Documentation - Proxy Mode
What is the proxy mode?
ScrapingBee also offers a proxy front-end to the API. This can make integration with third-party tools easier. The Proxy mode only changes the way you access ScrapingBee. The ScrapingBee API will then handle requests just like any standard request.
Request cost, return code and default parameters will be the same as a standard no-proxy request.
We recommend disabling Javascript rendering in proxy mode, which is enabled by default. The following credentials and configurations are used to access the proxy mode:
- HTTP address:
proxy.scrapingbee.com:8886 - HTTPS address:
proxy.scrapingbee.com:8887 - Socks5 address:
socks.scrapingbee.com:8888 - Username:
YOUR-API-KEY - Password:
PARAMETERS
Important : Replace PARAMETERS with our supported API parameters. If you don't know what to use, you can begin by using render_js=False. If you want to use multiple parameter, use & as a delimiter, example: render_js=False&premium_proxy=True
Important: if you try to scrape Google with this mode, each requests will cost 20 credits.
As an alternative, you can use URLs like the following:
{
"url_http": "http://YOUR-API-KEY:PARAMETERS@proxy.scrapingbee.com:8886",
"url_https": "https://YOUR-API-KEY:PARAMETERS@proxy.scrapingbee.com:8887",
"url_socks5": "socks5://YOUR-API-KEY:PARAMETERS@socks.scrapingbee.com:8888",
}
Use our request builder, accessible from your dashboard to help configure the proxy mode. 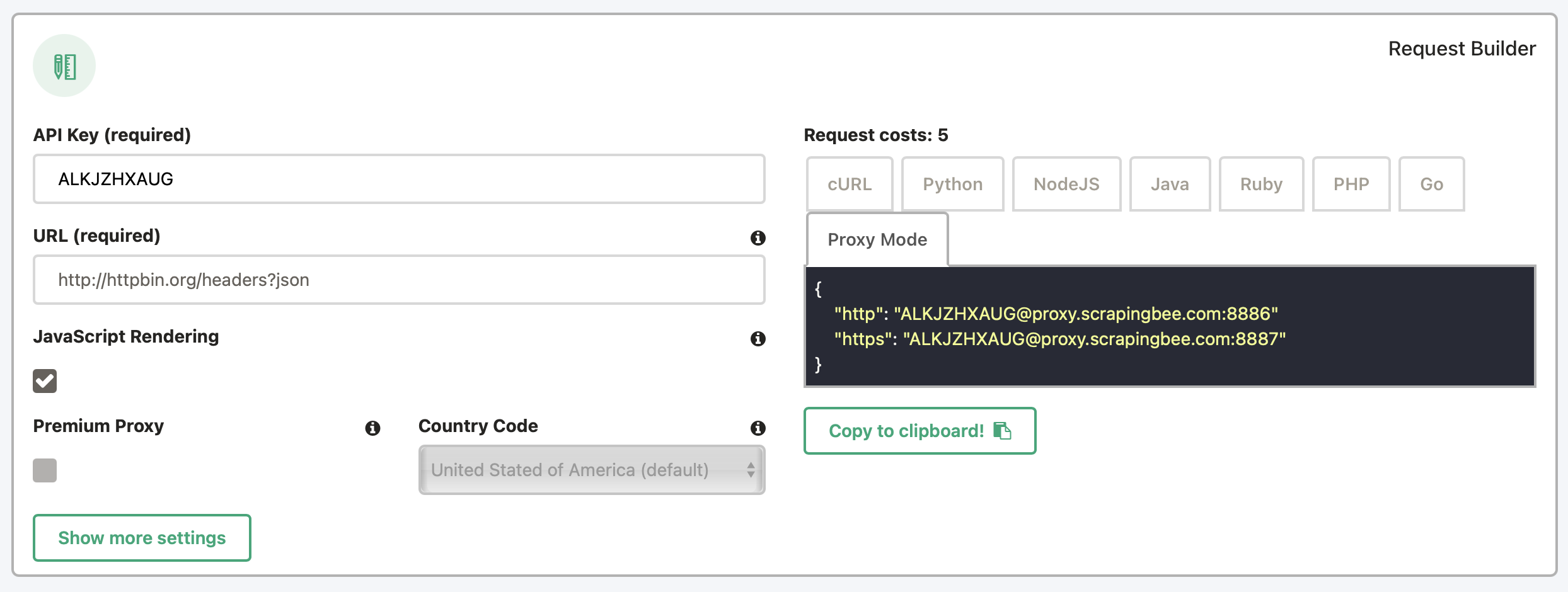
Use proxy mode with your favorite language?
