Introduction
If you have already browsed our blog a bit, you will probably have already come across our introduction to XPath expressions, as well as our article on using CSS selectors for web scraping - if you haven't yet, highly recommended 👍. Quite a few good reads.
So you may already have a good idea of what they do and how they are used, but what might be missing - to complete the picture - is how they compare to each other. That's exactly what we are going to do in today's article.
We will pit them against each other and have a side-by-side comparison of their features, discuss their historical backgrounds, and take a look for which use cases they are ideal, and where they manage to shine.

Ready to rumble? 🥊
Purpose of XPath expressions and CSS selectors
Yes, we did just say we assume you already have a good idea of what they do, but if we got our assumption wrong, please allow us to just quickly indulge our readers with a quick overview.
The purpose of XPath expressions and CSS selectors is to provide an expressive language, which allows you to find and select elements in XML and HTML documents.
Let's assume we have the following web page:
<!doctype html>
<html>
<head>
<title>What is the DOM ?</title>
<meta charset="utf-8" />
</head>
<body>
<h1>DOM 101</h1>
<p>Webscraping is awsome !</p>
<p>Here is my <a href="https://www.scrapingbee.com/blog/">blog</a></p>
</body>
</html>
And now we want to extract the URL of our anchor tag pointing to ScrapingBee. How would we do that?
Of course, we can manually parse the whole HTML string (e.g. tokenize everything and check for <a) or - if already more sophisticated - we can use regular expressions (e.g. <a\s+href="([^"]+)), but all of that is what it is: manual string parsing - and that's rarely fun 😓
That's precisely where XPath and CSS selectors come in. In our example, we could access our anchor tag with the following syntax in XPath and CSS respectively.
- XPath expression:
//a - CSS selector:
a
That's a lot easier, isn't it?
💡 Want to know more?
If you want to know more about the nitty-gritty details of each technology, please feel free to check out our dedicated articles:
History of XPath and CSS selectors
Both technologies go back quite some time. They both came out around the mid to late 90s and while they are very, very similar in many regards - and could be considered cousins or even brothers - they still do have different origins and different original purposes.
XPath: While the borders between HTML and XML have, admittedly, always been a tad fluid, HTML has always had a focus on the web, whereas XML has always been primarily a structured document format for data. And that's where XPath came in. XPath was introduced at the same time as XML and has had the purpose to provide a query language for XML. It should allow you to quickly and easily access information within a given XML document, regardless of whether it's the web or an infamous XML database.
CSS: CSS selectors were not an invention on their own but are part of the overall CSS ecosystem. They are an integral part of it, however, as they provide the core functionality of finding the very element(s), to which the rule's declaration block will be applied. In this context, CSS selectors have always had a very strong (and almost exclusive) focus on the web and web pages.
While XPath stayed (mostly) true to its original purpose, of providing a query language for XML document structures (which includes HTML), CSS selectors eventually surpassed their styling-only use and emerged as stand-alone technology for querying web documents.
As we briefly mentioned, both technologies are almost identical in what they want to offer and they also share certain syntax similiarities, however, there are still quite a few differences between them, as well as advantages and limitations. This is what we are going to check out next.
Advantages & Limitations of XPath
Generally speaking, XPath is the slightly more sophisticated language (apologies, CSS 🙏). If you can implement a query with CSS selectors, you can do the same with XPath. The other way round is not always possible.
For example, one of the major advantages is its ability to support bi-directional tree-traversal. You can find a particular element and then specifically selects its parent or even ancestors, using the parent axis. Even though, CSS selectors do offer a semi-equivalent with the :has pseudo-class, that still is a far cry from XPath, as it will only cover a limited set of use cases and its browser support is still rather shaky.
While raw performance will typically not be a major concern in this context, you may still sometimes experience better performance with XPath than with CSS selectors. This is because a few CSS selector engines actually use XPath internally and convert their selectors to XPath expressions first.
One of the drawbacks of XPath, certainly, is its more verbose syntax. Things like HTML classes need to be specified in their actual attribute form, whereas CSS supports them as, let's say, first-class citizens in its syntax.
Pros & Cons
+ Supports bi-directional tree-traversal (accessing a parent or ancestor element)
+ Supports the selection of more than just document elements (i.e. also attributes and content)
+ Built-in functions for a number of use cases (e.g. text(), count())
+ Supports absolute and relative search paths
- More verbose syntax
Advantages & Limitations of CSS Selectors
One of the main advantages of CSS selectors is their "nativeness" in the context of the web. If you are familiar with web development, you'll immediately know your way around CSS selectors, because you have used them for ages already in all your page styling.
