For any project that pulls content from the web in C# and parses it to a usable format, you will most likely find the HTML Agility Pack. The Agility Pack is standard for parsing HTML content in C#, because it has several methods and properties that conveniently work with the DOM. Instead of writing your own parsing engine, the HTML Agility Pack has everything you need to find specific DOM elements, traverse through child and parent nodes, and retrieve text and properties (e.g., HREF links) within specified elements.

The first step is to install the HTML Agility Pack after you create your C# .NET project. In this example, we use a .NET Core MVC web app. To install the Agility Pack, you need to use NuGet. NuGet is available in the Visual Studio interface by going to Tools -> NuGet Package Manager -> Manage NuGet Packages for Solution. In this Window, perform a search for HTML Agility Pack, and install it into your solution dependencies. After you install it, you’ll notice the dependency in your solution, and you will find it referenced in your using statements. If you do not see the reference in your using statements, you must add the following line to every code file where you use the Agility Pack:
using HtmlAgilityPack;
Pull HTML from a Web Page Using Native C# Libraries
With the Agility Pack dependency installed, you can now practice parsing HTML. For this tutorial, we’ll use Hacker News. It’s a good example since it is a dynamic page with a list of popular links that can be read by viewers. We’ll take the top 10 links on Hacker News, parse the HTML and place it into a JSON object.
Before you scrape a page, you should understand its structure and take a look at the code behind on the page. This can be done in the browser using the “Inspect Element” option. We’re using Chrome, but this feature is available in FireFox and Edge. Right-click and inspect the element for the first link on Hacker News. You’ll notice that links are contained within a table, and each title is listed in a table row with specific class names. These class names can be used to pull content within each DOM element when you scrape the page.
The circled elements in the image above show classes that can be used to parse elements from the rest of the DOM. The title class contains the elements for the main title that displays on the page, and the rank class displays the title’s rank. The storylink and score classes also contain important information about the link that we could add to the JSON object.
We also want to target specific DOM element properties that contain information that we need. The <a> and <span> elements contain content that we want, and the Agility Pack can pull them from the DOM and display content.
Now that we understand the page DOM structure, we can write code that pulls the homepage for Hacker News. Before starting, add the following using statements to your code:
using HtmlAgilityPack;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Threading.Tasks;
using System.Net;
using System.Text;
With the using statements in place, you can write a small method that will dynamically pull any web page and load it into a variable named response. Here is an example of pulling a web page in C# using native libraries:
string fullUrl = "https://news.ycombinator.com/";