curl -k -x "https://YOUR-API-KEY:render_js=False&premium_proxy=True@proxy.scrapingbee.com:8887" 'https://httpbin.org/anything?json' -v# Install the Python Requests library:
# pip install requests
import requests
def send_request():
proxies = {
"http": "http://YOUR-API-KEY:render_js=False&premium_proxy=True@proxy.scrapingbee.com:8886",
"https": "https://YOUR-API-KEY:render_js=False&premium_proxy=True@proxy.scrapingbee.com:8887"
}
response = requests.get(
url="http://httpbin.org/headers?json",
proxies=proxies,
verify=False
)
print('Response HTTP Status Code: ', response.status_code)
print('Response HTTP Response Body: ', response.content)
send_request()# Install the Python selenium-wire library:
# pip install selenium-wire
from seleniumwire import webdriver
username = "YOUR-API-KEY"
password = "render_js=False"
options = {
"proxy": {
"http": f"http://{username}:{password}@proxy.scrapingbee.com:8886",
"https": f"http://{username}:{password}@proxy.scrapingbee.com:8886",
"verify_ssl": False,
},
}
URL = "https://httpbin.org/headers?json"
chrome_options = webdriver.ChromeOptions()
### This blocks images and javascript requests
chrome_prefs = {
"profile.default_content_setting_values": {
"images": 2,
"javascript": 2,
}
}
chrome_options.experimental_options["prefs"] = chrome_prefs
###
driver = webdriver.Chrome(
executable_path="YOUR-CHROME-EXECUTABLE-PATH",
chrome_options=chrome_options,
seleniumwire_options=options,
)
driver.get(URL)// request Axios
const axios = require('axios');
const querystring = require('querystring');
axios.get('http://httpbin.org/headers?json', {
proxy: {
host: 'proxy.scrapingbee.com',
port: 8886,
auth: {username: 'YOUR-API-KEY', password: 'render_js=False&premium_proxy=True'}
}
}).then(function (response) {
// handle success
console.log(response);
})const puppeteer = require('puppeteer');
(async() => {
const blockedResourceTypes = [
'beacon',
'csp_report',
'font',
'image',
'imageset',
'media',
'object',
'texttrack',
'stylesheet',
];
const username = "YOUR-API-KEY"
const password = "render_js=False"
const address = "proxy.scrapingbee.com"
const port = "8886"
const browser = await puppeteer.launch({
