Guide to Scraping E-commerce Websites
Scraping e-commerce websites has become increasingly important for companies to gain a competitive edge in the digital marketplace. It provides access to vast amounts of product data quickly and efficiently. These sites often feature a multitude of products, prices, and customer reviews that can be difficult to review manually. When the data extraction process is automated, businesses can save time and resources while obtaining comprehensive and up-to-date information about their competitors' offerings, pricing strategies, and customer sentiment.
Scraping e-commerce websites also provides valuable insights that may not be achieved through manual review. For instance, by analyzing and visualizing historical price data, companies can implement dynamic pricing strategies to maximize their profitability. This empowers them to make informed decisions, optimize their own product listings, and stay ahead in the highly competitive e-commerce landscape.
In this article, you will learn the following:
- Tips and best practices for scraping e-commerce websites
- Tools for scraping e-commerce websites
- How to scrape an e-commerce website using ScrapingBee
Tips and Best Practices for Scraping E-commerce Websites
Let's first go over some tips and best practices to help you get the best results and navigate potential challenges with scraping data from e-commerce websites.
Choose the Right Tool
You should choose a scraping tool that can effectively handle the complexities of the target e-commerce website, especially if it involves JavaScript-based elements or pagination. These features are common on modern e-commerce sites, and using a scraping tool that can interact with them seamlessly will ensure you collect all relevant data accurately.
Some e-commerce websites implement CAPTCHAs as a security measure that can hinder automated scraping. Additionally, e-commerce sites often undergo structural updates, which can break existing scraping scripts. Therefore, the process of selecting a scraping tool should involve evaluating its ability to handle these challenges.
Choosing the right scraping tool often requires a careful assessment of your specific needs and the tool's capabilities. While some tools offer basic scraping functionalities, more sophisticated tools and frameworks are designed to handle complex scenarios effectively. It may not always be obvious if a tool can meet your requirements, so conducting research and testing is important to discover the right tool for your requirements.
Use Reliable Selectors for Consistency
In ensuring the accuracy and reliability of your scraping process, it's important to use reliable selectors to extract data from the e-commerce website's HTML structure. Websites may also undergo frequent updates or changes to their layout, so it's good practice to review and adjust your selectors periodically to maintain data extraction consistency.
🛒 Check out our guide on How to scrape any Shopify store with our AI-powered web scraper without the need to specify any selectors.
Handling Varied Data Types
Most e-commerce websites contain different types of data, ranging from product details and customer reviews to pricing information. These data types may have distinct structures, requiring different scraping techniques. It's important to change your scraping methods to suit the specific data you're targeting. For example, scraping product details like titles and descriptions may require parsing HTML elements, while extracting pricing information, such as discounts or sale percentages, may involve navigating JavaScript-generated content and applying dynamic scraping techniques. This adaptability will allow you to accurately extract and utilize various types of data for your intended purposes.
Respect Website Policies and Terms of Service
Your scraping activities need to be respectful and ethical. Always review and stick to the e-commerce website's terms of service and other relevant policies. Overloading the site with excessive scraping requests can lead to server strain and potential legal issues. Maintaining a considerate scraping approach not only helps your scraping task last longer but also encourages a positive relationship with the website operators.
Use Data Validation and Cleaning Techniques
Scraped data may sometimes contain inconsistencies, duplicates, or irrelevant information. Use data validation techniques to confirm the data is in the expected format and values. Data cleaning methods can also remove any redundant or incorrect entries. Clean and validated data is more useful for analysis, reporting, and other downstream processes that help inform decisions.
Tools for Scraping E-commerce Websites
Numerous tools can scrape data from e-commerce websites, including open source and paid options. The following are three tools that are popular with developers.
Selenium
The Selenium Python package originated as a browser-automation framework primarily designed to automate web application testing. It was developed by Jason Huggins in 2004 and later evolved into an open source project with contributions from different developers. It's a popular tool for tasks such as web scraping, data extraction, and some browser-automation tasks (clicking buttons and filling out forms).
The package supports various web browsers, including Chrome, Firefox, Safari, and more. The WebDriver interface enables interaction with browser-specific functionalities. Selenium itself is open source, and its Python bindings are available for free. Setting up Selenium involves installing the package and the WebDriver executable for the browser you want to automate.
Selenium works well in automated test cases to ensure web applications work as expected. You can also use it to scrape data from different dynamic websites. If your automation tasks involve heavy data manipulation or high-speed interactions, a more efficient tool might be a better option.