var response = CallUrl(fullUrl).Result;
private static async Task<string> CallUrl(string fullUrl)
{
HttpClient client = new HttpClient();
ServicePointManager.SecurityProtocol = SecurityProtocolType.Tls13;
client.DefaultRequestHeaders.Accept.Clear();
var response = client.GetStringAsync(fullUrl);
return await response;
}
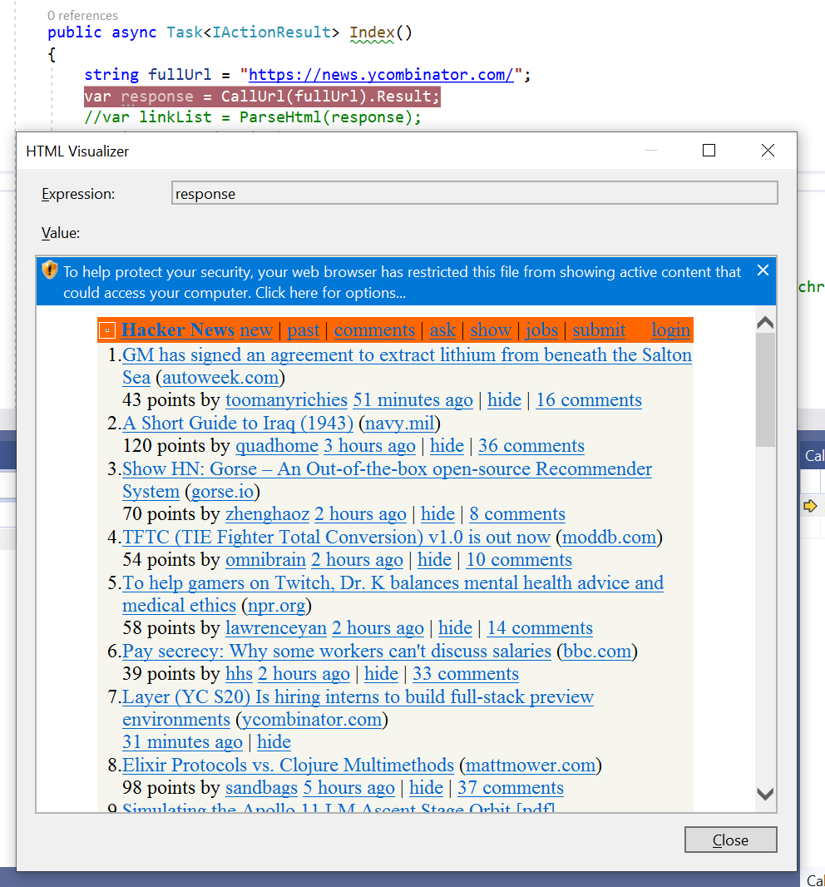
You can check to make sure that the web page content was pulled by setting a breakpoint and using the HTML Visualizer to view content:

Parsing HTML Using Agility Pack
With the HTML loaded into a variable, you can now use Agility Pack to parse it. You have two main options:
- Use XPath and SelectNodes
- Use LINQ
LINQ is useful when you want to search through nodes to find specific content. The XPath option is specific to Agility Pack and used by most developers to iterate through several elements. We’re going to use LINQ to get the top 10 stories, and then XPath to parse child elements and get specific properties for each one and load it into a JSON object. We use a JSON object, because it’s a universal language that can be used across platforms, APIs, and programming languages. Most systems support JSON, so it’s an easy way to work with external applications if you need to.
We’ll create a new method that will parse the HTML. Here is the new method with a LINQ query to pull all items with the class name “athing” and their child elements:
private void ParseHtml(string html)
{
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var programmerLinks = htmlDoc.DocumentNode.Descendants("tr")
.Where(node => node.GetAttributeValue("class", "").Contains("athing")).Take(10).ToList();
}
This code loads the HTML into the Agility Pack HtmlDocument object. Using LINQ, we pulled all tr elements where the class name contains athing. The Take() method tells the LINQ query to only take the top 10 from the list. LINQ makes it much easier to pull a specific number of elements and load them into a generic list.
We don’t want all elements within each table row, so we need to iterate through each item and use Agility Pack to pull only story titles, URLs, rank, and score. We’ll add this functionality to the ParseHtml() method since the new functionality is a part of the parsing process.
The following code displays the added functionality in a foreach loop:
private void ParseHtml(string html)
{
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var programmerLinks = htmlDoc.DocumentNode.Descendants("tr")
.Where(node => node.GetAttributeValue("class", "").Contains("athing")).Take(10).ToList();
foreach (var link in programmerLinks)
{
var rank = link.SelectSingleNode(".//span[@class='rank']").InnerText;
var storyName = link.SelectSingleNode(".//a[@class='storylink']").InnerText;
var url = link.SelectSingleNode(".//a[@class='storylink']").GetAttributeValue("href", string.Empty);
var score = link.SelectSingleNode("..//span[@class='score']").InnerText;
}
}
The above code iterates through all top 10 links on Hacker News and gets the information that we want, but it doesn’t do anything with the information. We now need to create a JSON object to contain the information. Once we have a JSON object, we can then pass it to anything we want -- another method in our code, an API on an external platform, or to another application that can ingest JSON.