args: [ `--proxy-server=http://${address}:${port}` ],
ignoreHTTPSErrors: true,
headless: false
});
const page = await browser.newPage();
// We suggest you block resources, because each request will cost you at least 1 API credit
await page.setRequestInterception(true);
page.on('request', request => {
const requestUrl = request._url.split('?')[0].split('#')[0];
if (blockedResourceTypes.indexOf(request.resourceType()) !== -1) {
console.log(`Blocked type:${request.resourceType()} url:${request.url()}`)
request.abort();
} else {
console.log(`Allowed type:${request.resourceType()} url:${request.url()}`)
request.continue();
}
});
await page.authenticate({username, password});
await page.goto('https://www.scrapingbee.com');
await browser.close();
})();require 'httparty'
HTTParty::Basement.default_options.update(verify: false)
# Classic (GET )
def send_request
res = HTTParty.get('https://httpbin.org/anything?json', {
http_proxyaddr: "proxy.scrapingbee.com",
http_proxyport: "8886",
http_proxyuser: "YOUR-API-KEY",
http_proxypass: "render_js=False&premium_proxy=True"
})
puts "Response HTTP Status Code: #{ res.code }"
puts "Response HTTP Response Body: #{ res.body }"
puts "Response HTTP Response Body: #{ res.header }"
rescue StandardError => e
puts "HTTP Request failed (#{ e.message })"
end
send_request()<?php
// get cURL resource
$ch = curl_init();
// set url
curl_setopt($ch, CURLOPT_URL, 'https://httpbin.org/anything?json');
// set proxy
curl_setopt($ch, CURLOPT_PROXY, "https://YOUR-API-KEY:render_js=False&premium_proxy=True@proxy.scrapingbee.com:8887");
// set method
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');
// return the transfer as a string
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0);
// send the request and save response to $response
$response = curl_exec($ch);
// stop if fails
if (!$response) {
die('Error: "'.curl_error($ch).'" - Code: '.curl_errno($ch));
}
echo 'HTTP Status Code: '.curl_getinfo($ch, CURLINFO_HTTP_CODE) . PHP_EOL;
echo 'Response Body: '.$response . PHP_EOL;
// close curl resource to free up system resources
curl_close($ch);
?>package main
import (
"fmt"
"crypto/tls"
"io/ioutil"