Scrapy
Scrapy is a web crawling and web scraping framework based on Python. Shane Evans initially developed it specifically as a web scraping tool. However, it's now capable of extracting data from APIs and is also a versatile web crawler. You can use this tool for a wide range of tasks, such as data mining, data monitoring, and automated testing.
Scrapy is an open source tool, making it accessible to a wide range of users. Scrapy requires Python 3.8+ on your machine (Linux, Windows, macOS, or BSD). You can easily install the tool on your machine using the package manager for Python packages (pip).
Scrapy excels at efficiently scraping structured data, so it's a good choice if you want to target websites with consistent layouts and patterns. Scrapy's asynchronous architecture also makes it well suited for scraping a large volume of data from multiple sources.
However, Scrapy is not well equipped to handle websites that heavily rely on JavaScript-rendered content.
ScrapingBee
ScrapingBee was created by Pierre de Wulf and Kevin Sahin in 2018. It's an API-based web scraping service that can handle both headless browsers and rotate proxies when extracting data. It's useful for individuals and companies that want to utilize time-saving automation processes so they can redirect their efforts toward extracting valuable insights from the gathered data.
ScrapingBee is a paid tool, but it does offer a trial period. You need to sign up for an account to get access to the API key before you can make requests and scrape data from different websites. It supports different programming languages such as Python, Node.js, Java, Ruby, PHP, and Go.
ScrapingBee offers significant benefits when you're extracting data from a website that relies on JavaScript-based elements and rendering. Additionally, if you want to avoid request rate limits or geographical restrictions, ScrapingBee can use proxies while gathering data from specific websites.
While ScrapingBee offers various pricing tiers, depending on your usage, it's worth noting that the costs can add up, particularly for extensive or frequent scraping operations.
Using ScrapingBee to Scrape an E-Commerce Website
In this section, you'll learn how to scrape data from an e-commerce platform using the ScrapingBee API. The tool is supported by different programming languages, but this example uses its Python library to interact with ScrapingBee's API and scrape data from the e-commerce platform.
Prerequisites
Before starting the scraping task, ensure that you have Python installed on your machine, preferably Python 3.x. Additionally, make sure you have an editor such as Visual Studio Code or Jupyter Notebook to write and run the code.
Set Up ScrapingBee
You need to register on the ScrapingBee platform to access the API. Follow the registration steps to create your account.
Run the following command in your terminal to install the ScrapingBee Python SDK so you can interact with ScrapingBee's API:
pip3 install scrapingbee
You can also install the pandas Python library to clean and reformat the scraped data and finally export it into a simple CSV file for further analysis. Run the following command to install the Python package:
pip3 install pandas
Choose a Target E-commerce Website and Identify Data to Scrape
For this example, you'll scrape a simple and open source e-commerce website called Books to Scrape. The website shows a list of different book categories with information such as book title, image, URL, price, and in-stock availability. You'll use the ScrapingBee API to scrape book details and save the data into a CSV file.
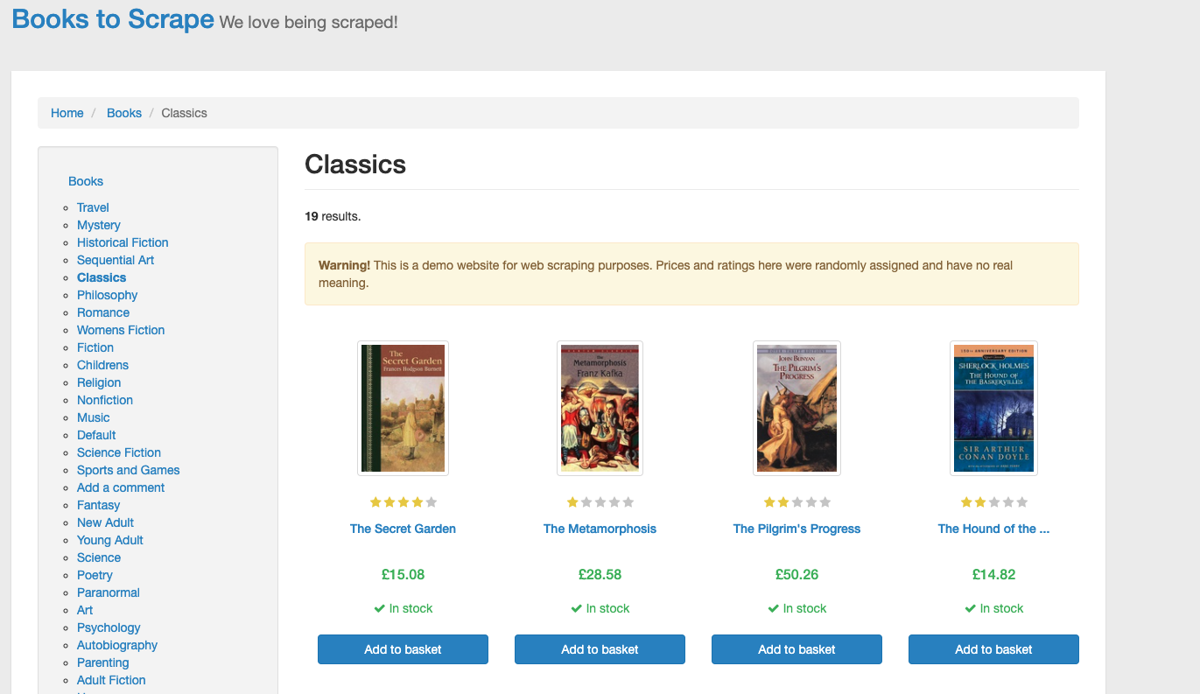
You first need to check the structure of the source code to determine which HTML elements are associated with the details of the book. Open the website in the browser, then right-click and select the Inspect option to identify the HTML element that holds the book's details.