The easiest way to create a JSON object is to serialize it from a class. You can create a class in the same namespace as you’ve been creating your code in the previous examples. We’ll create a class named HackerNewsItems to illustrate:

In this example, the code we’ve been creating is in the namespace ScrapingBeeScraper.Controllers. Your namespace is probably different from ours, but you can find it at the top of your file under the using statements. Create the HackerNewsItems class in the same file as you’re using for this tutorial and return to the ParseHtml() method where we’ll create the object.
Note: To use this tutorial example, you need to install the Newtonsoft.JSON dependency from NuGet. You can install it in the same way that you installed the Agility Pack. There are several other JSON libraries for serializing and deserializing objects, but the Newtonsoft library is the most popular with C# coders. After you install it, add the following using statement to your code:
using Newtonsoft.Json;
With the HackerNewsItems class created, now we can add JSON code to the parsing method to create a JSON object. Take a look at the ParseHtml() method now:
private string ParseHtml(string html)
{
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var programmerLinks = htmlDoc.DocumentNode.Descendants("tr")
.Where(node => node.GetAttributeValue("class", "").Contains("athing")).Take(10).ToList();
List<HackerNewsItems> newsLinks = new List<HackerNewsItems>();
foreach (var link in programmerLinks)
{
var rank = link.SelectSingleNode(".//span[@class='rank']").InnerText;
var storyName = link.SelectSingleNode(".//a[@class='storylink']").InnerText;
var url = link.SelectSingleNode(".//a[@class='storylink']").GetAttributeValue("href", string.Empty);
var score = link.SelectSingleNode("..//span[@class='score']").InnerText;
HackerNewsItems item = new HackerNewsItems();
item.rank = rank.ToString();
item.title = storyName.ToString();
item.url = url.ToString();
item.score = score.ToString();
newsLinks.Add(item);
}
string results = JsonConvert.SerializeObject(newsLinks);
return results;
}
Notice in the code above that the HackerNewsItems class is populated from the parsed HTML. Each HackerNewsItems object is then added to a generic list, which will contain all 10 items. The last statement before the method return statement is Newtonsoft turning the generic list into a JSON object.
That’s it -- you’ve pulled the top 10 news links from Hacker News and created a JSON object. Here is the full code from start to finish with the final JSON object contained in the linkList variable:
string fullUrl = "https://news.ycombinator.com/";
var response = CallUrl(fullUrl).Result;
var linkList = ParseHtml(response);
private static async Task<string> CallUrl(string fullUrl)
{
HttpClient client = new HttpClient();
ServicePointManager.SecurityProtocol = SecurityProtocolType.Tls13;
client.DefaultRequestHeaders.Accept.Clear();
var response = client.GetStringAsync(fullUrl);
return await response;
}
private string ParseHtml(string html)
{
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var programmerLinks = htmlDoc.DocumentNode.Descendants("tr")
.Where(node => node.GetAttributeValue("class", "").Contains("athing")).Take(10).ToList();
List<HackerNewsItems> newsLinks = new List<HackerNewsItems>();
foreach (var link in programmerLinks)
{
var rank = link.SelectSingleNode(".//span[@class='rank']").InnerText;
var storyName = link.SelectSingleNode(".//a[@class='storylink']").InnerText;
var url = link.SelectSingleNode(".//a[@class='storylink']").GetAttributeValue("href", string.Empty);
var score = link.SelectSingleNode("..//span[@class='score']").InnerText;
HackerNewsItems item = new HackerNewsItems();
item.rank = rank.ToString();
item.title = storyName.ToString();
item.url = url.ToString();
item.score = score.ToString();
newsLinks.Add(item);
}
string results = JsonConvert.SerializeObject(newsLinks);
return results;
}
Note that you can also select child nodes from parent nodes with the Agility Pack. HTML Agility Pack will traverse down the DOM hierarchy using various methods should you want to pull table elements item by item down the DOM tree.