"net/http"
"net/url"
)
func sendClassic() {
//creating the proxyURL
proxyStr := "https://YOUR-API-KEY:render_js=False&premium_proxy=True@proxy.scrapingbee.com:8887"
proxyURL, err := url.Parse(proxyStr)
if err != nil {
fmt.Println(err)
}
//adding the proxy settings to the Transport object
transport := &http.Transport{
Proxy: http.ProxyURL(proxyURL),
TLSClientConfig: &tls.Config{InsecureSkipVerify: true},
}
//adding the Transport object to the http Client
client := &http.Client{
Transport: transport,
}
// Create request
req, err := http.NewRequest("GET", "https://httpbin.org/anything?json", nil)
parseFormErr := req.ParseForm()
if parseFormErr != nil {
fmt.Println(parseFormErr)
}
// Fetch Request
resp, err := client.Do(req)
if err != nil {
fmt.Println("Failure : ", err)
}
// Read Response Body
respBody, _ := ioutil.ReadAll(resp.Body)
// Display Results
fmt.Println("response Status : ", resp.Status)
fmt.Println("response Headers : ", resp.Header)
fmt.Println("response Body : ", string(respBody))
}
func main() {
sendClassic()
}Please keep the following requirements in mind if you decide to use proxy mode
- If you want to use proxy mode, your code must be configured not to verify SSL certificates.
-kwithcURL,verify=Falsewith PythonRequests, etc ... - Because JavaScript rendering is enabled by default, don't forget to use
render_js=Falseto disable it. - If you decide to use proxy mode with Selenium or Puppeteer, every request made by the headless browser will result in an API call, so we recommend limiting the amount of resources requested by your browser.
- In order to maximize compatibility, if you wish to forward headers using proxy mode, only set
forward_headers=True, no need to prefix your headers with "Spb-" like in normal mode.
Apify integration
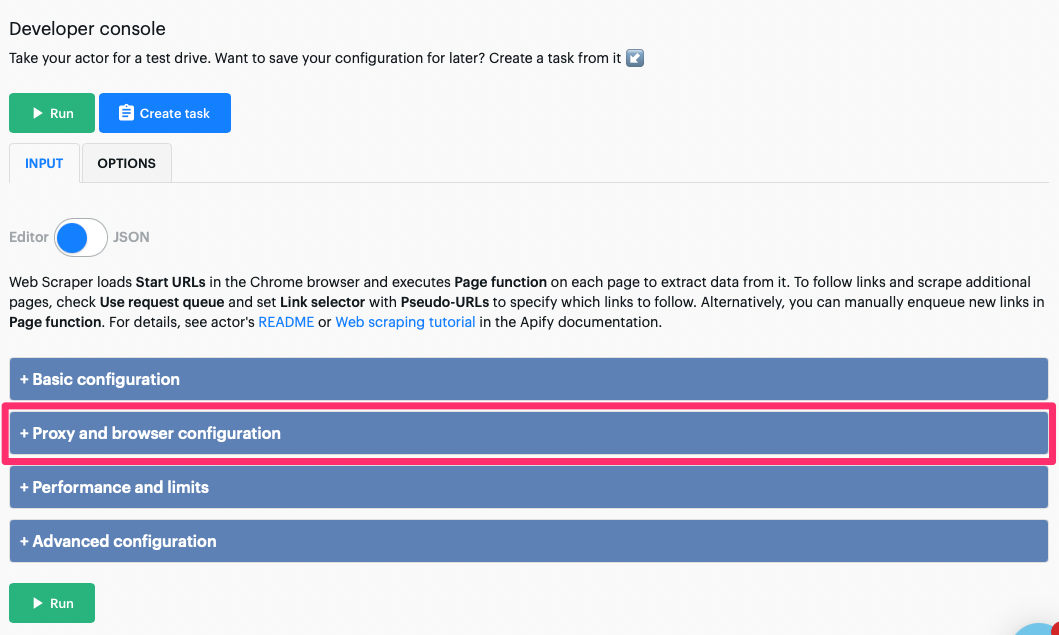
To integrate ScrapingBee proxy mode with Apify, just do as follow
1. On your actor configuration page, go to the "Proxy and browser configuration section"
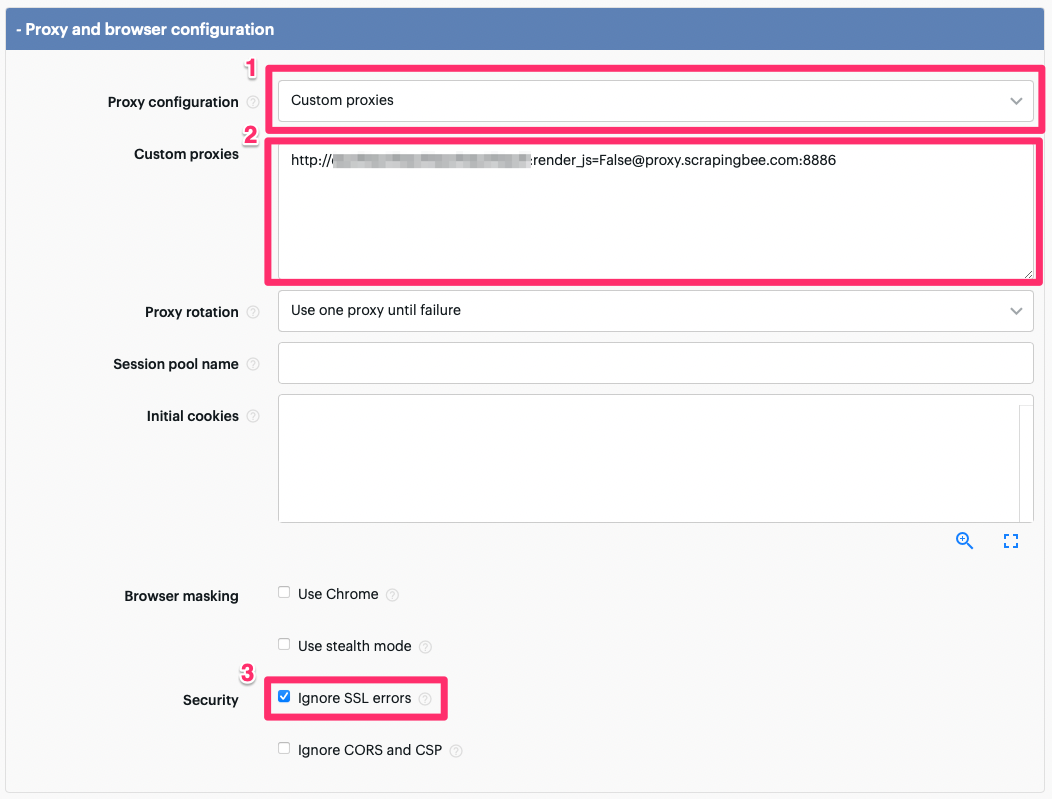
2. Then, choose "Custom proxies" for the Proxy configuration, enter your proxy string, and do not forget to check "Ignore SSL errors".