From the browser developer tool, you can find out that each book's details are within the article HTML element, as shown in the code block below:
<article class="product_pod">
<div class="image_container">
<a href="../../../the-secret-garden_413/index.html">
<img src="../../../../media/cache/c5/46/c5465a06182ed6ebfa40d049258a2f58.jpg" alt="The Secret Garden" class="thumbnail">
</a>
</div>
<p class="star-rating Four">
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
</p>
<h3>
<a href="../../../the-secret-garden_413/index.html" title="The Secret Garden">The Secret Garden</a>
</h3>
<div class="product_price">
<p class="price_color">£15.08</p>
<p class="instock availability">
<i class="icon-ok"></i>
In stock
</p>
<form>
<button type="submit" class="btn btn-primary btn-block" data-loading-text="Adding...">Add to basket</button>
</form>
</div>
</article>
From the article HTML element, you can find all the information about the books to scrape, such as the following:
- Title or name of the book
- URL
- Image and its URL
- Price of the book
- In-stock availability
The data about each book can be easily identified and selected using CSS selectors. For example, since the price information is within the p HTML tag that has a CSS class called "price_color", then you can use p.price_color as a CSS selector to scrape the price information.
Scrape the Data
Create a Python file named scraper.py and add the following code. If you are a Jupyter Notebook user, create a file called scrapper.ipynb and open it in the Jupyter Notebook in your browser.
Add the following code to import the Python packages that you need to scrape the data and save it into a CSV file:
# import packages
import pandas as pd
from scrapingbee import ScrapingBeeClient
You'll next initialize the ScrapingBeeClient object with your API key. To access your API key, open your ScrapingBee dashboard and then copy your key:
# Initialize the client with your API Key
client = ScrapingBeeClient(
api_key=
'YOUR-API-KEY'
)
Finally, you can use the client object to send the GET request to the e-commerce website and add extraction rules to your API to extract the book data without parsing the HTML on your side:
# send request with specific parameters to scrape data
response = client.get(
"https://books.toscrape.com/catalogue/category/books/classics_6/index.html",
params={
'extract_rules': {
# extract name/ title of the book
"name": {
"selector": "div.image_container > a > img",
"output": "@alt",
"type": "list"
},
# extract the link of the book
"link": {
"selector": "div.image_container > a",
"output": "@href",
"type": "list"
},
# extract the price of the book
"price": {
"selector": "p.price_color",
"type": "list"
},
# extract stock availability of the book
"availability": {
"selector": "p.instock.availability",
"clean": True,
"type": "list"
},
# extract the image URL of the book
"image": {
"selector": "img.thumbnail",
"output": "@src",
"type": "list"
}
}
})
# print the content of the response
if response.ok:
print(response.content)
This code first sends a GET request to https://books.toscrape.com/catalogue/category/books/classics_6/index.html. This is the URL of the web page on the e-commerce website that contains the list of different classic books from which the data will be scraped.
Then, define the params dictionary that contains rules for extracting specific data from the web page using CSS selectors. This dictionary contains multiple keys, each representing a specific piece of information to extract from the web page:
"name": Specifies how to extract the book names/titles. Thediv.image_container > a > imgCSS selector targets the image element and extracts thealtattribute value, which is the book title."link": Specifies how to extract the links to the book pages. Thediv.image_container > aCSS selector targets the anchor element and extracts thehrefattribute value, which is the link to the book page."price": Specifies how to extract the book prices. Thep.price_colorCSS selector targets the paragraph element containing the price information."availability": Specifies how to extract the stock availability information. Thep.instock.availabilityCSS selector targets the paragraph element containing the availability information."image": Specifies how to extract the image URLs of the books. Theimg.thumbnailCSS selector targets the thumbnail image element and extracts thesrcattribute value.
