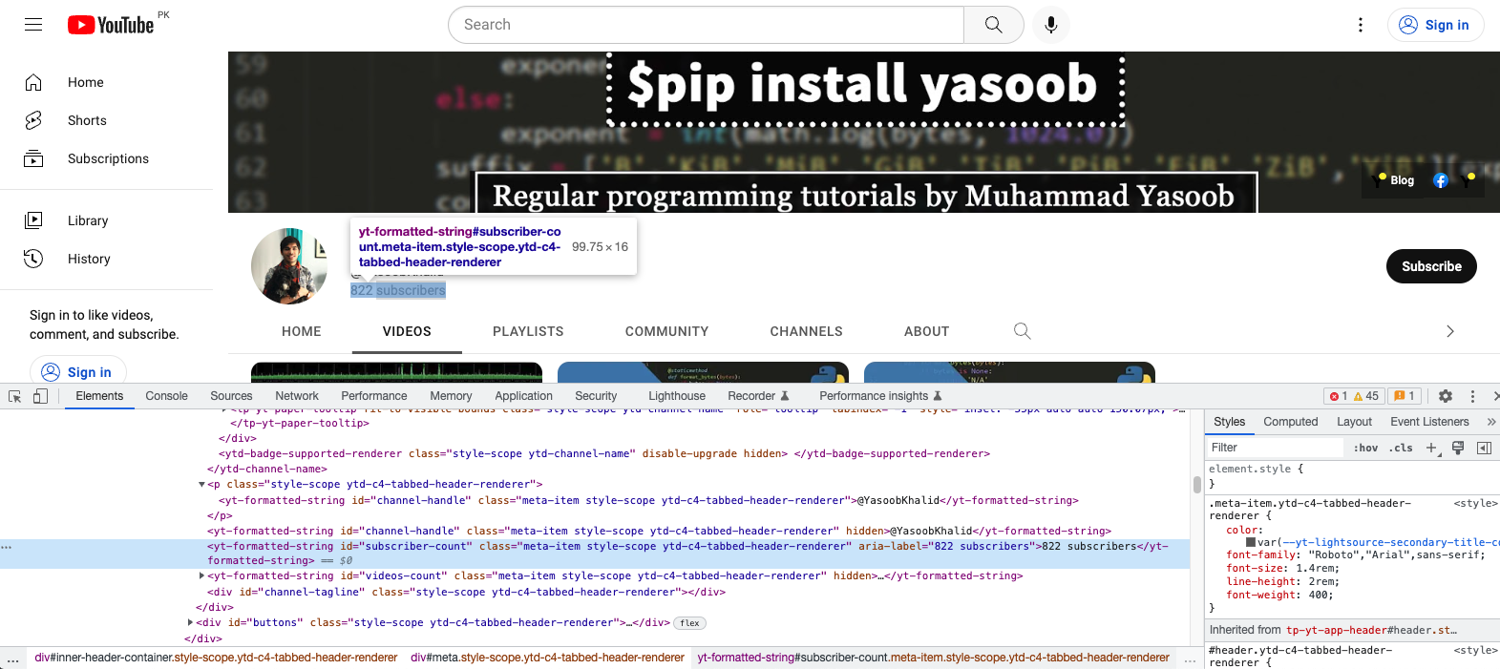
Again, you can rely on the unique id of subscriber-count to target and extract data from this tag:
subscriber_count = driver.find_element(By.XPATH, '//yt-formatted-string[@id="subscriber-count"]').text
Scraping video data
Now that you have all the channel data you wanted to extract, you can focus on the videos. Let's start with the video titles.