Contrary to XPath expressions, CSS selectors are perfectly aware of what HTML IDs and classes are and provide native syntax elements (i.e. #id & .class). For that reason, CSS selector could be also considered slightly less verbose (a#id vs //a[@id="id"]).
On the side of limitations, you have the fact that CSS selectors only work on an element level. That is, if you want to extract the link of an <a> tag, you can use CSS selectors only to find all relevant tags and will need to access the href attribute in a second step, outside of the CSS selector context (e.g. tag.getAttribute("href")). XPath expressions allow here direct access to attributes as well (i.e. //a/@href).
Another major limitation is the top-down approach, which means you can traverse the DOM tree only in one direction and cannot select parent elements (like `.. for file systems, for example). While this might not be the most common use case, there still are times when that may be handy and, with CSS selectors, you may have to find some workaround.
Pros & Cons
+ Web developers are familiar with the syntax
+ HTML IDs and classes are first-class citizens (hash and dot syntax)
- Can only select elements (no attributes or content)
- Does not support upward traversal (accessing a parent or ancestor element)
- More difficult to specify an absolute search path
Examples
| We'd like to get .... | XPath expression | CSS selector |
|---|---|---|
all a elements | //a | a |
all a elements with the HTML class "external" | //a[@class='external'][a] | a.external |
the image paths of all img elements | //img/@src | N/A |
all h1 elements with a children | //h1[count(.//a) > 0] | h1:has(a)[b] |
all ul elements with more than five li children | //ul[count(.//li) > 5] | N/A |
the text content of all b elements | //b/text() | N/A |
the last p elements of all h2 elements | //h2/p[last()] | h2 > p:last-child |
all elements with a type attribute | //*[@type] | [type] |
the second li child of all ul elements [c] | //ul/li[1] | ul > li:nth-child(2) |
[a] Example for brevity, a complete check would be more complex.
[b] :has still only has very limited browser support
[c] XPath is zero-based, whereas CSS is one-based
Data Extraction with CSS selectors and ScrapingBee
Just in case you are not yet familiar with ScrapingBee's data extraction service: it's a SaaS scraping platform with a lightweight REST API, native SDK packages for selected languages, and support for headless browser integrations.
Even though XPath is undoubtedly more advanced for some use cases, the world of web scraping is very much defined by CSS selectors and users - in particularly webdev folks - often feel more comfortable with them, which is why ScrapingBee opted to support CSS selectors as primary expression language in the API.
Running a data extraction job is pretty straightforward and you just need to provide a JSON object with the fields you'd like to extract from the page as part of the extract_rules parameter.
For example, the following object would define two extraction items ("title" and "subtitle") along with their respective CSS selectors (h1 for the title and #subtitle for the sub-title).
{
"title": "h1",
"subtitle": "#subtitle"
}
In the response, you'll receive a similar JSON object, containing the fields with their values from the page.
If you want to know more, please find all the details on the respective page in the documentation.
ℹ️ Free Trial
ScrapingBee offers a completely free trial with 1,000 API requests on the house - no strings attached! Please feel free to check it out.
Using XPath and CSS selectors in the browser
While there are plenty of tools (e.g. https://try.jsoup.org) out there, which will help you in managing XPath and CSS selector expressions, you actually already have one such tool installed on your machine, the one you are using right now: your browser
The developer tools in both, Chrome and Firefox, not only make it really easy for you to evaluate and debug your XPath and selector expressions, but they also assist you in finding the right expressions in the first place. Simply right click the element in question and choose Inspect.

You should now have the page's DOM tree open and can access the individual elements.
Finding the right XPath and CSS selector with the browser
In our example on example.com, we right-clicked the "More information" link and now have the context menu with all the relevant options. Let's pick Copy next. Here, the highlighted entries will be of our particular interest.
