Nowadays, most websites use different methods and techniques to decrease the load and data served to their clients’ devices. One of these techniques is the infinite scroll.
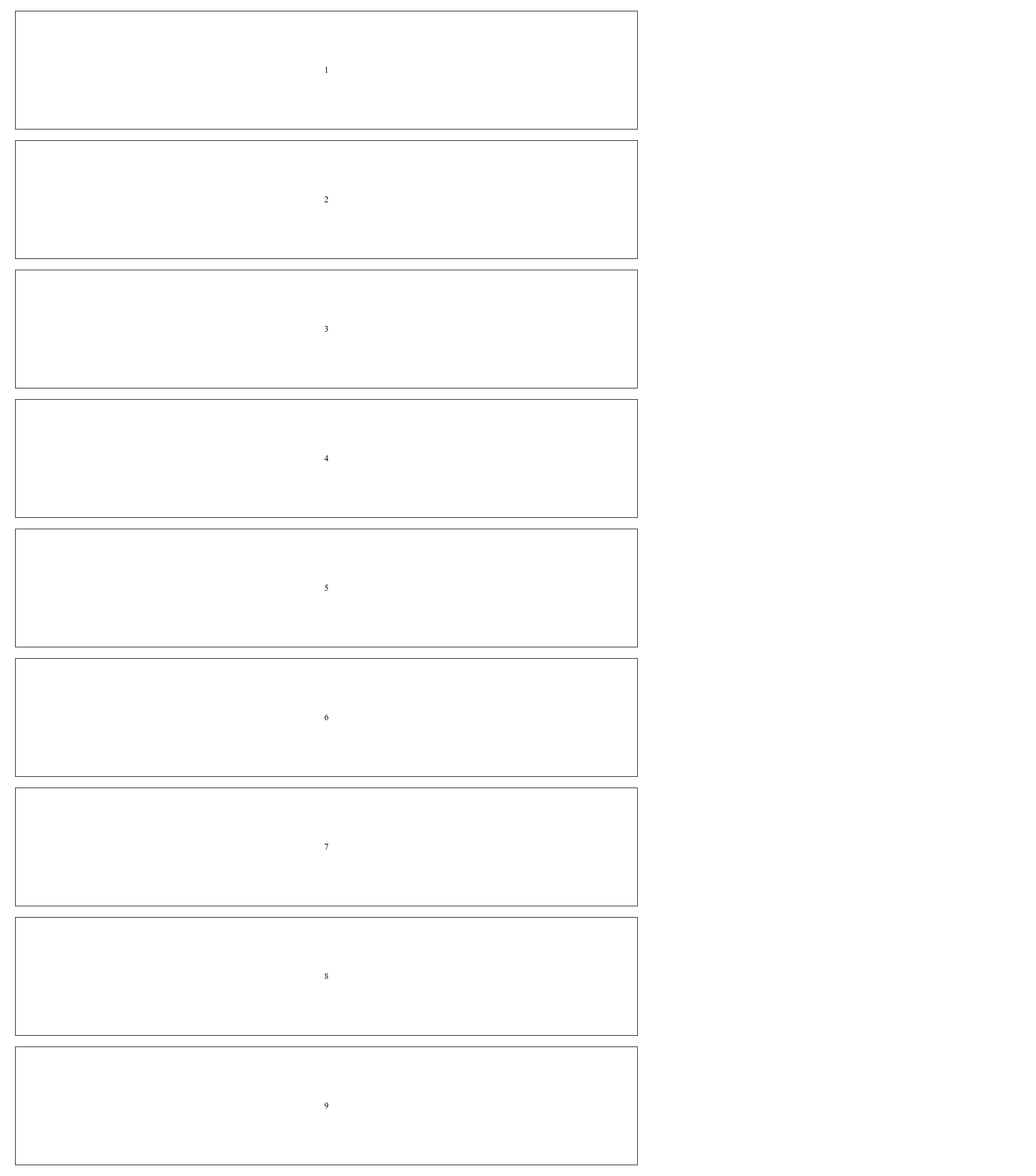
In this tutorial, we will see how we can scrape infinite scroll web pages using a js_scenario, specifically the scroll_y and scroll_x features. And we will use this page as a demo. Only 9 boxes are loaded when we first open the page, but as soon as we scroll to the end of it, we will load 9 more, and that will keep happening each time we scroll to the bottom of the page.
First let’s make a request without the scroll_y parameter and see what the result looks like. We will use this code:
using System;
using System.IO;
using System.Net;
using System.Web;
namespace test {
class test{
private static string BASE_URL = @"https://app.scrapingbee.com/api/v1/?";
private static string API_KEY = "YOUR-API-KEY";
public static string Get(string uri)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(uri);
request.AutomaticDecompression = DecompressionMethods.GZip | DecompressionMethods.Deflate;
using(HttpWebResponse response = (HttpWebResponse)request.GetResponse())
using(Stream stream = response.GetResponseStream())
using(StreamReader reader = new StreamReader(stream))
{
return reader.ReadToEnd();
}
}
public static void Main(string[] args) {
var query = HttpUtility.ParseQueryString(string.Empty);
query["api_key"] = API_KEY;
query["url"] = @"https://demo.scrapingbee.com/infinite_scroll.html";
string queryString = query.ToString(); // Transforming the URL queries to string
string output = Get(BASE_URL+queryString); // Make the request
string path = @"./InfiniteScroll_NoScroll.html"; // Output file
using (StreamWriter sw = File.CreateText(path))
{
sw.Write(output);
}
}
}
}
And the result as you will see below the first 9 pre-loaded blocks. So for websites that have infinite scroll, you will not be able to extract information efficiently without scroll_y.
The code below will scroll to the end of the page and wait for 500 milliseconds two times, then save the result in an HTML document.
using System;
using System.IO;
using System.Net;
using System.Web;
namespace test {
class test{
private static string BASE_URL = @"https://app.scrapingbee.com/api/v1/?";
private static string API_KEY = "YOUR-API-KEY";
public static string Get(string uri)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(uri);
request.AutomaticDecompression = DecompressionMethods.GZip | DecompressionMethods.Deflate;
using(HttpWebResponse response = (HttpWebResponse)request.GetResponse())
using(Stream stream = response.GetResponseStream())
using(StreamReader reader = new StreamReader(stream))
{
return reader.ReadToEnd();
}
}
public static void Main(string[] args) {
var query = HttpUtility.ParseQueryString(string.Empty);
query["api_key"] = API_KEY;
query["url"] = "https://demo.scrapingbee.com/infinite_scroll.html";
// Setting our JavaScript Scenario JSON to scroll:
query["js_scenario"] = @"{'instructions': [
{'scroll_y': 1080},
{'wait': 500},
{'scroll_y': 1080},
{'wait': 500}
]}";
Console.WriteLine(query["js_scenario"]);
string queryString = query.ToString(); // Transforming the URL queries to string
string output = Get(BASE_URL+queryString); // Make the request
string path = @"./InfiniteScroll_WithScroll.html"; // Output file
using (StreamWriter sw = File.CreateText(path))
{
sw.Write(output);
}
}
}
}
And as you can see below, we managed to scrape 18 blocks. We can even go further and scrape more blocks if wanted by adding more scroll_y instructions.