Extracting video title
This is what the video title looks like in developer tools:
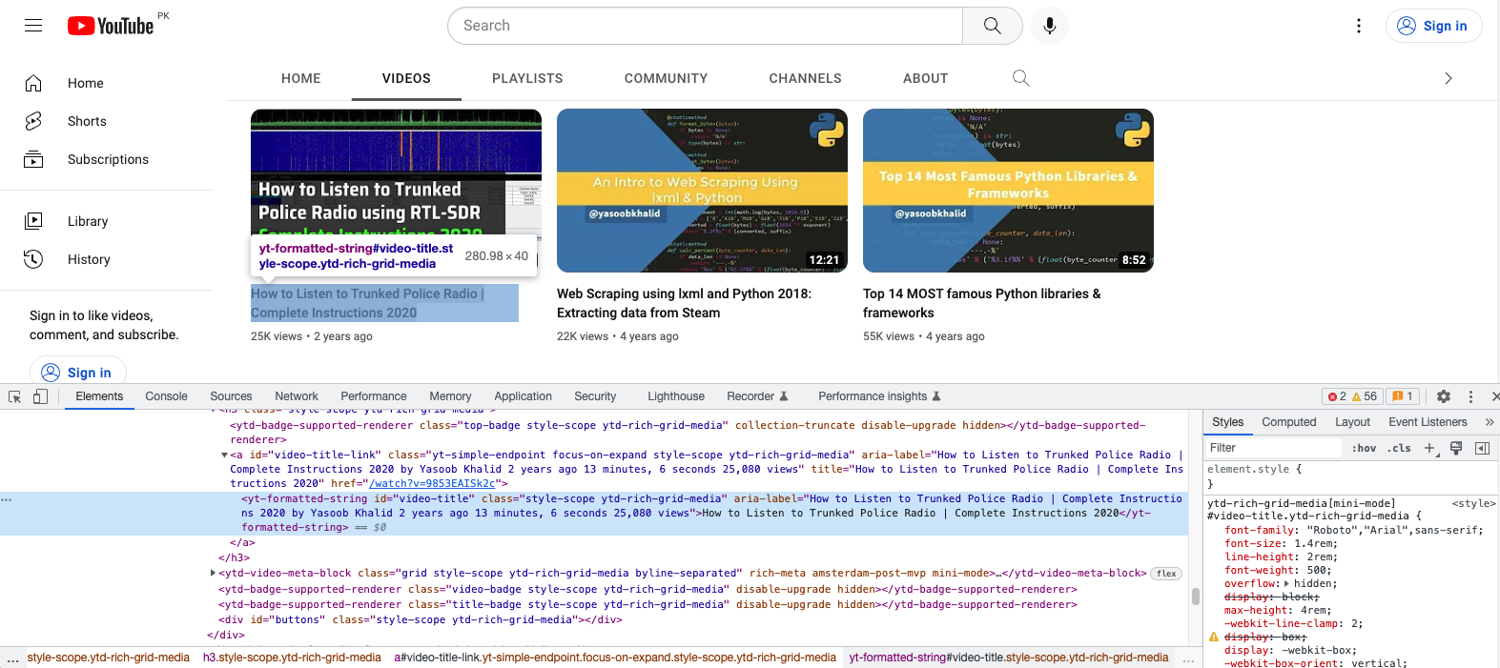
You have two workflow options here. You can either extract each video section like this:
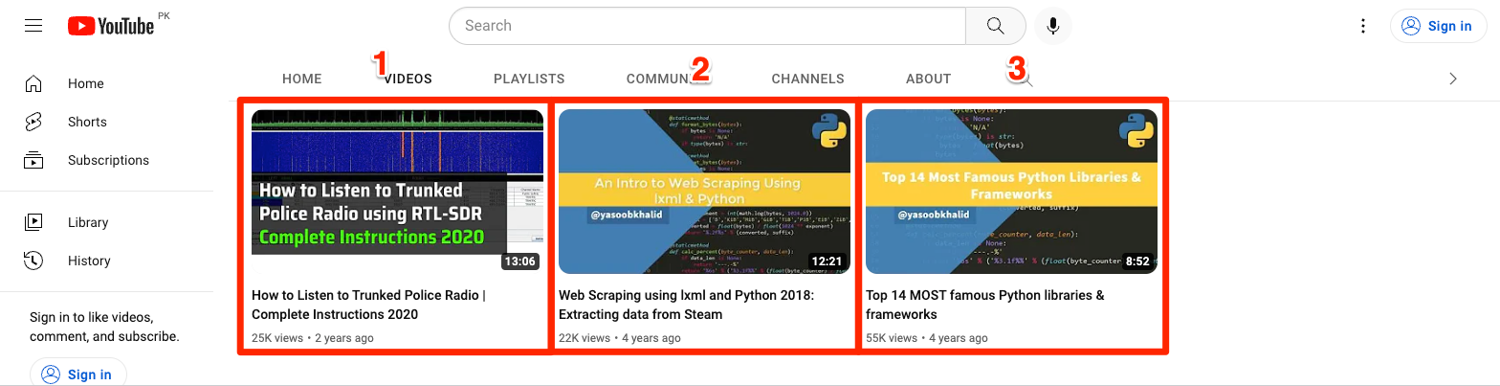
And then extract the individual video data (title, view count, etc.).