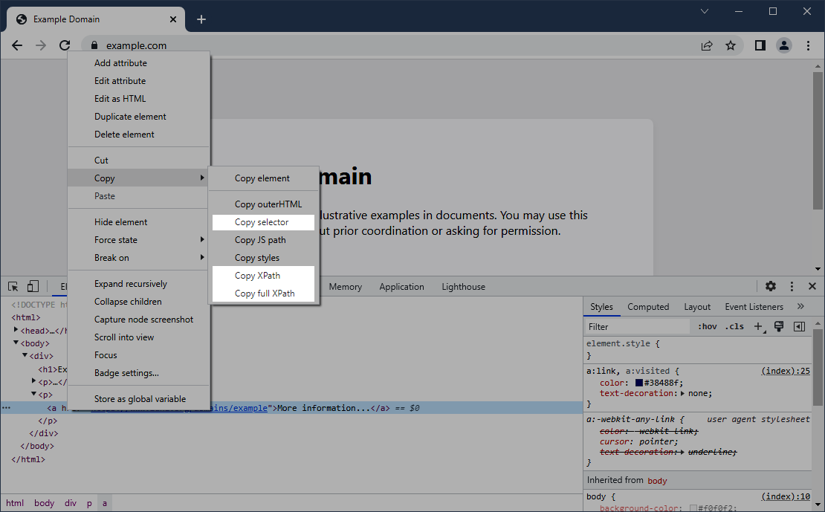
If we choose Copy selector, the browser will save the element's CSS selector path in our clipboard, such as the following expression:
body > div > p:nth-child(3) > a
If, on the other hand, we choose Copy XPath or Copy full XPath, the browser will do the same with the following XPath expression:
/html/body/div/p[2]/a
💡 The difference between the two options is, the latter (
Copy full XPath) copies a full and absolute path expression, whereas the former may already try to optimize the expression if possible (e.g. based on HTML IDs). But more on that in just a second.
In either case, you should now have an expression in your clipboard for that particular element. Though, one thing to keep in mind is, even Google and Mozilla probably can't work wonders (yet) and those expressions may be only applicable for that very page, and maybe even page load. Often it can be necessary to fine-tune the expression.
Fine-tuning expressions
Our two previous examples were all absolute paths and worked just beautifully in our context, however there's always room for optimizations. For example, given that example.com only has one single link, we could have easily abbreviated our expressions to the following ones:
# XPath
//a
# CSS
a
But let's take a more concrete example, like the following ScrapingBee tweet.
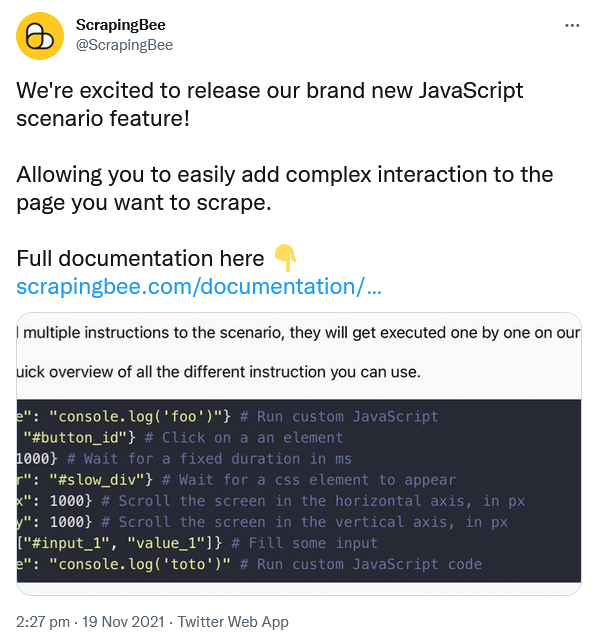
If we simply copy the CSS selector in this case, we'll get something like that.
html body div#react-root div.css-1dbjc4n.r-13awgt0.r-12vffkv div.css-1dbjc4n.r-13awgt0.r-12vffkv div.css-1dbjc4n.r-18u37iz.r-13qz1uu.r-417010 main.css-1dbjc4n.r-1habvwh.r-16y2uox.r-1wbh5a2 div.css-1dbjc4n.r-150rngu.r-16y2uox.r-1wbh5a2.r-rthrr5 div.css-1dbjc4n.r-aqfbo4.r-16y2uox div.css-1dbjc4n.r-1oszu61.r-1niwhzg.r-18u37iz.r-16y2uox.r-1wtj0ep.r-2llsf.r-13qz1uu div.css-1dbjc4n.r-14lw9ot.r-jxzhtn.r-1ljd8xs.r-13l2t4g.r-1phboty.r-1jgb5lz.r-11wrixw.r-61z16t.r-1ye8kvj.r-13qz1uu.r-184en5c div.css-1dbjc4n section.css-1dbjc4n div.css-1dbjc4n div div div.css-1dbjc4n.r-j5o65s.r-qklmqi.r-1adg3ll.r-1ny4l3l div.css-1dbjc4n div.css-1dbjc4n article.css-1dbjc4n.r-18u37iz.r-1ny4l3l.r-1udh08x.r-1qhn6m8.r-i023vh div.css-1dbjc4n.r-eqz5dr.r-16y2uox.r-1wbh5a2 div.css-1dbjc4n.r-16y2uox.r-1wbh5a2.r-1ny4l3l div.css-1dbjc4n div.css-1dbjc4n div.css-1dbjc4n.r-1r5su4o div.css-1dbjc4n.r-1awozwy.r-18u37iz.r-1wtj0ep div.css-901oao.r-14j79pv.r-37j5jr.r-a023e6.r-16dba41.r-rjixqe.r-1b7u577.r-bcqeeo.r-qvutc0 div.css-1dbjc4n.r-1d09ksm.r-1471scf.r-18u37iz.r-1wbh5a2 a.css-4rbku5.css-18t94o4.css-901oao.css-16my406.r-14j79pv.r-1loqt21.r-xoduu5.r-1q142lx.r-1w6e6rj.r-poiln3.r-9aw3ui.r-bcqeeo.r-3s2u2q.r-qvutc0 time
On one hand, unfortunately, that's not only not very legible but that may not even work on a reload because of changing HTML classes.