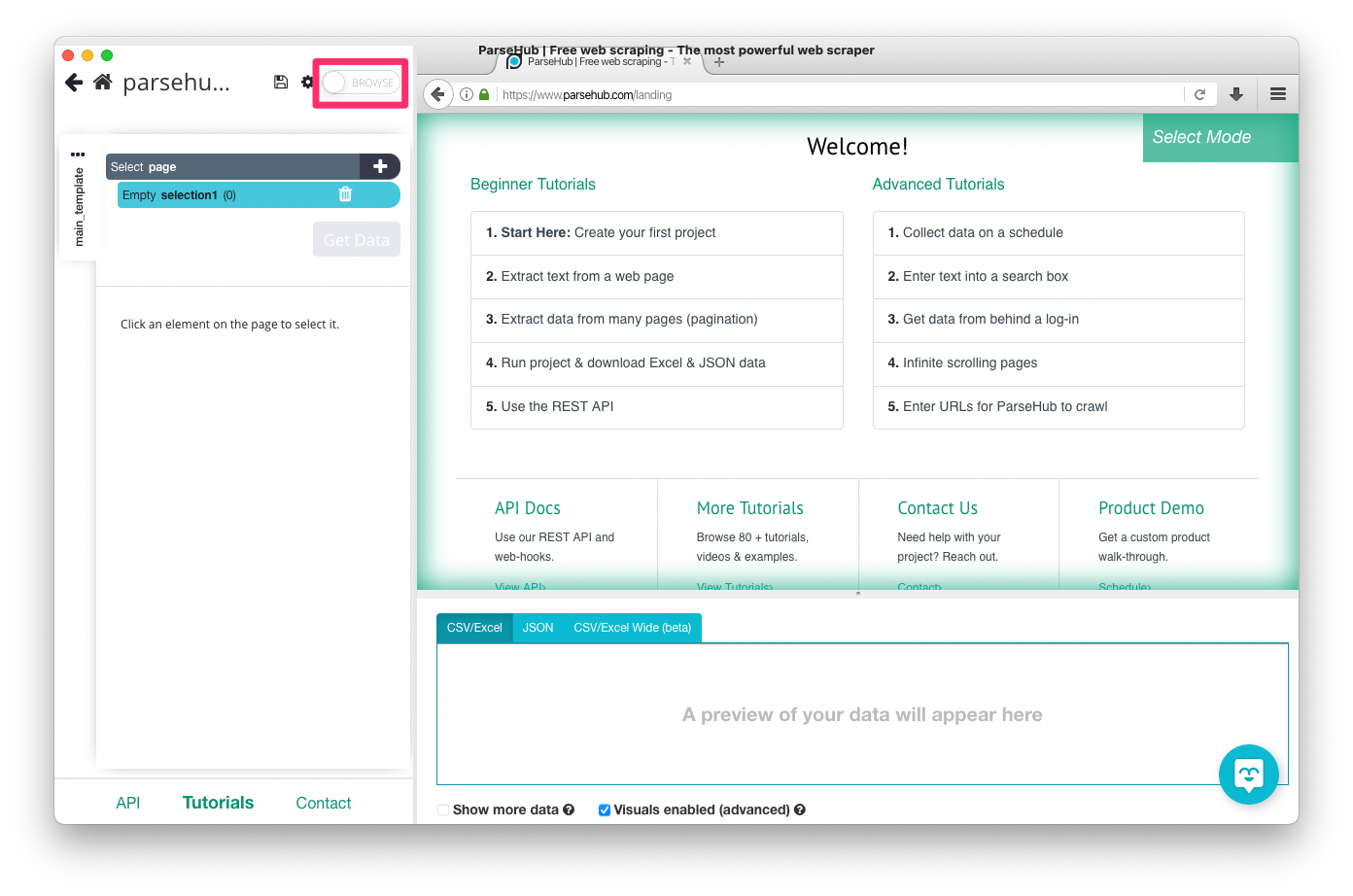
Parsehub Integration
Once on your project is configured, enabled "BROWSE" mode.
Click then on the top-right burger, "network tab", and the "settings" button of the "connection" section.