Or we can extract all the titles and all the view counts (along with other info) separately and merge them for each video. Generally, the first method is preferred in cases where all sections do not have the same amount of info. This way you will be able to account for missing info for a section (video) much more easily.
However, because YouTube displays the required info for all the videos, you can go with the second workflow option.
According to the developer tools screenshot above, all titles are encapsulated in a yt-formatted-string tag with the id of video-titles. You can use this knowledge to extract all video titles like so:
titles = driver.find_elements(By.ID, "video-title")
This will return a list of WebElement instances. You will have to loop over this list and use the .text property to extract the actual title. This is what that will look like:
titles = [title.text for title in titles]
Extract view count
The view count is located in a span that itself is nested in a div:
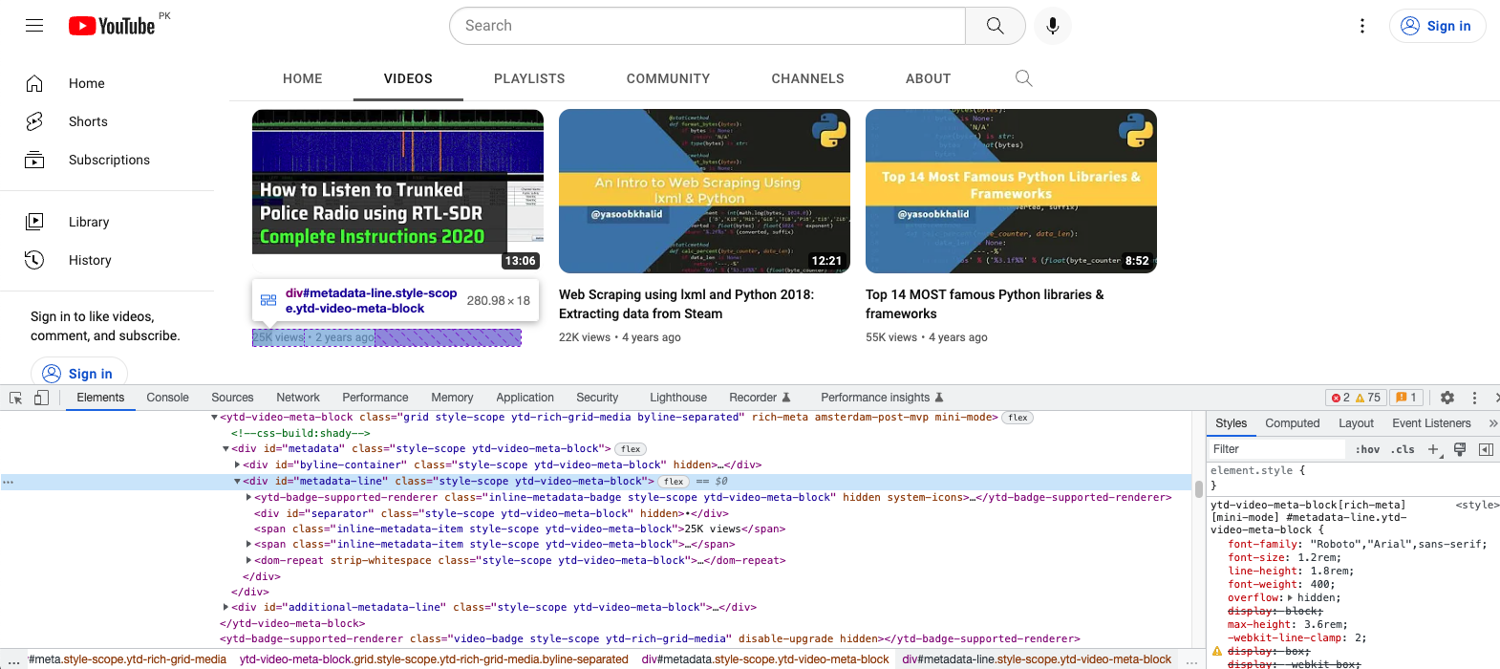
You can extract the spans using this code:
views = driver.find_elements(By.XPATH,'//div[@id="metadata-line"]/span[1]')
This XPath matches the first span inside all divs with the id of metadata-line. The indexing in XPaths begins with 1 so that is why you see 1 instead of 0 as the span index.
