The early days
We (Kevin and Pierre) met in high school in a small town located in the south of France.

We go learn CS at university. During that time, we started to learn about YC, IndieHackers, Rob Walling's book, the family, and this whole startup/bootstrapping ecosystem.
We learned that you didn't need to raise $100m to build a successful business!
Kevin works for a small startup doing some invoice and banking data aggregation.
Things are fun.
Then the company was acquired by one of the top 4 big French banks.
Things become less fun.
He quits and starts to write a book about Java and web scraping.

First product
We build ShopToList, a price monitoring extension. You save the products you want to buy and get notified as soon as its price drops.
We get a decent traction and have a quite successful ProductHunt launch.
But that is not enough. We can't find a way to monetize the product and haven't found a scalable way to acquire more users. We sell the product to a web agency and move on to other projects.
Going full-time and building our first SaaS
While building ShopToList we notice that many people use ShopToList to spy on their competitor's prices.
In the meantime, Pierre had left his job as a data engineer for the french Zillow.
So this time, we decided to build a price monitoring tool instead.
This time, we will target businesses (B2B) in a validated niche. This makes us confident that this could work.
We were wrong.
After two months in beta, countless user interviews, and many bug fixes, we finally released PricingBot.
Soon after getting out of beta, we finally managed to get our first customer. We're ecstatic that real businesses give us real money for a product we make for the first time.
After months of endless marketing experimentation, feature development, and optimizations we have to face that people don't want to pay for our product.
We also notice that we are building into a niche that we don't know well (e-commerce), which shows a lot when talking to potential customers.
We're considering moving on to something else.

Pivoting to a web scraping API
While building PricingBot, we used a lot of web scraping tools. And we noticed that all of them shared common flaws: hard to use, slow, not reliable, not transparent about who operates the business.
Having a lot of experience in web scraping, we decide to scratch our own itch by developing a web scraping API.
We spend the whole month of June working as much as we could on the MVP. We want to validate the product quickly, and to do that we need something that works.
Leveraging some friends we made on web scraping forums and growth marketing communities, we get around ten free beta-testers to try our product.
It allows us to iterate on what is essential to develop quickly.
Since we didn't want to make the same mistakes we've made with our product, we decide to ask for money as early as possible.
In June, we close the free beta and ask people to take a paid subscription to continue using the product.
To our biggest surprise, the first customer comes 50 minutes after sending the first email. We're delighted, but we know that now the hard part begins.
Building a sustainable SaaS
We know that if we want ScrapingBee to work we need two essential things:
- a product that sticks: recurring revenue
- a scalable acquisition channel
About the first point, we make the bet that most of our customers have regular web scraping needs and that if we make a good product, they'll stay with us.
For the second one, we bet on content. Kevin had been writing a lot about web-scraping in the past years, including a full book, and we think we can attract potential customers by writing good content.
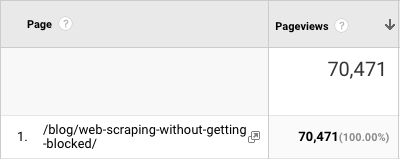
We start trying to write the best possible content. And people love it. Our first big blog post was the "Web scraping without getting blocked" guide. We shared it a bit all over the place, and it quickly got 20,000 visitors. Proof that people like good content, even if it is written on a company blog.
PS: this article has now been read by more than 70,000 people 😎
Writing good content was working well, but it was very slow. Slow to produce, but also slow to rank on Google. So we start trying a lot of other acquisition channels to try to speed the business up. It was a mistake, making us lose focus and waste money. We go back to content and spend a lot of time writing other web scraping guides in several languages carefully:
In the early days, we try to speak to as many people as possible to build the best web scraping tool out there.
But talking to customers can be challenging. Their time is precious, and most of them don't like to speak to companies for fear of getting trapped in an endless upsell call.
So Kevin had the idea to offer 10,000 API calls to anyone willing to discuss their web-scraping needs for 15 minutes over the phone.
This move allowed us to talk to around 100 people in less than three months and learn invaluable insights.
The road to $10k MRR
The goal with ScrapingBee was always to find a sustainable business, where we would be in complete control of what happens in the company without having the pressure to grow at all costs. And this is precisely why we never decided to raise money. However, a few years ago, Rob Walling and his friends launched TinySeed. An accelerator designed precisely to help people grow their business, but without any pressure to become a unicorn.
We applied and got lucky enough to get accepted. The money and the support we got from the program helped us grow ScrapingBee into what it is now.

2020 was a very "grind" year. And to be honest, all we did was the same thing over and over. Improving the product, releasing new content. In the spring we focused a lot on the customer experience, doing everything we could to make the API as easy as possible to use. We developed SDK in Python and JavaScript, a brand new documentation with snippets in 7 languages and a request builder.