Note: Each extraction rule has a key option called "type":"list" to return a list of all elements matching the specified CSS selector.
Finally, it shows the content of the response after scraping the data from the web page of the e-commerce website.
You can run the above code in a simple Python file or in a Jupyter notebook file. For a Python file, create a PY file (scrapper.py), add the code, and run it in the terminal.
python3 scrapper.py
For a Jupyter notebook, create an IPYNB file (scrapper.ipynb), add the code, and run it using the run button on the navigation menu.
Here is the output:
b'{"name": ["The Secret Garden", "The Metamorphosis", "The Pilgrim\'s Progress", "The Hound of the Baskervilles (Sherlock Holmes #5)", "Little Women (Little Women #1)", "Gone with the Wind", "Candide", "Animal Farm", "Wuthering Heights", "The Picture of Dorian Gray", "The Complete Stories and Poems (The Works of Edgar Allan Poe [Cameo Edition])", "Beowulf", "And Then There Were None", "The Story of Hong Gildong", "The Little Prince", "Sense and Sensibility", "Of Mice and Men", "Emma", "Alice in Wonderland (Alice\'s Adventures in Wonderland #1)"], "link": ["../../../the-secret-garden_413/index.html", "../../../the-metamorphosis_409/index.html", "../../../the-pilgrims-progress_353/index.html", "../../../the-hound-of-the-baskervilles-sherlock-holmes-5_348/index.html", "../../../little-women-little-women-1_331/index.html", "../../../gone-with-the-wind_324/index.html", "../../../candide_316/index.html", "../../../animal-farm_313/index.html", "../../../wuthering-heights_307/index.html", "../../../the-picture-of-dorian-gray_270/index.html", "../../../the-complete-stories-and-poems-the-works-of-edgar-allan-poe-cameo-edition_238/index.html", "../../../beowulf_126/index.html", "../../../and-then-there-were-none_119/index.html", "../../../the-story-of-hong-gildong_84/index.html", "../../../the-little-prince_72/index.html", "../../../sense-and-sensibility_49/index.html", "../../../of-mice-and-men_37/index.html", "../../../emma_17/index.html", "../../../alice-in-wonderland-alices-adventures-in-wonderland-1_5/index.html"], "price": ["\xc2\xa315.08", "\xc2\xa328.58", "\xc2\xa350.26", "\xc2\xa314.82", "\xc2\xa328.07", "\xc2\xa332.49", "\xc2\xa358.63", "\xc2\xa357.22", "\xc2\xa317.73", "\xc2\xa329.70", "\xc2\xa326.78", "\xc2\xa338.35", "\xc2\xa335.01", "\xc2\xa343.19", "\xc2\xa345.42", "\xc2\xa337.46", "\xc2\xa347.11", "\xc2\xa332.93", "\xc2\xa355.53"], "availability": ["In stock", "In stock", "In stock", "In stock", "In stock", "In stock", "In stock", "In stock", "In stock", "In stock", "In stock", "In stock", "In stock", "In stock", "In stock", "In stock", "In stock", "In stock", "In stock"], "image": ["../../../../media/cache/c5/46/c5465a06182ed6ebfa40d049258a2f58.jpg", "../../../../media/cache/4a/1b/4a1b6e9c1af75db0dc34ae63344f6883.jpg", "../../../../media/cache/45/bb/45bb59d19eb3aa868293d44809078418.jpg", "../../../../media/cache/1f/b0/1fb03cdabe6001c8a2620f65e025cbd5.jpg", "../../../../media/cache/81/f5/81f559ebe403317226fa8b611e35ce8a.jpg", "../../../../media/cache/27/82/2782701b5c877cb063065b9fc14c5b13.jpg", "../../../../media/cache/e3/c4/e3c4aba2409bb769a6488805e3fc4709.jpg", "../../../../media/cache/10/db/10db56354b4550d92270c6f097d9bebc.jpg", "../../../../media/cache/93/4e/934e966c1ddf559d3ac2b5c1407aaf1e.jpg", "../../../../media/cache/a6/72/a67245346daa38c2b23a4fc64c6e7115.jpg", "../../../../