We will extract the text from the individual span tags in a bit.
Extract video thumbnail
Sweet! Now you have only one last thing that needs to be extracted: video thumbnails. This is what the DOM structure looks like:
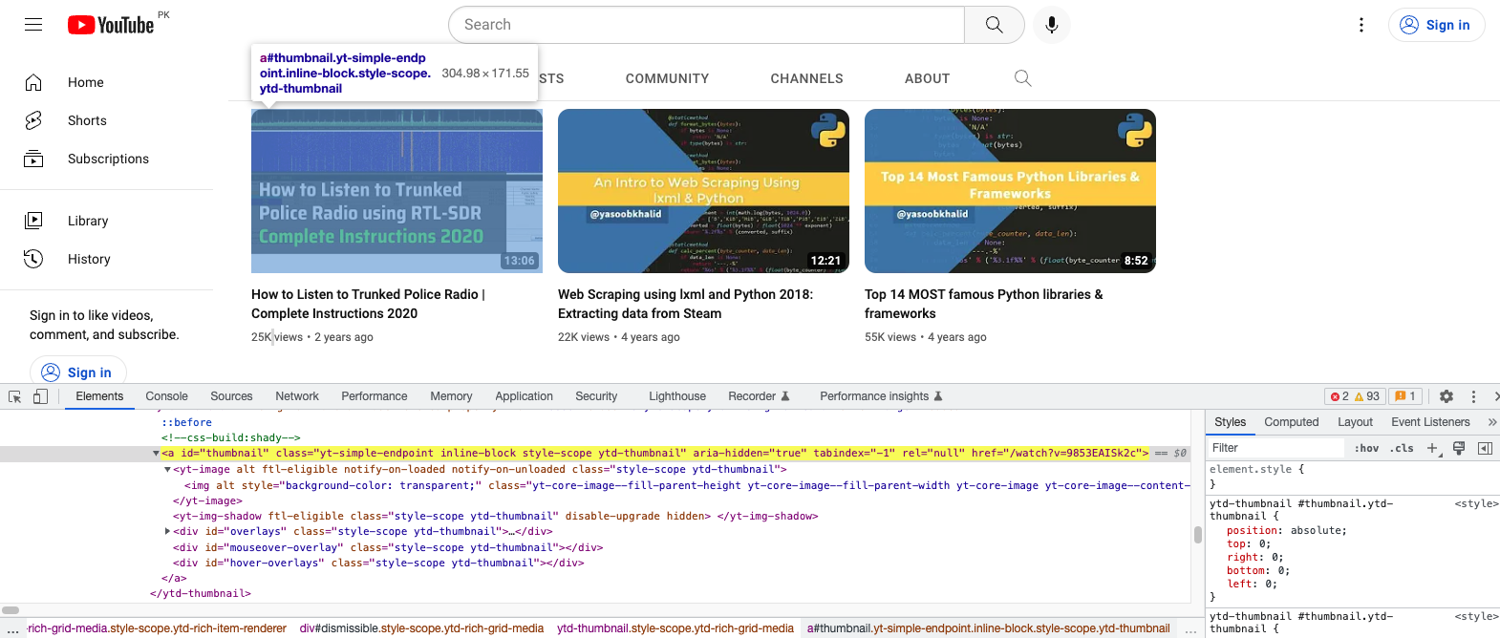
You need to extract the img tag that is nested inside the yt-image tag which itself is nested within an anchor tag with the id of thumbnail. This is what the extraction code will look like:
thumbnails = driver.find_elements(By.XPATH, '//a[@id="thumbnail"]/yt-image/img')
Merging the extracted video information
At this point, you have three separate lists containing the video information. You can merge the info about individual videos and create a new list of dictionaries:
from pprint import pprint
# ...
videos = []
for title, view, thumb in zip(titles, views, thumbnails):
video_dict = {
'title': title.text,
'views': view.text,
'thumbnail': thumb.get_attribute('src')
}
videos.append(video_dict)
pprint(videos)
If you save this code and run it, it will produce an output similar to this:
[
{
"thumbnail": "https://i.ytimg.com/vi/9853EAISk2c/hqdefault.jpg?sqp=-oaymwEcCNACELwBSFXyq4qpAw4IARUAAIhCGAFwAcABBg==&rs=AOn4CLDaPCvkUgLmsYZ3V7jETCqMu4DEhw",
"title": "How to Listen to Trunked Police Radio | Complete Instructions 2020",
"views": "25K views",
},
{
"thumbnail": "https://i.ytimg.com/vi/5N066ISH8og/hqdefault.jpg?sqp=-oaymwEcCNACELwBSFXyq4qpAw4IARUAAIhCGAFwAcABBg==&rs=AOn4CLBiWiKDJq8dC1UDhU9-FuUizexzRg",
"title": "Web Scraping using lxml and Python 2018: Extracting data from "
"Steam",
"views": "22K views",
},
{
"thumbnail": "https://i.ytimg.com/vi/MqeO9lQemmQ/hqdefault.jpg?sqp=-oaymwEcCNACELwBSFXyq4qpAw4IARUAAIhCGAFwAcABBg==&rs=AOn4CLAYTPts5BIKZ4olyt8o1miJJrYcmQ",
"title": "Top 14 MOST famous Python libraries & frameworks",
"views": "55K views",
},
]
While you are at it, go ahead and add the video links to the dictionaries as well. The code for that would resemble this:
links = driver.find_elements(By.ID, "video-title-link")
videos = []
for title, view, thumb, link in zip(titles, views, thumbnails, links):
video_dict = {
'title': title.text,
'views': view.text,
'thumbnail': thumb.get_attribute('src'),
'link': link.get_attribute('href')
}
videos.append(video_dict)
And now your output should include the link as well:
[
{
"link": "https://www.youtube.com/watch?v=9853EAISk2c",
"thumbnail": "https://i.ytimg.com/vi/9853EAISk2c/hqdefault.jpg?sqp=-oaymwEcCNACELwBSFXyq4qpAw4IARUAAIhCGAFwAcABBg==&rs=AOn4CLDaPCvkUgLmsYZ3V7jETCqMu4DEhw",
"title": "How to Listen to Trunked Police Radio | Complete Instructions 2020",
"views": "25K views",
},
{
"link": "https://www.youtube.com/watch?v=5N066ISH8og",
"thumbnail": "https://i.ytimg.com/vi/MqeO9lQemmQ/hqdefault.jpg?sqp=-oaymwEcCNACELwBSFXyq4qpAw4IARUAAIhCGAFwAcABBg==&rs=AOn4CLAYTPts5BIKZ4olyt8o1miJJrYcmQ",
"title": "Top 14 MOST famous Python libraries & frameworks",
"views": "55K views",
},
{
"link": "https://www.youtube.com/watch?v=MqeO9lQemmQ",
"thumbnail": "https://i.ytimg.com/vi/5N066ISH8og/hqdefault.jpg?sqp=-oaymwEcCNACELwBSFXyq4qpAw4IARUAAIhCGAFwAcABBg==&rs=AOn4CLBiWiKDJq8dC1UDhU9-FuUizexzRg",
"title": "Web Scraping using lxml and Python 2018: Extracting data from "
"Steam",
"views": "22K views",
},
]
Perfect! You have extracted all the data you wanted! But wait! There is one slight issue.
Loading all videos on the channel page
By default, YouTube only shows a few videos on the channel page. My channel only has 3 videos so far so it hasn't been an issue. However, if the channel you are scraping has a ton of videos, you will have to scroll to the bottom of the page to load older videos. There might be 1000 videos so you will have to scroll quite a few times to load them all.
Luckily, there is a way for you to automate this using Selenium. The basic idea is that you will get the current height of the document (page), tell Selenium to scroll to the bottom of the page, wait for a few seconds, and then calculate the height of the document yet again. You will continue doing so until the new height is the same as the old height. This way you can be sure that there are no more videos that need to be loaded. Once all the videos are visible on the page, you can go ahead and scrape all of them in one go.