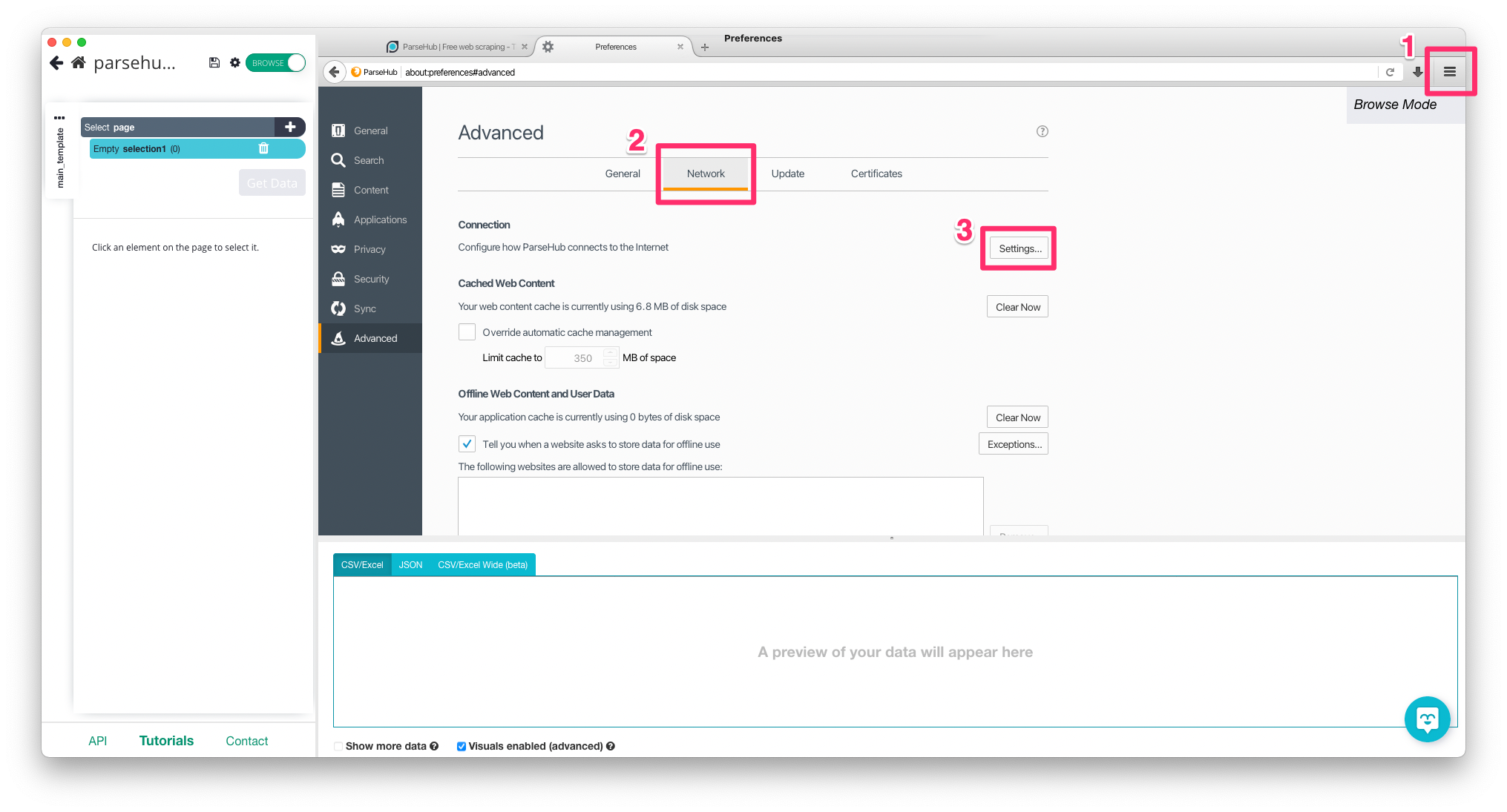
Here, enter the ScrapingBee proxy addresses and ports. Use the same port for SSL and HTTP proxy.