media/cache/42/c4/42c48f11b7e70a0f76c5ba9cb5c5018a.jpg", "../../../../media/cache/dd/6e/dd6e7b84e99f3b4b5655ea0db74af2b4.jpg", "../../../../media/cache/21/bf/21bf2eb0bff3134837def8bd40845ba0.jpg", "../../../../media/cache/ab/16/ab16eb035cc58809a73c4699477de9cb.jpg", "../../../../media/cache/c0/78/c078355608dd81c7c5e4f5e1c5f73d23.jpg", "../../../../media/cache/7d/53/7d53e2264b9647ee307259be9f73585d.jpg", "../../../../media/cache/0f/ca/0fca4597765ffacdb7bd529fc5eb88fa.jpg", "../../../../media/cache/09/63/09638baaef52f03827c215029c632a13.jpg", "../../../../media/cache/96/ee/96ee77d71a31b7694dac6855f6affe4e.jpg"]}
Reformat URLs and Save Data in a CSV file
The scraped data about books can be saved into a pandas DataFrame using the pandas Python package. Use the following code to create the pandas DataFrame from the JSON output:
# Create a DataFrame from the JSON data
data = pd.DataFrame(response.json())
# show top five rows
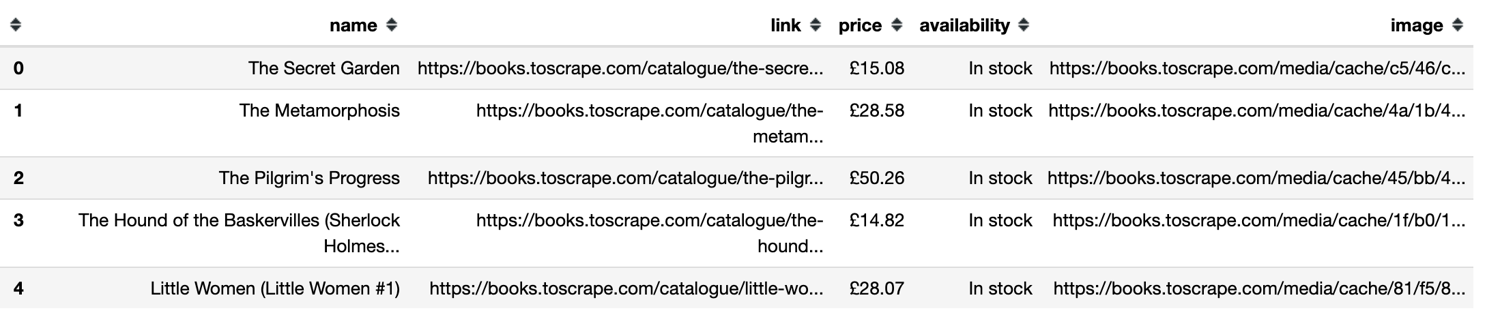
data.head()
The following screenshot shows the list of the top five rows of the scraped data.

As you can see, the formatting of the book URL and image URL could be improved as they don't start with the e-commerce URL (https://books.toscrape.com). Let's work on that. The following simple Python functions will reformat both the book URL and image URL by concatenating them with the e-commerce website URL.
# function to reformat the book link
def reformat_book_link(link):
return f"https://books.toscrape.com/catalogue{link[8:]}"
# function to reformat the image link
def reformat_image_link(link):
return f"https://books.toscrape.com{link[11:]}"
Let's apply these two functions to the data in the pandas DataFrame using the apply()method in each specified column:
# reformat the book URL
data["link"] = data["link"].apply(reformat_book_link)
# format the image URL
data["image"] = data["image"].apply(reformat_image_link)
Now, you can see the actual URL for each book and image.
Finally, you can save the scraped data into a simple CSV file using the to_csv() method from pandas.
# save to csv
data.to_csv("classics-books.csv",index=False)
The scraped data has been successfully exported to the CSV file called classics-books.csv.

Congratulations, you have successfully scraped data from an e-commerce website using ScrapingBee API and the ScrapingBee Python SDK. You can download the source code and scraped data in the GitHub repository.
Conclusion
In this article, you learned how to extract data from e-commerce websites. You also explored some best practices for scraping, including adhering to website rules, employing dependable selection methods, and maintaining a balanced request load during scraping. Finally, you saw how tools such as ScrapingBee and Selenium can significantly simplify the process, particularly for dynamic websites.
ScrapingBee is a complete web scraping solution that allows you to effortlessly scrape data from e-commerce websites without dealing with rate limits, proxies, user agents, IP blocks, and browser fingerprints. You just need to check out the no-code web scraping API and start utilizing the first 1,000 calls for free.

Davis David is a data scientist passionate about artificial intelligence, machine learning, deep learning, and software development. Davis is the co-organizer of AI meetups, workshops, and events with the goal of building a community of data scientists in Tanzania to solve local problems.