The code for this logic will resemble this:
import time
WAIT_IN_SECONDS = 5
last_height = driver.execute_script("return document.documentElement.scrollHeight")
while True:
# Scroll to the bottom of the page
driver.execute_script("window.scrollTo(0, arguments[0]);", last_height)
# Wait for new videos to show up
time.sleep(WAIT_IN_SECONDS)
# Calculate the new document height and compare it with the last height
new_height = driver.execute_script("return document.documentElement.scrollHeight")
if new_height == last_height:
break
last_height = new_height
# All videos loaded
# Go ahead with scraping
The code exactly follows the logic explained earlier. It executes some javascript statements to get the current document height, scroll to the bottom of the page, wait for a bit and compare the new height with the old height. If the new height and old heights are same, it breaks out of the loop.
There is a better way to do this by using selenium-wire and making sure the AJAX call has returned. We follow that workflow in some of our other tutorials. However, for YouTube, this code should work just fine.
Complete code
The complete code for this tutorial looks like this:
import time
import pprint
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://www.youtube.com/@YasoobKhalid/videos")
channel_title = driver.find_element(By.XPATH, '//yt-formatted-string[contains(@class, "ytd-channel-name")]').text
handle = driver.find_element(By.XPATH, '//yt-formatted-string[@id="channel-handle"]').text
subscriber_count = driver.find_element(By.XPATH, '//yt-formatted-string[@id="subscriber-count"]').text
WAIT_IN_SECONDS = 5
last_height = driver.execute_script("return document.documentElement.scrollHeight")
while True:
# Scroll to the bottom of page
driver.execute_script("window.scrollTo(0, arguments[0]);", last_height)
# Wait for new videos to show up
time.sleep(WAIT_IN_SECONDS)
# Calculate new document height and compare it with last height
new_height = driver.execute_script("return document.documentElement.scrollHeight")
if new_height == last_height:
break
last_height = new_height
thumbnails = driver.find_elements(By.XPATH, '//a[@id="thumbnail"]/yt-image/img')
views = driver.find_elements(By.XPATH,'//div[@id="metadata-line"]/span[1]')
titles = driver.find_elements(By.ID, "video-title")
links = driver.find_elements(By.ID, "video-title-link")
videos = []
for title, view, thumb, link in zip(titles, views, thumbnails, links):
video_dict = {
'title': title.text,
'views': view.text,
'thumbnail': thumb.get_attribute('src'),
'link': link.get_attribute('href')
}
videos.append(video_dict)
pprint(videos)
Avoid getting blocked by using ScrapingBee