Pull HTML Using Selenium and a Chrome Browser Instance
In some cases, you’ll need to use Selenium with a browser to pull HTML from a page. This is because some websites work with client-side code to render results. Since client-side code executes after the browser loads HTML and scripts, the previous example will not get the results that you need. To emulate code loading in a browser, you can use a library named Selenium. Selenium lets you pull HTML from a page using your browser executable, and then you can parse the HTML using the Agility Pack in the same way we did above.
Before you can parse in a browser, you need to install the Selenium.WebDriver from NuGet and add the using statements to the project. After installing Selenium, add the following using statements to your file:
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
Note: You must keep the Selenium driver updates as Chrome updates. If you receive the error “SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version xx” where “xx” is the version number for Chrome, you must update the Selenium library in your project.
We’ll use the same variables from the previous example, but change the main code to pull the HTML using Selenium and load it into an object:
string fullUrl = "https://news.ycombinator.com/";
var options = new ChromeOptions()
{
BinaryLocation = "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe"
};
options.AddArguments(new List<string>() { "headless", "disable-gpu" });
var browser = new ChromeDriver(options);
browser.Navigate().GoToUrl(fullUrl);
var linkList = ParseHtml(browser.PageSource);
Notice in the code above that the same ParseHtml() method is used, but this time we pass the Selenium page source as an argument. The BinaryLocation variable points to the Chrome executable, but your path might be different so make sure it’s an accurate path location in your own code. By reusing the same method, you can switch between direct loading of HTML using native C# libraries and loading client-side content and parsing it without writing new code for each event.
The full code to perform the request and parse HTML is below:
string fullUrl = "https://news.ycombinator.com/";
var options = new ChromeOptions()
{
BinaryLocation = "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe"
};
options.AddArguments(new List<string>() { "headless", "disable-gpu" });
var browser = new ChromeDriver(options);
browser.Navigate().GoToUrl(fullUrl);
var linkList = ParseHtml(browser.PageSource);
```c#
private string ParseHtml(string html)
{
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var programmerLinks = htmlDoc.DocumentNode.Descendants("tr")
.Where(node => node.GetAttributeValue("class", "").Contains("athing")).Take(10).ToList();
List<HackerNewsItems> newsLinks = new List<HackerNewsItems>();
foreach (var link in programmerLinks)
{
var rank = link.SelectSingleNode(".//span[@class='rank']").InnerText;
var storyName = link.SelectSingleNode(".//a[@class='storylink']").InnerText;
var url = link.SelectSingleNode(".//a[@class='storylink']").GetAttributeValue("href", string.Empty);
var score = link.SelectSingleNode("..//span[@class='score']").InnerText;
HackerNewsItems item = new HackerNewsItems();
item.rank = rank.ToString();
item.title = storyName.ToString();
item.url = url.ToString();
item.score = score.ToString();
newsLinks.Add(item);
}
string results = JsonConvert.SerializeObject(newsLinks);
return results;
}
The code still parses the HTML and converts it to a JSON object from the HackerNewsItems class, but the HTML is parsed after loading it into a virtual browser. In this example, we used headless Chrome with Selenium, but Selenium also has drivers for headless FireFox available from NuGet.
For now, we used LINQ and XPath to select CSS classes, but the Agility Pack creators promise that CSS selectors are coming.
Final Thoughts
The HTML Agility Pack is a great tool for scraping websites, but it’s lacking some key features. For example, we needed additional libraries (Selenium) to scrape single page applications made with SPA frameworks such as React.js, Angular.js or Vue.js.
XPath is also important, because this query language is much more flexible than CSS selectors. Overall, it’s a great library for parsing HTML, but you still need additional libraries for more flexibility.
Our C# examples used the Agility Pack and Selenium for single page applications, but our next article will focus on ScrapySharp. You can also read our tutorial about web scraping with C#.

Jennifer Marsh is a software developer and technology writer for a number of publications across several industries including cybersecurity, programming, DevOps, and IT operations.