On the other hand, fortunately, we have a very specific HTML element in this case, which will dramatically simplify the whole thing -> <time>
We simply use time (or //time for XPath) and we "only" get the element we want. Quotes, because Twitter shows associated tweets and each will have a <time> element, so make sure to only use the first one.
However, it's not only specific element types which can help us narrow down an expression, we should also look out for HTML IDs, classes, attributes, and sometimes even content.
- IDs are supposed to be unique, so a quick
#myidor (//*[@id="myid"]) will get you an element in a swifter and more stable fashion than an absolute path. - While classes are not necessarily unique, they can still work magic, especially if, for example placed in context of the document hierarchy:
h1 > b.price
Please also check out the Optimizing The Selector section in our article on CSS selectors, as that discusses our Twitter example in detail and shows one more example how we can access the date, using the content.
Evaluating expressions in the browser
Last, but not least, the devtools also allow us to evaluate XPath expressions and CSS selectors.
Simply hit F12 one more time, select the Elements tab, and press Ctrl/⌘ + F to open the search box.
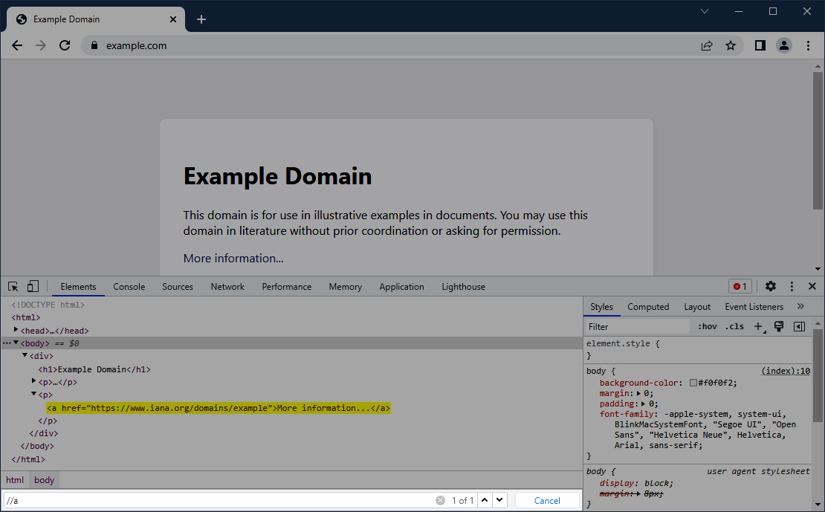
Here, you can now try different XPath expressions and CSS selectors and iterate over the found elements (if there are such, of course).
Pretty handy to quickly try an expression 👍
Summary
We hope you enjoyed the article and you got a good, first understanding of what the two languages are and where their strengths and their differences are.
As we tried to focus with this article on the main differences between XPath and CSS selectors, we did go in-depth into the technical details of the syntax elements of each language. But no worries please, we do have you covered here and would recommend the two articles, we mentioned earlier:
These articles cover both technologies in detail and come with wide array of different examples and detailed explanations.
Should you have any further questions or feedback on this article or how to use CSS selectors on ScrapingBee for your next web crawler project, then please do not hesitate even a second to reach out to us. We are happy to answer your questions and assist you in your scraping tasks.
As always, happy scraping with XPath and CSS!

Alexander is a software engineer and technical writer with a passion for everything network related.