There are a few caveats I didn't discuss in detail. The biggest one is that if you run your scraper every so often, YouTube will block it. They have services in place to figure out when a request is made by a script and no simply setting an appropriate User-Agent string is not going to help you bypass that. You will have to use rotating proxies and automated captcha-solving services. This can be too much to handle on your own and luckily there is a service to help with that: ScrapingBee.
You can use ScrapingBee to extract information from whichever channel page you want and ScrapingBee will make sure that it uses rotating proxies and solves captchas all on its own. This will let you focus on the business logic (data extraction) and let ScrapingBee deal with all the grunt work.
Let's look at a quick example of how you can use ScrapingBee. First, go to the terminal and install the ScrapingBee Python SDK:
$ pip install scrapingbee
Next, go to the ScrapingBee website and sign up for an account:
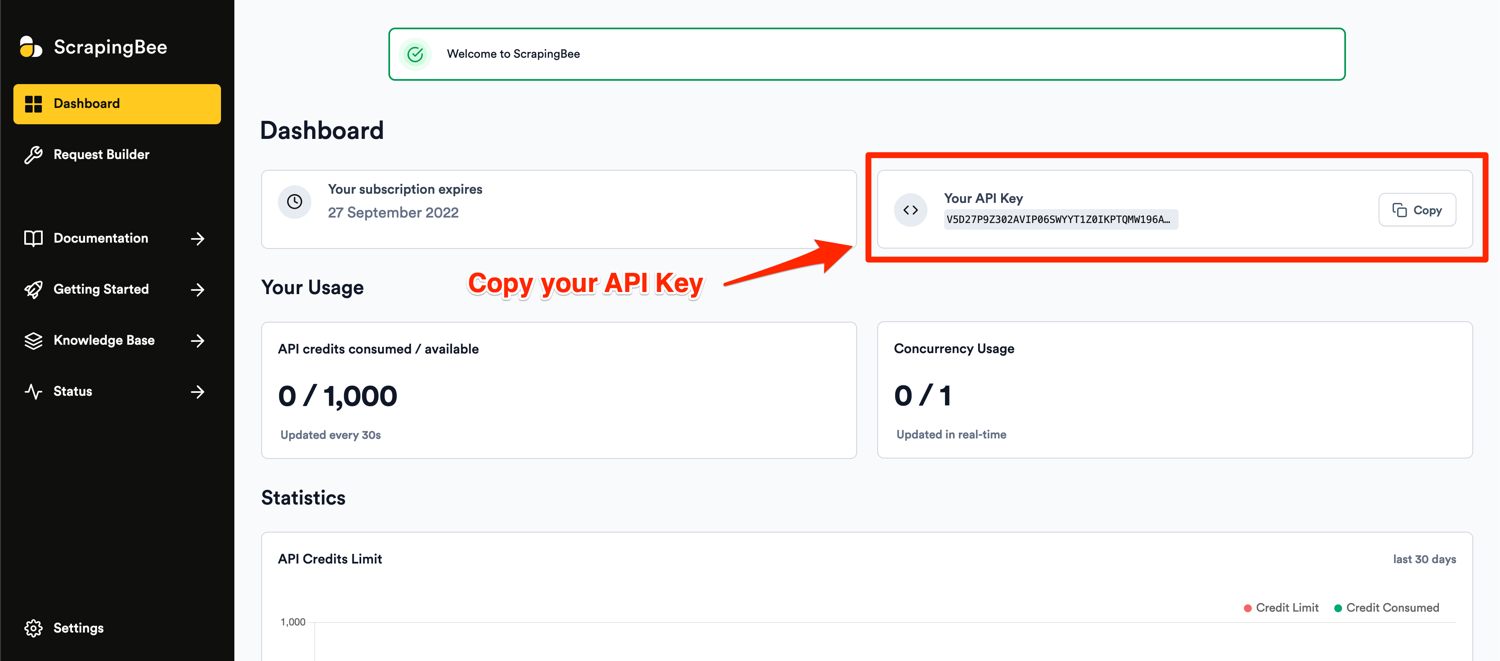
After successful signup, you will be greeted with the default dashboard. Copy your API key from this page and edit the code in your app.py file.
I will show you the code and then explain what is happening:
from pprint import pprint
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(api_key='API_KEY')
url = "https://www.youtube.com/@YasoobKhalid/videos"
js_scenario = {
"instructions": [
{"click": "form > div > div > button"},
{"wait": 1500},
{"scroll_y": 1080}
]
}
response = client.get(
url,
params={
"block_resources": "false",
"premium_proxy": "true",
'country_code':'us',
"js_scenario": js_scenario,
'extract_rules': {
"channel_title": {
"selector": "yt-formatted-string[class='style-scope ytd-channel-name']",
"output": "text",
},
"handle": {
"selector": "yt-formatted-string[id='channel-handle']",
"output": "text",
},
"subscriber_count": {
"selector": "yt-formatted-string[id='subscriber-count']",
"output": "text",
},
"thumbnails": {
"selector": "a[id='thumbnail'] > yt-image > img",
"type": "list",
"output": "@src",
},
"views": {
"selector": "div[id='metadata-line'] > span:nth-of-type(1)",
"type": "list",
"output": "text",
},
"titles": {
"selector": "#video-title",
"type": "list",
"output": "text",
},
"links": {
"selector": "#video-title-link",
"type": "list",
"output": "@href",
},
}
}
)
if response.ok:
scraped_data = response.json()
videos = []
for title, view, thumb, link in zip(scraped_data["titles"], scraped_data["views"], scraped_data["thumbnails"], scraped_data["links"]):
video_dict = {
'title': title,
'views': view,
'thumbnail': thumb,
'link': link
}
videos.append(video_dict)
pprint(videos)
Note: Make sure to replace API_KEY with your API key.
The code is somewhat similar to what you wrote using selenium and XPath. This code, however, makes use of ScrapingBee's powerful extract rules. It allows you to state the tags and selectors that you want to extract the data from and ScrapingBee will return you the scraped data.