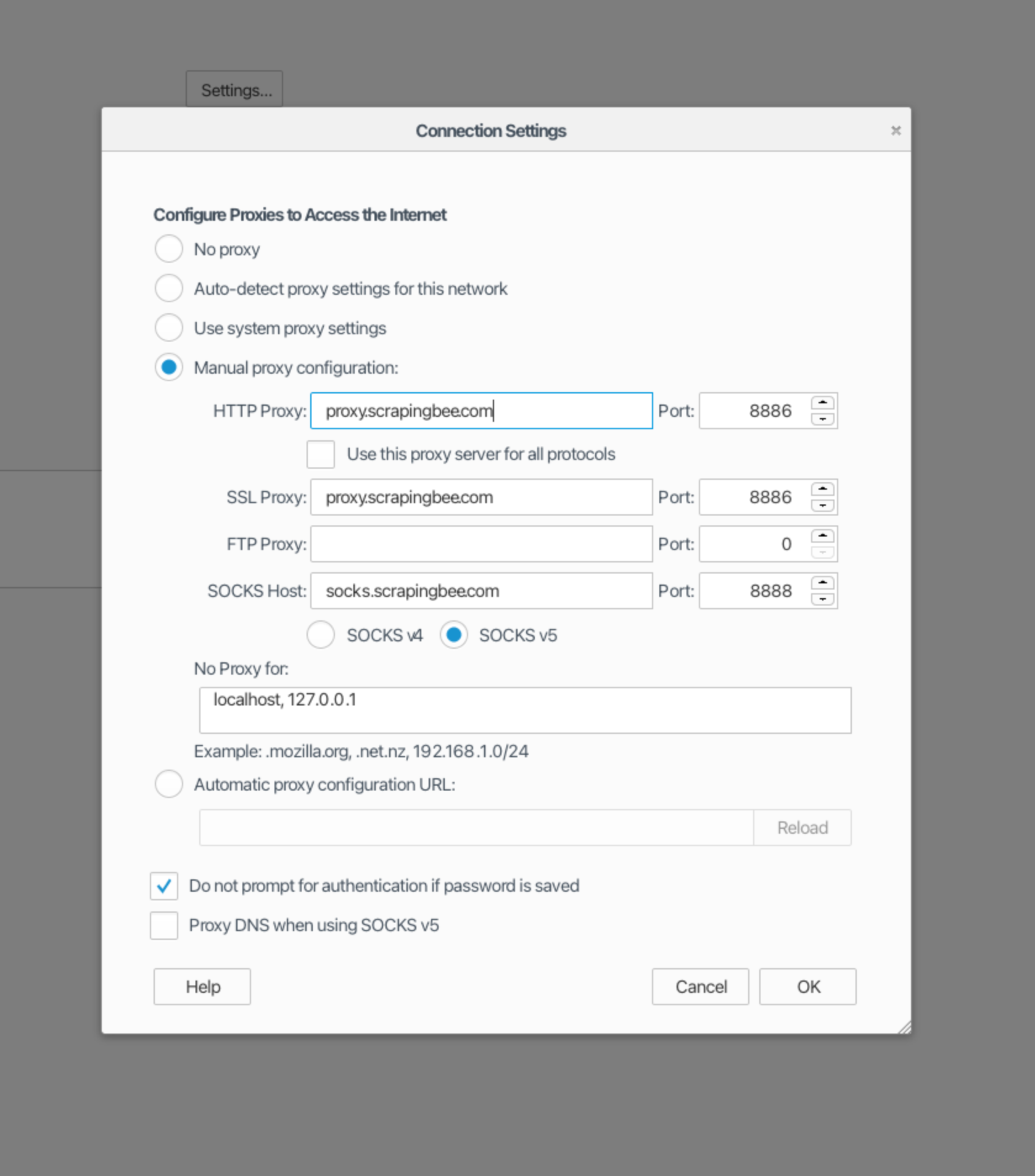
Once your project start, you'll be prompt with an authentication form. Here use your API key as the username and the custom parameters your wish to use as the password. If you're not sure what to put in the password field, just use "render_js=False".
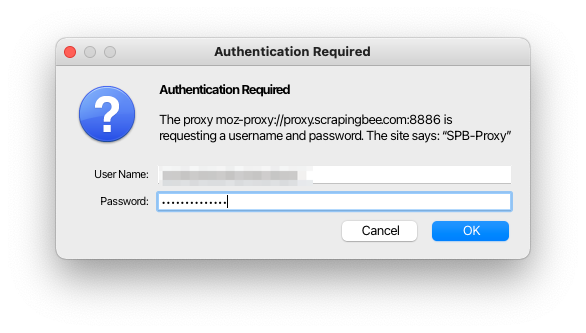
You also may have to accept non verified SSL connection.
Phantombuster integration
Coming Soon
Web Scraper integration
Coming Soon
Kameleo integration
Coming Soon
Octoparse integration
Since Octoparse is currently not supporting authentication based proxies, ScrapingBee proxy-mode currently can't work with this tool.