In November, we finally reach $10,000 Monthly Recurring Revenue. A very symbolic milestone for us, because for the first time, it allowed us to get paid (almost) the same as our previous job, and it also meant that we were profitable.
But as you can see, this took a while. We started working on ScrapingBee almost 18 months before this moment.
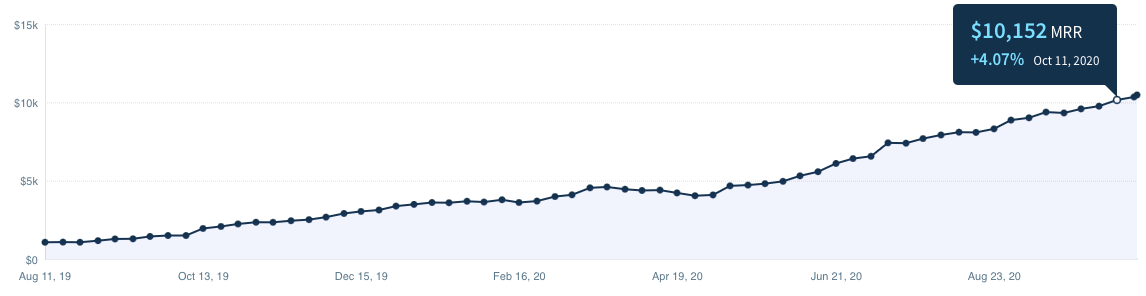
The last quarter of 2020 was a magical moment because, for the first time, we felt that growth was finally kicking in.
And while it took us almost 18 months to get to $10k MRR, it took us only 3 months to double our revenue to $20k MRR.
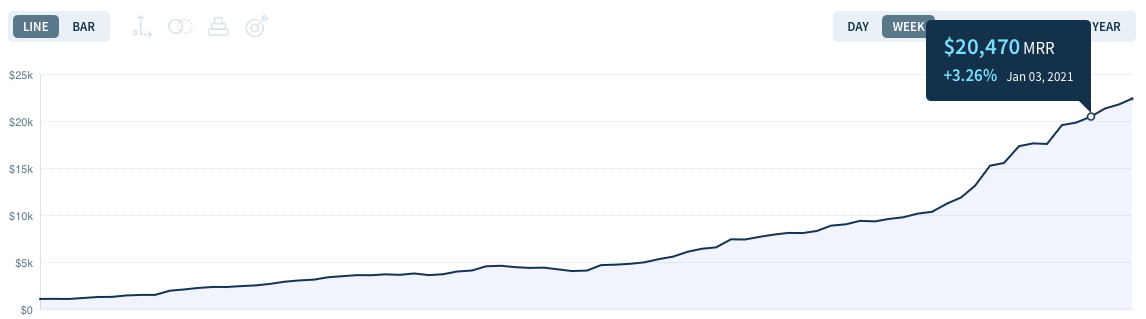
Growing the business
In 2021, we decided to focus on our strengths and write great content while trying to build the best web scraping API.
It is also at that time that Kevin and Pierre decide to split the role in the company. Kevin is now in charge of our whole marketing, and Pierre handles the product and technical side of the business.
We reach a significant milestone, 1,000,000 pageviews on our website, most of it being organic.
It looks like betting on content was the right thing to do.
Etienne joins the team full-time to help us with our growing development needs.
Etienne is a talented developer who worked in various industries before joining us.
In a short amount of time, he's able to release two beloved functionality of the API, the data extraction and the JavaScript scenario.

In November, 6 years after our first product and 2,5 years after launching ScrapingBee, we finally reach the million in Annual Recurring Revenue.
It hasn't been an easy road, and this wouldn't have been possible without all the support we got along the way.
So THANK YOU!
Thank you, friends, family, colleagues, former colleagues, LP, TinySeed tutors, mastermind Zoomers, customers, Twitter supporters, ProductHunt upvoters and blog readers.
Happy Scraping
The story is not over
After 6 months of development, we released a complete redesign of our website in January, with a brand new logo, visual identity, documentation, and blog.

We will soon release a brand new redesign of the app and dashboard, focusing on the analytics part.
We also have exciting new products coming out later this year that we hope you will like.
Happy Scraping!
Who are we?
Developers, Developers, Developers!

Kevin is a web scraping expert and author of The Java Web Scraping Handbook. He's been involved in many web scraping projects, for banks, startups, and E-commerce stores. He now handles all the marketing at ScrapingBee.

Pierre is a data-engineer. He's been involved in many startups, in the US and in Europe. Previously, with Kevin, he co-founded PricingBot a price-monitoring service for E-commerce. He now takes care of the tech / product side of ScrapingBee.

Etienne is a senior developer with a wide range of experiences. From developing a product from the ground-up at a fast-scaling startup to computer vision for the aerospace industry, he's now in charge of everything technical at ScrapingBee. He also gives some help with the trickiest support tickets.

Nizar is an experienced support engineer who will go above and beyond to help with your ScrapingBee experience. Having a wide range of technical skills, he will help you fix your scraping scripts and understand how you can extract the data you need with ScrapingBee.