The code contains a js_scenario dictionary that tells ScrapingBee what actions it needs to take before extracting the data. The first step of clicking a button might seem a bit out of place but Google/YouTube oftentimes returns a cookies consent form on first run that needs to be accepted. This is what it looks like:
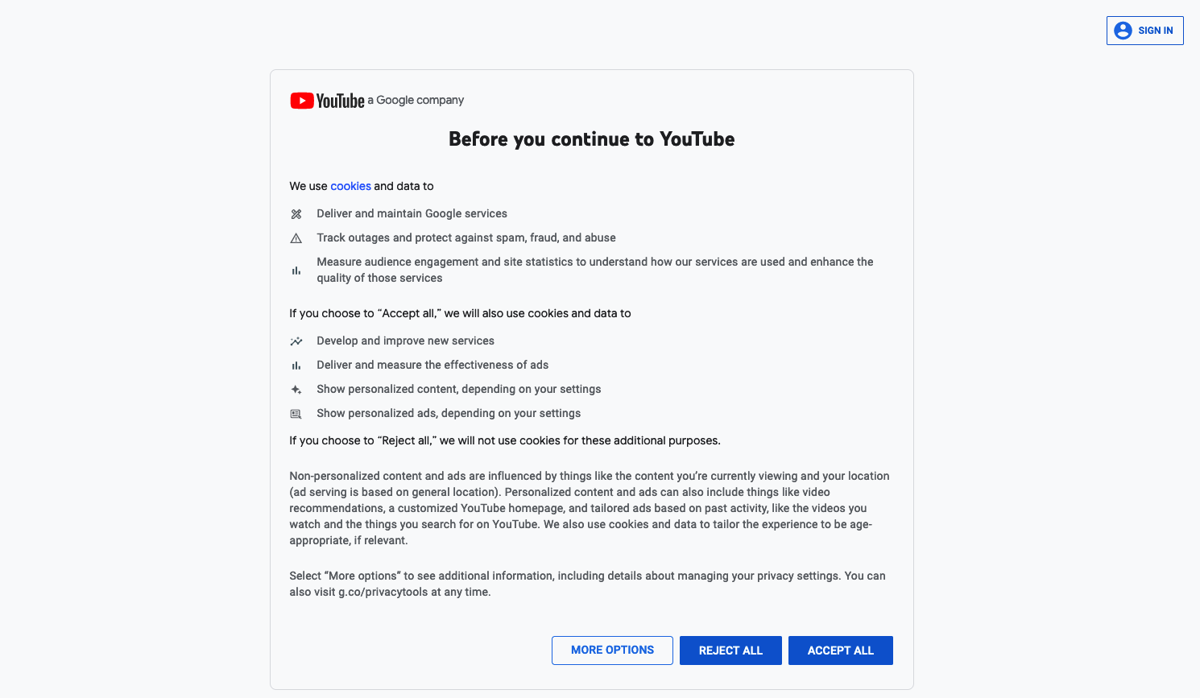
After accepting the cookie consent form, the code instructs ScrapingBee to wait for a few seconds for the page to load and then scroll to the end of the page. You can add as many scrolls and waits as you want and ScrapingBee will do as you say without any hiccups.
We are also making use of the premium proxies provided by ScrapingBee as regular proxies are easily blocked by Google.
Finally, we pass in the extract rules. These instruct ScrapingBee on how to extract the data. The HTML selectors are a bit different here because, unlike the XPath selectors, ScrapingBee executes the JavaScript code in the page and these selectors are JS-based selectors. This can be extremely useful when you need to extract data from a page that makes heavy use of JavaScript such as SPAs (Single Page Applications).
ScrapingBee will make sure that you are charged only for a successful response which makes it a really good deal.
Conclusion
In this article, you learned about how to scrape data from YouTube using Selenium. You got introduced to XPaths and saw their usefulness in web scraping. And finally, you learned how to make sure you don't get blocked by using a reliable proxy provider: ScrapingBee.
You can follow the same steps to extract data about individual videos or to scrape search results from YouTube. You can even use this code in conjunction with youtube-dl or something similar to download specific videos for offline viewing.
I hope you learned something new from this article. If you have any questions regarding web scraping, please feel free to reach out. We would love to help you!
Before you go, check out these related reads:

Yasoob is a renowned author, blogger and a tech speaker. He has authored the Intermediate Python and Practical Python Projects books ad writes regularly. He is currently working on Azure at Microsoft.
